













RocketMQ如何應對每天1500億條的數據處理?
同程藝龍的機票、火車票、汽車票、酒店相關業務已經接入了 RocketMQ,用于流量高峰時候的削峰,以減少后端的壓力。
同時,對常規的系統進行解耦,將一些同步處理改成異步處理,每天處理的數據達 1500 億條。
在近期的 Apache RocketMQ Meetup 上,同程藝龍機票事業部架構師查江,分享了同程藝龍的消息系統如何應對每天 1500 億條的數據處理。
通過此文,您將了解到:
- 同程藝龍消息系統的使用情況
- 同程藝龍消息系統的應用場景
- 技術上踩過的坑
- 基于 RocketMQ 的改進
同程藝龍消息系統的使用情況
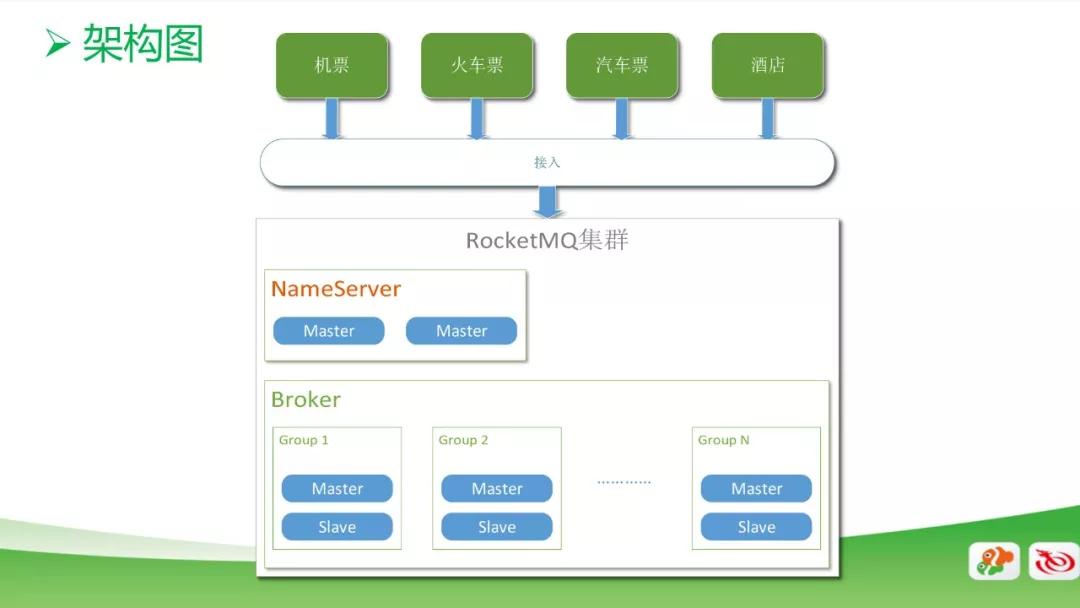
RocketMQ 集群分為 Name Server 和 Broker 兩部分,Name Server 用的是雙主模式,一個是考慮性能,另一個考慮安全性。在純數據的 Broker 分成很多組,每個組里面分為 Master 和 Slave。
目前,我們的機票、火車票、汽車票、酒店相關業務已經接入了 RocketMQ,用于流量高峰時候的削峰,以減少后端的壓力。
