













分布式入門,怎樣用PyTorch實現多GPU分布式訓練
具體來講,本文首先介紹了分布式計算的基本概念,以及分布式計算如何用于深度學習。然后,列舉了配置處理分布式應用的環境的標準需求(硬件和軟件)。***,為了提供親身實踐的經驗,本文從理論角度和實現的角度演示了一個用于訓練深度學習模型的分布式算法(同步隨機梯度下降,synchronous SGD)。
何為分布式計算
分布式計算指的是一種編寫程序的方式,它利用網絡中多個連接的不同組件。通常,大規模計算通過以這種方式布置計算機來實現,這些計算機能夠并行地處理高密度的數值運算。在分布式計算的術語中,這些計算機通常被稱為節點(node),這些節點的集合就是集群。這些節點一般是通過以太網連接的,但是其他的高帶寬網絡也可以利用分布式架構的優勢。
深度學習如何從分布式計算中受益?
作為深度學習的主力,神經網絡出現在文獻中已經有一段時間了,但是直到最近,才有人完全利用它的潛力。神經網絡異軍突起的主要原因之一就是巨大的算力,這正是我們在本文中要寫的內容。深度學習需要基于大量數據訓練深度神經網絡,它包含大量的參數。分布式計算是能夠充分利用現代硬件的***工具。下面是它的核心思想:
精心設計的分布式算法可以做到:
- 為了連貫處理,在多個節點上「分配」計算(深度學習模型中的前向傳播和反向傳播)和數據。
- 為了實現一致性,它能夠在多個節點上建立一種有效的「同步」。
MPI:分布式計算標準
你還必須習慣另一個術語——消息傳遞接口(MPI)。MPI 幾乎是所有分布式計算的主力。MPI 是一個開放標準,它定義了一系列關于節點互相通信的規則,MPI 也是一個編程模型/API。MPI 不是一款軟件或者工具,它是一種規范。
1991 年夏天,一批來自學術界和產業界的組織和個人聚在一起,最終創建了 MPI 論壇(MPI Forum)。該論壇達成了一個共識,為一個庫起草了語法和語義規范,為不同硬件提供商提出可移植/靈活/優化的實現提供指導。多家硬件提供商都有自己的 MPI 實現——OpenMPI、MPICH、MVAPICH、Intel MPI 等。
在這份教程中,我們將會使用 Intel MPI,因為它十分高效,而且也針對 Intel 平臺做了優化。原始的 Intel MPI 是一個 C 語言庫,并且級別非常低。
配置
對分布式系統而言,合適的配置是非常重要的。如果沒有合適的硬件和網絡布置,即使你對它的編程模型有著概念上的理解,也是沒多大用的。下面是需要做的關鍵布置:
- 通常需要由一系列通過通用網絡互聯形成集群的節點。推薦使用高端服務器作為節點,以及高帶寬的網絡,例如 InfiniBand。
- 集群中的所有節點都需要具有完全相同用戶名的 Linux 系統。
- 節點之間必須擁有無密碼 SSH 連接,這對無縫連接至關重要。
- 必須安裝一種 MPI 實現。本文只聚焦于 Intel MPI。
- 需要一個共同的文件系統,它對所有的節點都是可見的,而且分布式應用必須駐留在上面。網絡文件系統(NFS,Network Filesystem)是實現此目的一種方式。
并行策略的類型
并行深度學習模型有兩種流行的方式:
- 模型并行
- 數據并行
1. 模型并行
模型并行指的是一個模型從邏輯上被分成了幾個部分(例如,一些層在一部分,其他層在另一部分),然后把它們部署在不同的硬件/設備上。
盡管從執行時間上來看,將模型的不同部分部署在不同設備上確實有好處,但是它通常是出于避免內存限制才使用。具有特別多參數的模型會受益于這種并行策略,因為這類模型需要很高的內存占用,很難適應到單個系統。
2. 數據并行
另一方面,數據并行指的是,通過位于不同硬件/設備上的同一個網絡的多個副本來處理數據的不同批(batch)。不同于模型并行,每個副本可能是整個網絡,而不僅僅是一部分。
