HBase內存管理之MemStore的實現(xiàn)原理和優(yōu)化
Java工程中內存管理總是一個繞不過去的知識模塊,無論HBase、Flink還是Spark等,如果使用的JVM堆比較大同時對讀寫延遲等性能有較高要求,一般都會選擇自己管理內存,而且一般都會選擇使用部分堆外內存。
HBase系統(tǒng)中有兩塊大的內存管理模塊,一塊是MemStore ,一塊是BlockCache,這兩塊內存的管理在HBase的版本迭代過程中不斷進行過各種優(yōu)化,接下來筆者結合自己的理解,將這兩個模塊的內存管理迭代過程通過幾篇文章梳理一遍,相信很多優(yōu)化方案在各個系統(tǒng)中都有,舉一反三,個人覺得對內核開發(fā)有很大的學習意義。本篇文章重點集中介紹MemStore內存管理優(yōu)化。
基于跳表實現(xiàn)的MemStore基礎模型
實現(xiàn)MemStore模型的數(shù)據(jù)結構是SkipList(跳表),跳表可以實現(xiàn)高效的查詢\插入\刪除操作,這些操作的期望復雜度都是O(logN)。另外,因為跳表本質上是由鏈表構成,所以理解和實現(xiàn)都更加簡單。這是很多KV數(shù)據(jù)庫(Redis、LevelDB等)使用跳表實現(xiàn)有序數(shù)據(jù)集合的兩個主要原因。跳表數(shù)據(jù)結構不再贅述,網(wǎng)上有比較多的介紹,可以參考。
JDK原生自帶的跳表實現(xiàn)目前只有ConcurrentSkipListMap(簡稱CSLM,注意:ConcurrentSkipListSet是基于ConcurrentSkipListMap實現(xiàn)的)。ConcurrentSkipListMap是JDK Map的一種實現(xiàn),所以本質上是一種Map,不過這個Map中的元素是有序的。這個有序的保證就是通過跳表實現(xiàn)的。ConcurrentSkipListMap的結構如下圖所示:
基于ConcurrentSkipListMap這樣的基礎數(shù)據(jù)結構,按照最簡單的思路來看,如果寫入一個KeyValue到MemStore中,肯定是如下的寫入步驟:
- 在JVM堆中為KeyValue對象申請一塊內存區(qū)域。
- 調用ConcurrentSkipListMap的put(K key, V value)方法將這個KeyValue對象作為參數(shù)傳入。
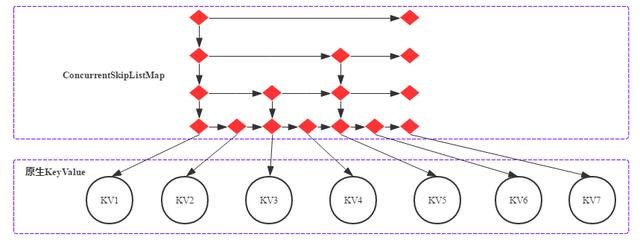
圖1 基于跳表實現(xiàn)的最基礎MemStore模型
對吧,這樣的話,實現(xiàn)非常簡單。根據(jù)Key查詢可以利用跳表的有序性。但是這樣的內存存儲模型會有很多問題(具體見下節(jié)),本文就基于這個最原始的模型開始優(yōu)化之旅。
再看圖1這個存儲模型,可以發(fā)現(xiàn)MemStore從內存管理上來說主要由兩個部分組成,一個是原生KeyValue的內存管理,見上圖下半部分;一個是ConcurrentSkipListMap的內存管理,見上圖上半部分。接下來筆者分別就這兩個部分的內存管理優(yōu)化,分成兩個小節(jié)進行深入介紹。
MemStore中原生KeyValue對象內存存儲優(yōu)化