同時,對常規的系統進行解耦,將一些同步處理改成異步處理,每天處理的數據達 1500 億條。
選擇 RocketMQ 的原因是:
- 接入簡單,引入的 Java 包比較少
- 純 Java 開發,設計邏輯比較清晰
- 整體性能比較穩定的,Topic 數量大的情況下,可以保持性能
同程藝龍消息系統的應用場景
退訂系統
這個是我們退訂系統中的一個應用場景。用戶點擊前端的退訂按鈕,系統調用退訂接口,再去調用供應商的退訂接口,從而完成一個退訂功能。
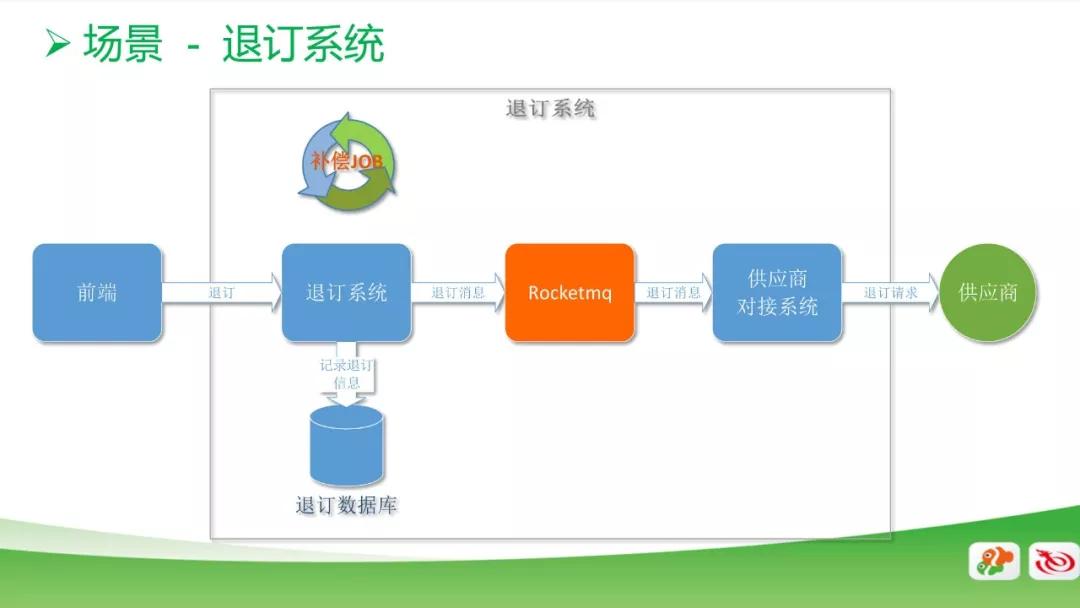
如果供應商的系統接口不可靠,就會導致用戶退訂失敗,如果系統設置為同步操作,會導致用戶需要再去點一次。
所以,我們引入 RocketMQ 將同步改為異步,當前端用戶發出退訂需求,退訂系統接收到請求后就會記錄到退訂系統的數據庫里面,表示這個用戶正在退訂。
同時通過消息引擎把這條退訂消息發送到和供應商對接的系統,去調用供應商的接口。
如果調用成功,就會把數據庫進行標識,表示已經退訂成功。同時,加了一個補償的腳本,去數據庫撈那些未退訂成功的消息,重新退訂,避免消息丟失引起的退訂失敗的情況。
房倉系統