正如你可能猜到的,這種策略隨著數據的增長可以很好地擴展。但是,由于整個網絡必須部署在一個設備上,因此可能無法幫助到具有高內存占用的模型。下圖應該可以說清楚這個問題。
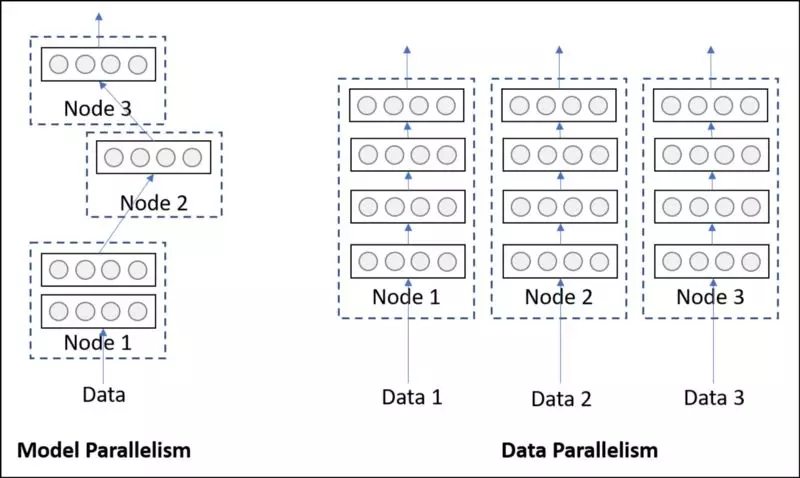
模型并行 VS 數據并行
實際上,在大組織里,為了執行生產質量的深度學習訓練算法,數據并行更加流行也更加常用。所以,本教程主要介紹數據并行。
torch.distributed API
PyTorch提供了一個非常優雅并且易于使用的 API,作為用 C 語言寫的底層 MPI 庫的接口。PyTorch 需要從源碼編譯,并且必須與安裝在系統中的 Intel MPI 進行鏈接。我們現在就看一下 torch.distributed 的基本用法,以及如何執行它。
- # filename 'ptdist.py'
- import torch
- import torch.distributed as dist
- def main(rank, world):
- if rank == 0:
- x = torch.tensor([1., -1.]) # Tensor of interest
- dist.send(x, dst=1)
- print('Rank-0 has sent the following tensor to Rank-1')
- print(x)
- else:
- z = torch.tensor([0., 0.]) # A holder for recieving the tensor
- dist.recv(z, src=0)
- print('Rank-1 has recieved the following tensor from Rank-0')
- print(z)
- if __name__ == '__main__':
- dist.init_process_group(backend='mpi')
- main(dist.get_rank(), dist.get_world_size())
點對點通信
用 mpiexec 執行上面的代碼,能夠得到一個分布式進程調度器,基于任何標準 MPI 實現都可以,結果如下:
- cluster@miriad2a:~/nfs$ mpiexec -n 2 -ppn 1 -hosts miriad2a,miriad2b python ptdist.py
- Rank-0 has sent the following tensor to Rank-1
- tensor([ 1., -1.])
- Rank-1 has recieved the following tensor from Rank-0
- tensor([ 1., -1.])
- ***行要被執行的是 dist.init_process_group(backend),它基本上設置了參與節點之間的內部通信通道。它使用了一個參數來指定使用哪個后端(backend)。因為我們完全使用 MPI,所以在我們的例子中 backend='mpi'。也有其他的后端(例如 TCP、Gloo、NCCL)。
- 需要檢索的兩個參數——world size 和 rank。World 指的是在特定 mpiexec 調用環境中所有節點的集合(參見 mpiexec 中的 -hosts flag)。rank 是由 MPI 運行時為每一個進程分配的唯一整數。它從 0 開始。它們在 -hosts 中被指定的順序用于分配數值。所以,在這個例子中,節點「miriad2a」上的進程會被賦值 Rank 0,節點「miriad2b」上的進程會被賦值為 Rank 1.