對于HBase這樣基于LSM實現(xiàn)的MemStore來說,上述實現(xiàn)方案每寫入一個KeyValue,在沒有寫入ConcurrentSkipList之前就需要申請一個內存對象,可以想見,對于很多寫入吞吐量幾萬每秒的業(yè)務來說,每秒就會有幾萬個內存對象產(chǎn)生,這些對象會在內存中存在很長一段時間,對應的會晉升到老生代,一旦執(zhí)行了flush操作,老生代的這些對象會被GC回收掉。這樣的內存玩法,會導致JVM的GC壓力非常大。GC壓力主要來源于:這些內存對象一旦晉升到老生代,執(zhí)行完Major GC后會存在大量的非常小的內存碎片,這些內存碎片會引起頻繁的Full GC,而且每次Full GC的時間會異常的長。
- MemStore引入MemStoreLAB
針對上面的問題,MemStore借鑒TLAB(Thread Local Allocation Buffer)機制,實現(xiàn)了MemStoreLAB,簡稱MSLAB。基于MSLAB實現(xiàn)寫入的核心流程如下:
- 一個KeyValue寫入之后不再單獨為KeyValue申請內存,而是提前申請好一個2M大小的內存區(qū)域(Chunk)。
- 將寫入的KeyValue順序復制到申請的Chunk中,一旦Chunk寫滿,再申請下一個Chunk。
- 將KeyValue復制到Chunk中后,生成一個Cell對象(這個Cell對象在源碼中為ByteBufferChunkKeyValue),這個Cell對象指向Chunk中的KeyValue內存區(qū)域。
- 將這個Cell對象作為Key和Value寫入ConcurrentSkipListMap中。
- 原生的KeyValue對象寫入到Chunk之后就沒有再被引用,所以很快就會被Young GC回收掉。
基于MSLAB的MemStore可以表征為下圖:
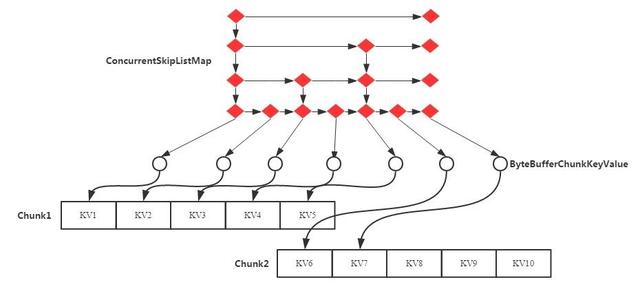
圖2 基于MSLAB實現(xiàn)的MemStore示意圖
對比圖1和圖2,引入MSLAB之后MemStore實現(xiàn)稍顯復雜,后者引入了兩個長壽內存對象,一個是2M的Chunk對象,一個是指向KV內存區(qū)域的Cell對象,這兩種內存對象都會晉升到老生代。這里分別針對這兩個內存對象進行解讀:
- 引入2M大小的Chunk對象之后,數(shù)據(jù)寫入就不再需要為每個KeyValue申請一個內存對象,這樣可以大大降低內存碎片的產(chǎn)生。
- 那Cell對象不會引起內存碎片?這個筆者查閱了很多資料都沒有找到相關的說明,個人理解是因為Cell相對原生KeyValue來說占用內存小的多,可以一定程度上可以忽略。Cell與KeyValue對象分別占用內存大小如下所示:
ByteBufferChunkKeyValue類(Cell對象)的字段如下:
- protected final ByteBuffer buf;
- protected final int offset;
- protected final int length;
- private long seqId = 0;
對象大小可以表示為對象頭和各個字段的大小總和,其中對象頭占16Byte,Reference類型占8Byte,int類型占4Byte,long類型占8Byte,Cell對象大小可以表示為:
- ClassSize.OBJECT
- + ClassSize.REFERENCE
- + (2 * Bytes.SIZEOF_INT)
- + Bytes.SIZEOF_LONG
- = 16 + 8 + 2 * 4 + 8 = 40 Byte。
原生KeyValue對象大小為:
- ClassSize.OBJECT(16)
- + Key Length(4)
- + Value Length(4)
- + Row Length(2)
- + FAMILY LENGTH(1)
- + TIMESTAMP_TYPE LENGTH(9)