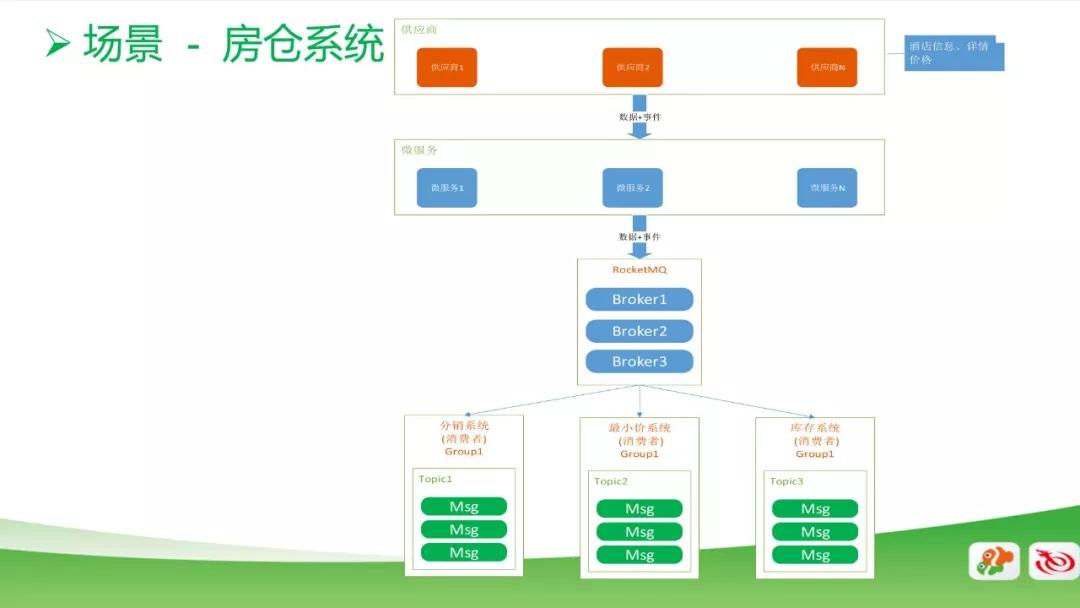
第二個應用場景是我們的房倉系統。這是一個比較常規的消息使用場景,我們從供應商處采集一些酒店的基本信息數據和詳情數據,然后接入到消息系統,由后端的分銷系統、最小價系統和庫存系統來進行計算。
同時當供應商有變價的時候,變價事件也會通過消息系統傳遞給我們的后端業務系統,來保證數據的實時性和準確性。
供應庫的訂閱系統
數據庫的訂閱系統也用到了消息的應用。一般情況下做數據庫同步,都是通過 binlog 去讀里面的數據,然后搬運到數據庫。
搬運過程中,我們最關注的是數據的順序性,因此在數據庫 row 模式的基礎上,新增了一個功能,以確保每一個 Queue 里面的順序是唯一的。
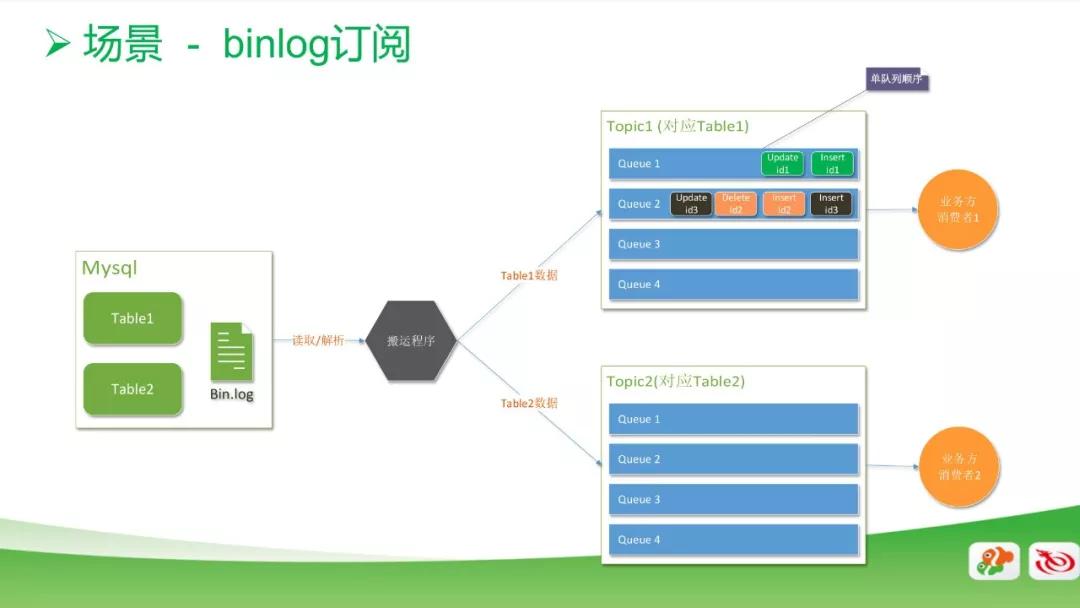
雖然 Queue 里面的順序天然都是唯一的,但我們在使用上有一個特點,就是把相同 ID 的消息都是放在同一個 Queue 里面的。
例如,圖中右上角 id1 的消息,數據庫主字段是 id1,就統一放在 Queue1 里面,而且是順序的。