- x 是 Rank 0 打算發送到 Rank 1 的張量,通過 dist.send(x, dst=1) 完成。
- z 是 Rank 1 在接收到張量之前就創建的東西。我們需要一個早就創建好的同維度的張量作為接收傳送來的張量的占位符。z 的值最終會被 x 替代。
- 與 dist.send(..) 類似,負責接收的對應函數是 dist.recv(z, src=0),它將張量接收到 z。
通信集體
我們在上一部分看到的是一個「點對點」通信的例子,在給定的環境中,rank(s) 將數據發送到特定的 rank(s)。盡管這種通信是有用的,因為它對通信提供了細粒度的控制,但是還有其他被經常使用的標準通信模式,叫作集體(collectives)。下面介紹了 Synchronous SGD 算法中我們感興趣的一個集體——all-reduce 集體。
1. ALL-REDUCE 集體
All-reduce 是一種同步通信方式,所有的 ranks 都被執行了一個 reduction 運算,并且得到的結果對所有的 ranks 都是可見的。下圖介紹了這個思想(將求和作為 reduction 運算)。
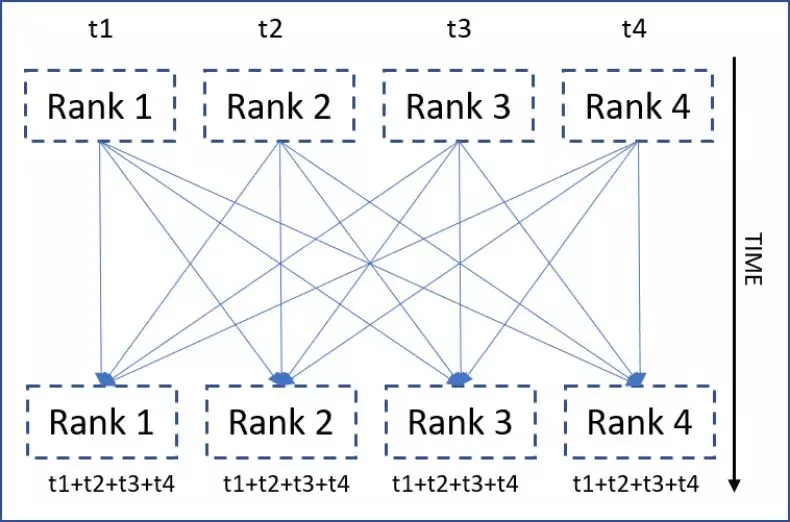
all-reduce 集體
- def main(rank, world):
- if rank == 0:
- x = torch.tensor([1.])
- elif rank == 1:
- x = torch.tensor([2.])
- elif rank == 2:
- x = torch.tensor([-3.])
- dist.all_reduce(x, op=dist.reduce_op.SUM)
- print('Rank {} has {}'.format(rank, x))
- if __name__ == '__main__':
- dist.init_process_group(backend='mpi')
- main(dist.get_rank(), dist.get_world_size())
PyTorch 中 all-reduce 集體的基本用法
在 world of 3 環境中啟動時,結果如下:
- cluster@miriad2a:~/nfs$ mpiexec -n 3 -ppn 1 -hosts miriad2a,miriad2b,miriad2c python ptdist.py
- Rank 1 has tensor([0.])
- Rank 0 has tensor([0.])
- Rank 2 has tensor([0.])
- if rank ==
… elif 是我們在分布式計算中多次遇到的模式。在這個例子中,它被用來在不同的 rank 上創建張量。 - 它們一起執行了 all-reduce(可以看見,dist.all_reduce(..) 在 if … elif block 邏輯塊的外部),求和 (dist.reduce_op.SUM) 作為 reduction 運算。
- 將來自每個 rank 的 x 求和,再把得到的求和結果放置在每個 rank 的 x 內。
轉向深度學習
假設讀者熟知標準的隨機梯度下降算法(SGD),該算法常用于訓練深度學習模型。我們現在看到的是 SGD 的一個變體——同步 SGD(synchronous SGD),它利用 all-reduce collective 來進行擴展。我們先從標準 SGD 的數學公式開始吧。

其中 D 是一個樣本集合(mini-batch),θ 是所有參數的集合,λ 是學習率,Loss(X, y) 是某個損失函數在 D 中所有樣本上的均值。
同步 SGD 所依賴的核心技巧是將更新規則中的求和在更小的 (mini)batch 子集上進行分割。D 被分割成 R 個子集 D₁, D₂, . .(推薦每個子集具有相同數量的樣本),所以 將標準的 SGD 更新公式中的求和進行分割,得到:
將標準的 SGD 更新公式中的求和進行分割,得到:
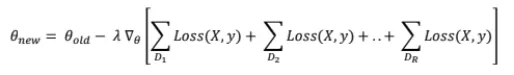
現在,因為梯度算子在求和算子上是分布式的,所以我們得到:
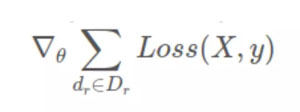
我們從中得到了什么?