- + length(row) + length(column family)
- + length(column qualifier)
- + length(value)
- =
- 36
- + length(row) + length(column family)
- + length(column qualifier) + length(value)
按照一個KV中l(wèi)ength(row) + length(column family) + length(column qualifier) + length(value)總計84Byte算,原生KeyValue對象大小為120Byte,為Cell對象的3倍。
引入MSLAB后一定程度上降低了老生代內存碎片的產(chǎn)生,進而降低了Promotion Failure類型的Full GC產(chǎn)生。那還有沒有進一步的優(yōu)化空間呢?針對Chunk,還有兩個大的優(yōu)化思路:
- MemStore引入ChunkPool
MSLAB機制中KeyValue寫入Chunk,如果Chunk寫滿了會在JVM堆內存申請一個新的Chunk。引入ChunkPool后,申請Chunk都從ChunkPool中申請,如果ChunkPool中沒有可用的空閑Chunk,才會從JVM堆內存中申請新Chunk。如果一個MemStore執(zhí)行flush操作后,這個MemStore對應的所有Chunk都可以被回收,回收后重新進入池子中,以備下次使用。基本原理如圖3、圖4所示:
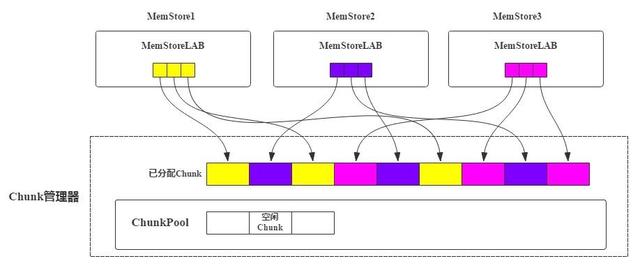
圖3 基于ChunkPool實現(xiàn)的Chunk管理模型
每個RegionServer會有一個全局的Chunk管理器,負責Chunk的生成、回收等。MemStore申請Chunk對象會發(fā)送請求讓Chunk管理器創(chuàng)建新Chunk,Chunk管理器會檢查當前是否有空閑Chunk,如果有空閑Chunk,就會將這個Chunk對象分配給MemStore,否則從JVM堆上重新申請。每個MemStore僅持有Chunk內存區(qū)域的引用,如圖3中MemStoreLAB的小格子。
下圖是MemStore執(zhí)行Flush之后,對應的所有Chunk對象中KV落盤形成HFile,這部分Chunk就可以被Chunk管理器回收到空閑池子。
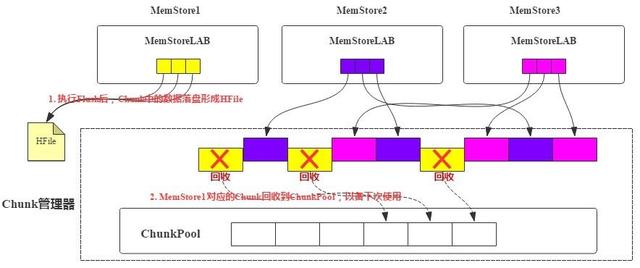
圖4 MemStore Flush過程中Chunk回收過程
使用ChunkPool的好處是什么呢?因為Chunk可以回收再使用,這就一定程度上降低了Chunk對象申請的頻率,有利于Young GC。
- MemStore Offheap實現(xiàn)
除過ChunkPool之外,HBase 2.x版本針對Chunk對象優(yōu)化的另一個思路是將Chunk使用的這部分內存堆外化。關于堆外內存的細節(jié)內容,筆者將會在下篇文章重點分析,這篇文章只做個簡單介紹。
Chunk堆外化實現(xiàn)比較簡單,在創(chuàng)建新Chunk時根據(jù)用戶配置選擇是否使用堆外內存,如果使用堆外內存,就使用JDK提供的ByteBuffer.allocateDirect方法在堆外申請?zhí)囟ù笮〉膬却鎱^(qū)域,否則使用ByteBuffer.allocate方法在堆內申請。如果不做配置,默認使用堆內內存,用戶可以設置hbase.regionserver.offheap.global.memstore.size這個值為大于0的值開啟堆外,表示RegionServer中所有MemStore可以使用的堆外內存總大小。