在 Queue2 里,兩個 id3 之間被兩個順序的 id2 間隔開來了,但實際消費讀出來的時候,也會是順序的,由此,可以用多隊列的順序來提高整體的并發度。
技術上踩過的坑
供應商系統的場景
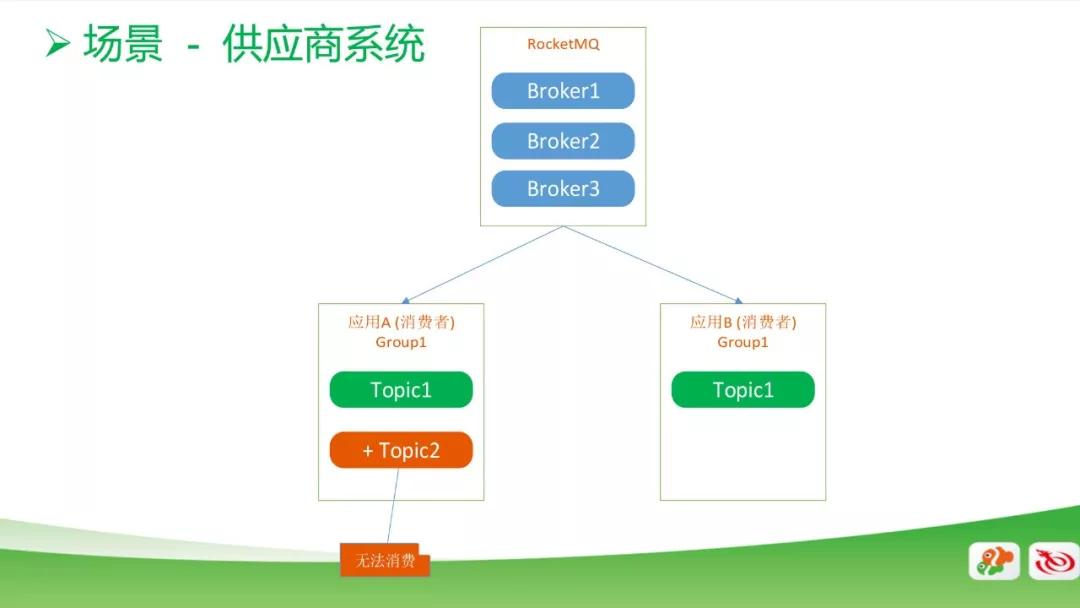
上圖中,一個 MQ 對應有兩個消費者,他們是在同一個 Group1 中,起初大家都只有 Topic1,這時候是正常消費的。
但如果在***個消費者里面加入一個 Topic2,這時候是無法消費或消費不正常了。
這是 RocketMQ 本身的機制引起的問題,需要在第二個消費者里面加入 Topic2 才能正常消費。
支付交易系統的場景
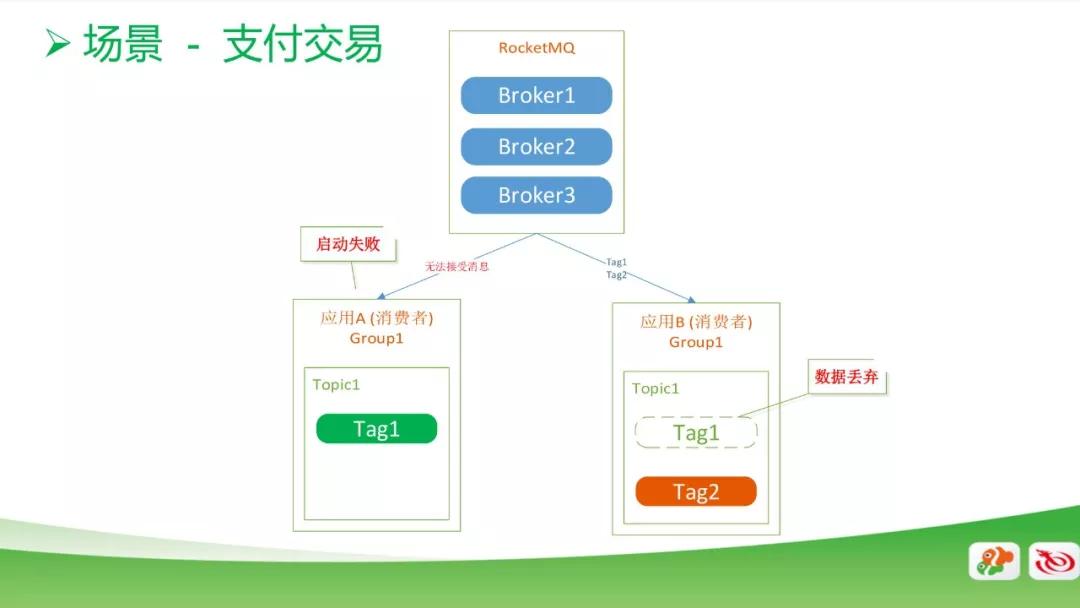
另外一個是支付交易系統,這個場景下也是有兩個應用,他們都是在同一 Group 和同一 Topic 下,一個是消費 Tag1 的數據,另一個是消費 Tag2 的數據。
正常情況下,啟動應該是沒問題的,但是有一天我們發現一個應用起不來了,另外一個應用,他只消費 Tag2 的數據,但是因為 RocketMQ 的機制會把 Tag1 的數據拿過來,拿過來后會把 Tag1 的數據丟棄。