看一下上面方程中單獨的梯度項(方括號里面)。它們現在可以被獨立地計算,然后加起來得到原始的梯度,而且沒有任何損失/近似。這就是數據并行。下面是整個過程:
- 將整個數據集分成 R 個等大的數據塊(子集)。這里的字母 R 代表的是 replica(副本)。
- 使用 MPI 啟動 R 個進程/rank,將每個進程綁定到一個數據塊上。
- 讓每個 rank 使用大小為 B 的 mini-batch(dᵣ)(dᵣ來自該 rank 分配到的數據塊 D_r)計算梯度,即 rank r 計算
 。
。 - 將所有 rank 的梯度進行求和,然后將得到的梯度對每個 rank 可見,再進行進一步處理。
***一點就是 all-reduce 算法。所以,每次在所有 rank 使用大小為 B 的 mini-batch(dᵣ)計算完梯度以后,都必須執行 all-reduce。需要注意的一點是,將全部 R 個 rank(使用大小為 B 的 mini-batch 計算出)的梯度相加之后會得到一個有效的批大小:
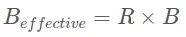
下面是實現的關鍵部分(沒有展示樣板代碼):
- model = LeNet()
- # first synchronization of initial weights
- sync_initial_weights(model, rank, world_size)
- optimoptimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.85)
- model.train()
- for epoch in range(1, epochs + 1):
- for data, target in train_loader:
- optimizer.zero_grad()
- output = model(data)
- loss = F.nll_loss(output, target)
- loss.backward()
- # The all-reduce on gradients
- sync_gradients(model, rank, world_size)
- optimizer.step()
- def sync_initial_weights(model, rank, world_size):
- for param in model.parameters():
- if rank == 0:
- # Rank 0 is sending it's own weight
- # to all it's siblings (1 to world_size)
- for sibling in range(1, world_size):
- dist.send(param.data, dst=sibling)
- else:
- # Siblings must recieve the parameters
- dist.recv(param.data, src=0)
- def sync_gradients(model, rank, world_size):
- for param in model.parameters():
- dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM)
- 全部 R 個 rank 都使用隨機權重創建自己的模型副本。
- 單個具有隨機權重的副本可能導致在初始的時候不同步。推薦在所有的副本上同步初始權重,sync_initial_weights(..) 就是在做這件事。讓任何一個 rank 將自己的權重發送到它的兄弟 rank,兄弟 rank 必須接收這些權重并用來初始化它們自身。
- 從每個 rank 對應的數據部分取出一個 mini-batch(大小為 B),計算前向和反向傳遞(梯度)。作為配置的一部分,這里需要重點注意的一點是:所有的進程/rank 應該讓自己那部分數據可見(通常是在自己的硬盤上或者在共享文件系統中)。
- 把求和作為 reduction 運算,對每一個副本上的梯度執行 all-reduce 集體。sync_gradients(..) 會完成梯度同步。
- 梯度同步之后,每個副本能夠在自己的權重上獨立地執行標準的 SGD 更新。optimizer.step() 正常運行。
現在問題來了:我們如何確保獨立的更新保持同步?
我們看一下更新方程的***更新:
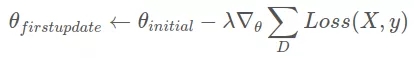
上面的第 2 點和第 4 點保證每個初始權重和梯度都是同步的。顯然,它們的線性組合也是同步的(λ 是常數)。以后的所有更新都是類似的邏輯,因此也是同步的。
性能對比
所有分布式算法的***瓶頸就是同步。只有當同步時間顯著小于計算時間的時候,分布式算法才是有益的。讓我們在標準 SGD 和同步 SGD 之間做一個簡單的對比,來看一下什么時候后者是比較好的。
定義:我們假設整個數據集的規模為 N。網絡處理大小為 B 的 mini-batch 需要花費時間 Tcomp。在分布式情況下,all-reduce 同步花費的時間為 Tsync。
對于非分布式(標準)SGD,每個 epoch 花費的時間為:
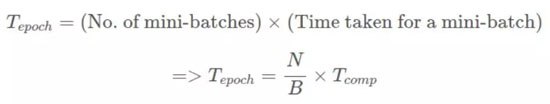
對于同步 SGD,每個 epoch 花費的時間為:

因此,對于分布式環境,為了與非分布式環境相比有顯著的優勢,我們需要滿足:

我們可以調整影響上述不等式的三個因子,從分布式算法中得到更多的好處。
- 通過以高帶寬的快速網絡連接節點,來減小 Tsync。
- 通過增加批大小 B,來增加 Tcomp。
- 通過連接更多的節點和擁有更多的副本來增加 R。
本文清晰地介紹了深度學習環境中的分布式計算的核心思想。盡管同步 SGD 很流行,但是也有其他被頻繁使用的分布式算法(如異步 SGD 及其變體)。然而,更重要的是能夠以并行的方式來思考深度學習方法。請注意,不是所有的算法都可以開箱即用地并行化,有的需要做一些近似處理,這破壞了原算法給出的理論保證。能否高效處理這些近似,取決于算法的設計者和實現者。
原文地址:
https://medium.com/intel-student-ambassadors/distributed-training-of-deep-learning-models-with-pytorch-1123fa538848
【本文是51CTO專欄機構“機器之心”的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】






