- 原生KeyValue對象內存存儲優(yōu)化總結
基于原生KeyValue直接寫入ConcurrentSkipListMap方案,HBase在之后的版本中不斷優(yōu)化,針對原生KeyValue內存管理部分分別采用MemStoreLAB機制、ChunkPool機制以及Chunk Offheap機制三種策略,對GC性能進行持續(xù)優(yōu)化。
第一節(jié)我們提到MemStore內存管理分為原生KeyValue內存管理和ConcurrentSkipListMap內存管理兩個部分,第二節(jié)重點介紹了HBase針對原生KeyValue內存管理所采用的3種優(yōu)化方案。接下來第三節(jié)首先介紹JDK原生ConcurrentSkipListMap在內存管理方面的主要問題,以及HBase在2.x版本以及3.x版本針對ConcurrentSkipListMap內存管理問題進行優(yōu)化的兩個方案。
ConcurrentSkipListMap數(shù)據(jù)結構存在的問題以及優(yōu)化方案
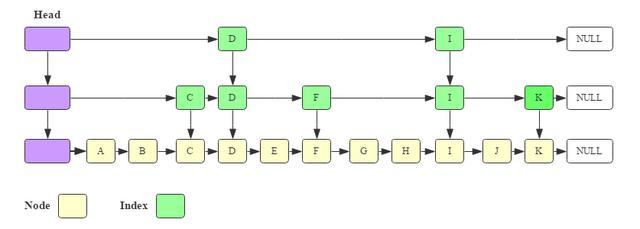
一個KV在MemStore中的旅程
經(jīng)過上面知識的鋪墊我們知道,一個KV寫入MemStore會經(jīng)過如下幾個核心步驟:
- 在Chunk中申請一段與KV相同大小的內存空間將KV拷貝進去。
- 生成一個Cell對象,該對象包含指向Chunk中對應數(shù)據(jù)塊的指針、offsize以及l(fā)ength。
- 將這個Cell對象分別作為Key和Value插入到CSLM表示的跳表Map中。
有了CSLM這樣的跳表之后,查詢就可以在O(N)時間復雜度內完成。但是,JDK實現(xiàn)的CSLM跳表在內存使用方面有些粗糙,導致內存中產(chǎn)生了大量意義不大的Java對象,這些Java對象的頻繁產(chǎn)生一方面導致內存效率使用比較低,另一方面會引起比較嚴重的Java GC。為什么JDK實現(xiàn)的CSLM跳表會有這樣的問題?接著往下看。
- MemStore ConcurrentSkipListMap數(shù)據(jù)結構存在的問題
原生ConcurrentSkipListMap邏輯示意圖如下圖所示:
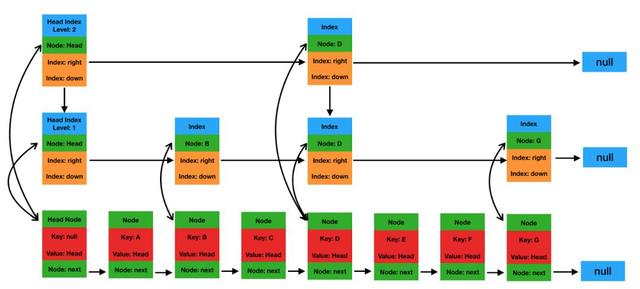
圖5 CSLM示意圖
JDK自帶的CSLM每個節(jié)點都是一個對象,其中最底層節(jié)點是Node對象,其他上層節(jié)點是Index對象。Node對象和Index對象的核心字段可以參考CSLM源碼實現(xiàn):
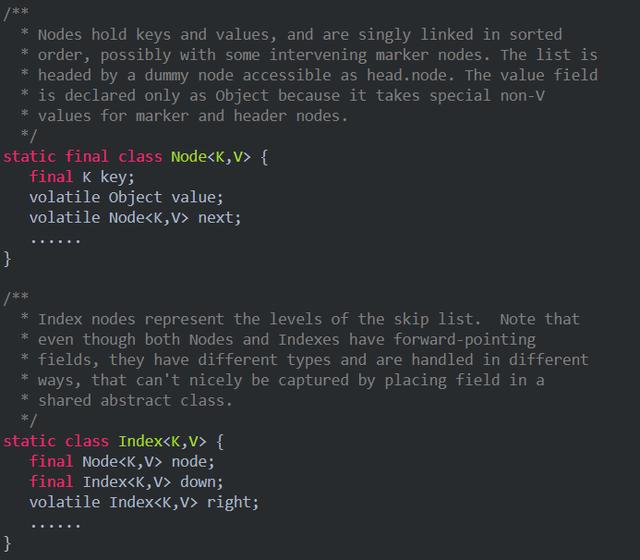
其中Node對象由一個key、一個value以及指向下一個Node節(jié)點的引用組成。Index對象由一個Node節(jié)點引用、向下和向右的引用組成。
根據(jù)上述代碼可以知道:
- 每個Node對象有3個引用變量,分別指向Key(Cell對象)、Value(Cell對象)以及Next Node。
- 每個Index對象有3個引用變量,分別指向代表的Node節(jié)點,下層Index節(jié)點以及右側Index節(jié)點。
假設業(yè)務寫入50M規(guī)模的KV,那寫入到MemStore后,除了正常存儲KV數(shù)據(jù)占用的Chunk對象外,CSLM占用的對象和內存分別有多少呢?