這會導致用戶在支付過程中出現支付失敗的情況。對此,我們把 Tag2 放到 Group2 里面,兩個 Group 就不會消費相同的消息了。
個人建議 RocketMQ 能夠實現一個機制,即只接受自己的 Tag 消息,非相關的 Tag 不去接收。
大量老數據讀取的場景
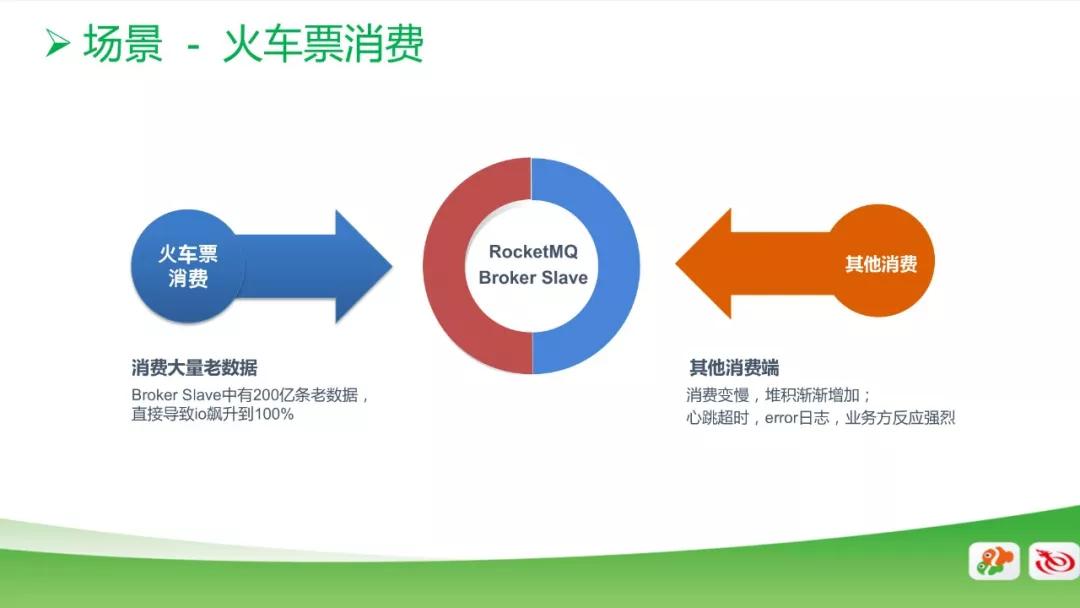
在火車票消費的場景中,我們發現有 200 億條老數據沒有被消費。當我們消費啟動的時候,RocketMQ 會默認從第 0 個數據開始讀,這時候磁盤 IO 飆升到 100%,從而影響到其他消費端數據的讀取,但這些老數據被加載后,并沒有實際作用。
因此,對于大量老數據讀取的改進方式是:
- 對于新消費組,默認從 LAST_OFFSET 消費。
- Broker 中單 Topic 堆積超過 1000 萬時,禁止消費,需聯系管理員開啟消費。
- 監控要到位,磁盤 IO 飆升時,能立刻聯系到消費方處理。
服務端的場景
①CentOS 6.6 中 Futex Kernel bug, 導致 Name Server, Broker 進程經常掛起,無法正常工作
解決方法:升級到 6.7