對象數(shù):50M個Node對象,假如跳表中l(wèi)evel N層的Index節(jié)點個數(shù)是50M/2^(N+2),那么總共會有50M/4個Index對象。整個CSLM一共有62.5M個對象。
內存占用情況(均認為JVM設置大于32G,未開啟壓縮指針):
(1)Node對象
- 50M * (ClassSize.OBJECT + ClassSize.REFERENCE + ClassSize.REFERENCE + ClassSize.REFERENCE) =50M * (16 + 8 + 8 + 8) = 2000M
(2)Index對象
- 12.5M * (ClassSize.OBJECT + ClassSize.REFERENCE + ClassSize.REFERENCE + ClassSize.REFERENCE) =12.5M * (16 + 8 + 8 + 8) = 500M
總內存占用2500M。假設業(yè)務寫入的KV為50Byte,那總的數(shù)據(jù)量為2500M。為了存儲這2500M大小的數(shù)據(jù),MemStore又產(chǎn)生了額外的2500M內存。
- CompactingMemStore如何優(yōu)化這個困境
CompactingMemStore的核心工作原理如圖所示:
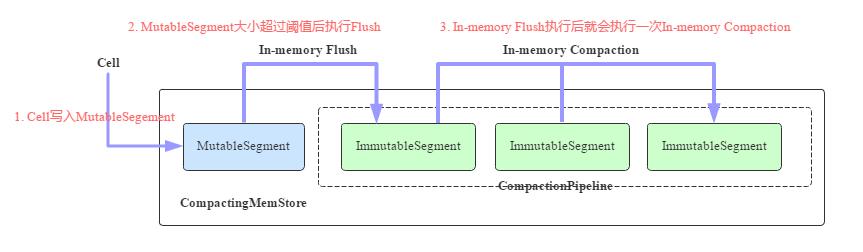
圖6 CompactingMemStore核心工作原理示意圖
- 一個Cell寫入到Region后會先寫入MutableSegment中。MutableSegment可以認為就是一個小的MemStore,MutableSegment包含一個MSLAB存儲Chunk,同時包含一個ConcurrentSkipListMap。
- 默認情況下一旦MutableSegment的大小超過2M,就會執(zhí)行In-memory Flush操作,將MutableSegment變?yōu)镮mmutableSegment,并重新生成一個新的MutableSegment接收寫入。ImmutableSegment有多個實現(xiàn)類,In-memory Flush生成的ImmutableSegment為CSLMImmutableSegment,可以預見這個ImmutableSegment在數(shù)據(jù)結構上也是使用CSLM。
- 每次執(zhí)行完In-memory Flush之后,RegionServer都會啟動一個異步線程執(zhí)行In-memory Compaction。In-memory Compaction的本質是將CSLMImmutableSegment變?yōu)镃ellArrayImmutableSegment或者CellChunkImmutableSegment,這才是CompactingMemStore最核心的地方。那什么是CellArrayImmutableSegment/CellChunkImmutableSegment呢?為什么要做這樣的轉換?接著往下看。
- In-memory Compaction機制
現(xiàn)在我們需要回過頭來想想這兩個問題:
- 為什么要將一個大的MemStore切分成這么多小的Segment?這么設計的初衷是為In-memory Compaction做準備,只有將MemStore分為MutableSegment和ImmutableSegment,才可能基于ImmutableSegment進行內存優(yōu)化。
- 如何對ImmutableSegment進行內存優(yōu)化?答案是將CSLMImmutableSegment變?yōu)镃ellArrayImmutableSegment或者CellChunkImmutableSegment。通過上文的介紹我們知道,CSLM這種數(shù)據(jù)結構對內存并不友好,因為ImmutableSegment本身已經(jīng)不再接收任何更新刪除寫入操作,只允許讀操作,這樣的話CSLM就可以轉換為對內存更加友好的Array或者其他的數(shù)據(jù)結構。這個轉換就是In-memory Compaction。
理清楚上面兩個問題,我們再來看看In-memory Compaction的主要流程。如果參與Compaction的Segment只有一個,我們稱之為Flatten,非常形象,就是將CSLM拉平為Array或者Chunk,示意圖如下圖圖7所示。
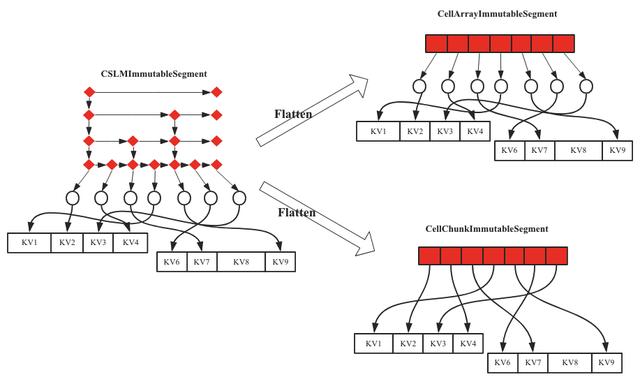
圖7 In-Memory Compaction之Flatten示意圖
緊接著就有兩個問題:
- CSLMImmutableSegment是如何拉平成CellArrayImmutableSegment?
- CellArrayImmutableSegment和CellChunkImmutableSegment分別是什么樣的數(shù)據(jù)結構?
CSLMImmutableSegment拉平成CellArrayImmutableSegment比較容易理解,順序遍歷CSLMImmutableSegment讀取出對應的Cell,順序寫入一個申請好的數(shù)組即可。所以直觀上看,CSLMImmutableSegment和CellArrayImmutableSegment相比就是將CSLM變成了一個數(shù)組。
那CellArrayImmutableSegment能不能進一步優(yōu)化呢?是不是可以將Array[Cell]這樣一個在內存中不完全連續(xù)的對象轉變成一塊完全連續(xù)內容空間的對象,這種優(yōu)化方式也比較自然,借鑒Chunk思路申請一塊2M的大內存空間,遍歷數(shù)組中的Cell對象,將其順序拷貝到這個Chunk(這種Chunk稱為Index Chunk,區(qū)別與存儲KV數(shù)據(jù)的Data Chunk)中,就變成了CellChunkImmutableSegment,將內存由不連續(xù)變?yōu)檫B續(xù)的一大好處就是變換后連續(xù)的內存區(qū)域可以在堆外管理,默認情況下In-memory Compaction會直接將CSLMImmutableSegment拉平成CellChunkImmutableSegment。
上述過程是只有一個Segment參與Compaction的流程。如果參與Compaction的Segment個數(shù)超過1個,會有兩種Compaction的形式:Merge和Compact。先說Merge,Merge的處理流程和Flatten基本一致,如In-Memory Compaction之Merge示意圖所示,左側兩個Segment進行合并形成右側一個大的CellChunkImmutableSegment,合并過程就是順序遍歷左邊兩個Segment,取出對應的Cell,然后順序寫入右邊CellChunkImmutableSegment中。
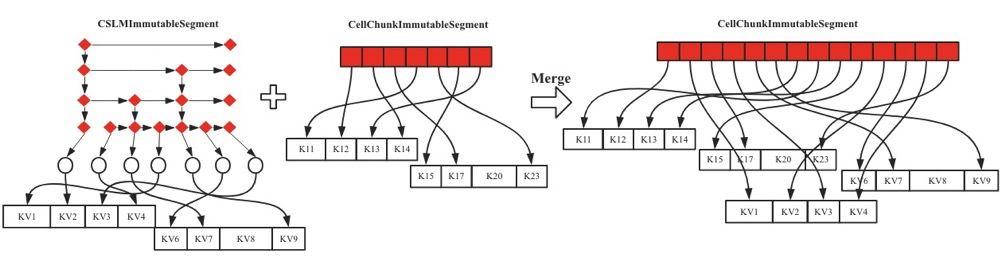
圖8 In-Memory Compaction之Merge示意圖
Compaction與Merge的處理流程基本相同,不同的是,Compaction在合并的過程中順序遍歷左邊兩個Segment,讀取對應Cell之后會檢測是否有多個版本的Cell,如果存在超過設置版本數(shù)的Cell,就將老版本的Cell刪掉。因為存在原始KV的變更,所以新生成的Data Chunk會進行重建,這是和Merge最大的不同。如In-Memory Compaction之Compaction示意圖所示,右側新生成的CellChunkImmutableSegment的Data Chunk是經(jīng)過重建過的。
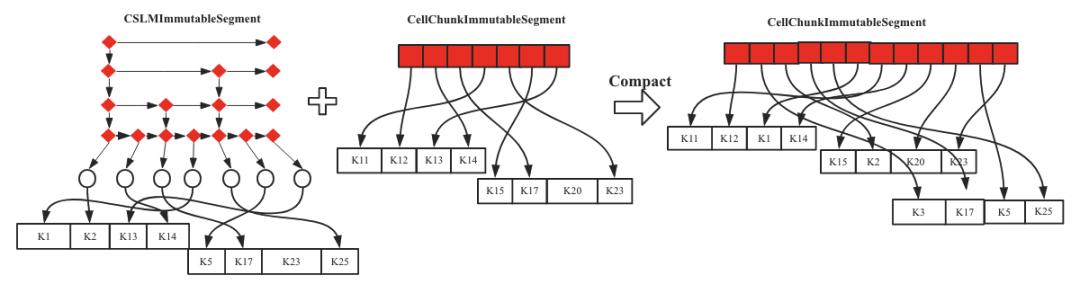
圖9 In-Memory Compaction之Compaction示意圖
CompactingMemStore通過將CSLM數(shù)據(jù)結構變成Array或者Chunk,優(yōu)化了CSLM數(shù)據(jù)結構本身內存利用效率低的問題,提升GC效率。另外,提升內存利用率可以使MemStore中存儲下更多的KV數(shù)據(jù),進而減少Flush和Compaction發(fā)生的頻率,提升整個HBase集群的性能。
CCSMap又是如何優(yōu)化CSLM?
CCSMap全稱CompactedConcurrentSkipListMap,是阿里巴巴內部版本為了優(yōu)化CSLM數(shù)據(jù)結構內存利用效率低所實現(xiàn)的一個新的數(shù)據(jù)結構。CCSMap數(shù)據(jù)結構的基本理念是將原生的ConcurrentSkipListMap進行壓縮,壓縮的直觀效果如下圖所示:
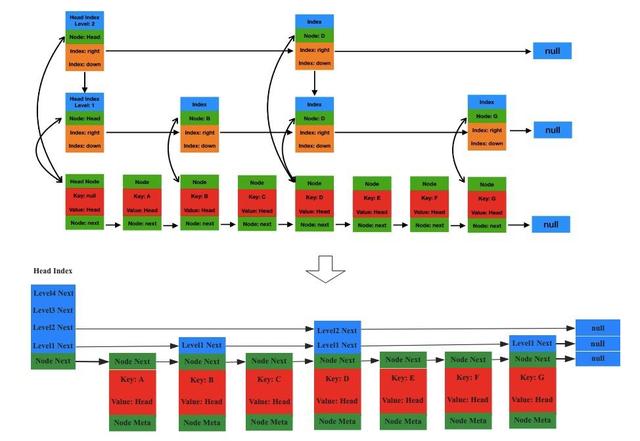
圖10 CCSMap數(shù)據(jù)結構邏輯示意圖
上圖中上面結構是原生的CSLM數(shù)據(jù)結構,下面是CCSMap數(shù)據(jù)結構,很明顯,主要是將Index對象壓縮到了Node對象上,數(shù)據(jù)寫入/讀取流程和CSLM基本上一致。壓縮后可以抹掉Index對象,但是這樣的優(yōu)化顯然不是全部。接下來的優(yōu)化才是重點。
CCSMap數(shù)據(jù)結構可以認為只有一個Node對象(Index可以理解為Node對象的一個字段),既然只有一種對象,是否可以借鑒MSLAB的思路將Node對象順序存儲到固定大小的Chunk中,這樣做的好處顯而易見:整個Chunk可以以大塊申請,同時可以在堆外申請。CCSMap就是基于這個思路進行的物理存儲設計,筆者根據(jù)相關Jira上給出的資料以及閱讀源代碼畫出來的一個物理存儲示意圖:
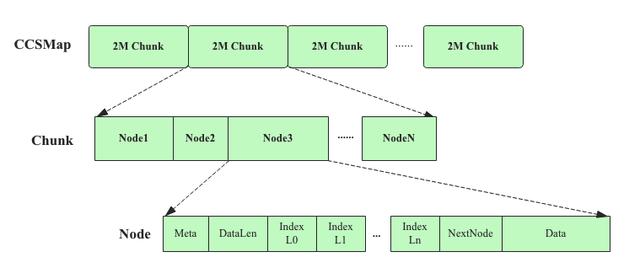
圖11 CCSMap數(shù)據(jù)結構物理實現(xiàn)示意圖
這里有個認知的轉換,在CSLM數(shù)據(jù)結構下,KV就是KV,但是在CCSMap數(shù)據(jù)結構下,KV需要包裝成Node對象,Node對象的核心字段如下:
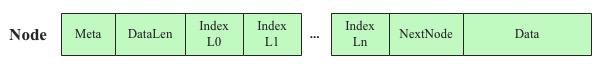
Node對象除了正常的KV Data之外,還有幾個比較重要的字段,meta字段主要存儲level,dataLen存儲數(shù)據(jù)大小,nextNode存儲當前節(jié)點的后繼節(jié)點,levelIndex是一個數(shù)組,表示這個Node在各個Level上Index指向的Node(NodeId)。這樣一個Node對象就可以完全表征邏輯示意圖中Node節(jié)點。
當然在具體實現(xiàn)中如何根據(jù)Index存儲的一個long類型的NodeId在CCSMap中找到對應的Node,這里面有個小小的技巧,就是這個long類型的NodeId前4Byte表示ChunkId,后4Byte表示對應Node在指定Chunk上的偏移量,這樣就可以根據(jù)NodeId輕松讀取到這個Node對應的內存空間。
根據(jù)物理存儲示意圖,KV數(shù)據(jù)寫入的時候會首先包裝成一個Node對象,包裝的過程主要是生成level字段,然后根據(jù)跳表規(guī)則不斷查找,確定對應的nextNode和levelIndex[]兩個字段。Node對象封裝好之后就可以順序持久化到Chunk中。
CCSMap相比CSLM可以節(jié)省多少對象?多少內存?
- 減少多少對象?CCSMap將ConcurrentSkipListMap和KV對象一起放到Chunk中去了,所以沒有任何對象開銷,這點比原生的CSLM優(yōu)秀了非常多。
- 減少了多少內存?還是假設業(yè)務寫入50M規(guī)模的KV,CCSMap中Node對象中l(wèi)ong[] levelIndex會占用12.5M * 8Byte = 100M,另外,dataLen占用4Byte,nextNode占用8Byte,meta占用4Byte,總共占用50 * 16Byte = 800M。所以總計占用900M。相比CSLM的2500M,降低了64%。
MemStore內存進化總結
基于上述長篇大論,我們知道MemStore的內存主要分為兩部分,其中一部分是KV存儲本身,一部分是CSLM。文中第二節(jié)重點介紹了KV存儲本身的幾個優(yōu)化思路,包括MSLAB、ChunkPool以及Chunk Offheap等,第三節(jié)分別重點介紹了使用CompactingMemStore和CCSMap兩種機制對CSLM數(shù)據(jù)結構進行優(yōu)化的原理。其實,優(yōu)化來優(yōu)化去,最核心的落腳點還是能不能將對象順序持久化到連續(xù)一段內存(Chunk)上,抓住這個最終落腳點非常重要。
最后說點題外話,前一段時間JDK13發(fā)布,進一步增強了ZGC特性。ZGC應該是Java歷史上最大的改進之一,這點應該沒有任何疑問,TB級別的堆可以保證GC時間低于10ms,實際場景中128G內存最大GC時間才1.68ms。如果真是這樣的GC性能,可能很多現(xiàn)在我們做的各種內存管理優(yōu)化在很多年之后都不再是問題。