②服務端 2 個線程會創建相同 CommitLog 放入 List,導致計算消息 offset 錯誤,解析消息失敗,無法消費,重啟沒法解決問題。
解決方法:線程安全問題,改為單線程
③Pull 模式下重置消費進度,導致服務端填充大量數據到 Map 中,Broker CPU 使用率飆升 100%。
解決方法:Map 局部變量場景用不到,刪除
④Master 建議客戶端到 Slave 消費時,若數據還沒同步到 Slave, 會重置 pullOffset,導致大量重復消費。
解決方法:不重置 offset
⑥同步沒有 MagicCode,安全組掃描同步端口時,Master 解析錯誤,導致一些問題。
解決方法:同步時添加 magicCode 校驗
基于 RocketMQ 的改進
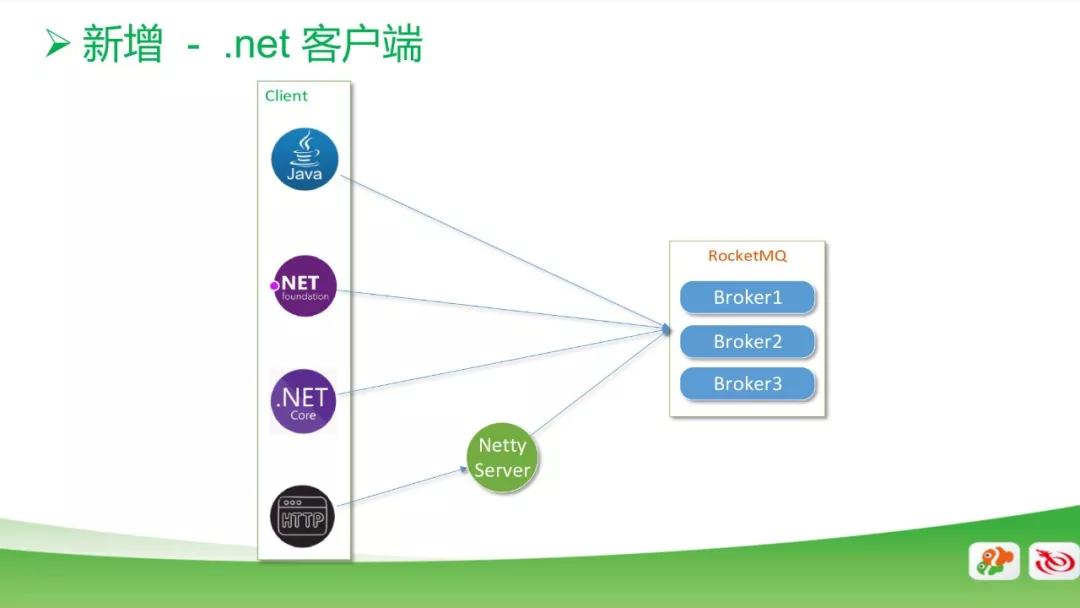
新增客戶端
新增 .net 客戶端,基于 Java 源代碼原生開發;新增 HTTP 客戶端,實現部分功能,并通過 Netty Server 連接 RocketMQ。
新增消息限流功能
如果客戶端代碼寫錯產生死循環,就會產生大量的重復數據,這時候會把生產線程打滿,導致隊列溢出,嚴重影響我們 MQ 集群的穩定性,從而影響其他業務。
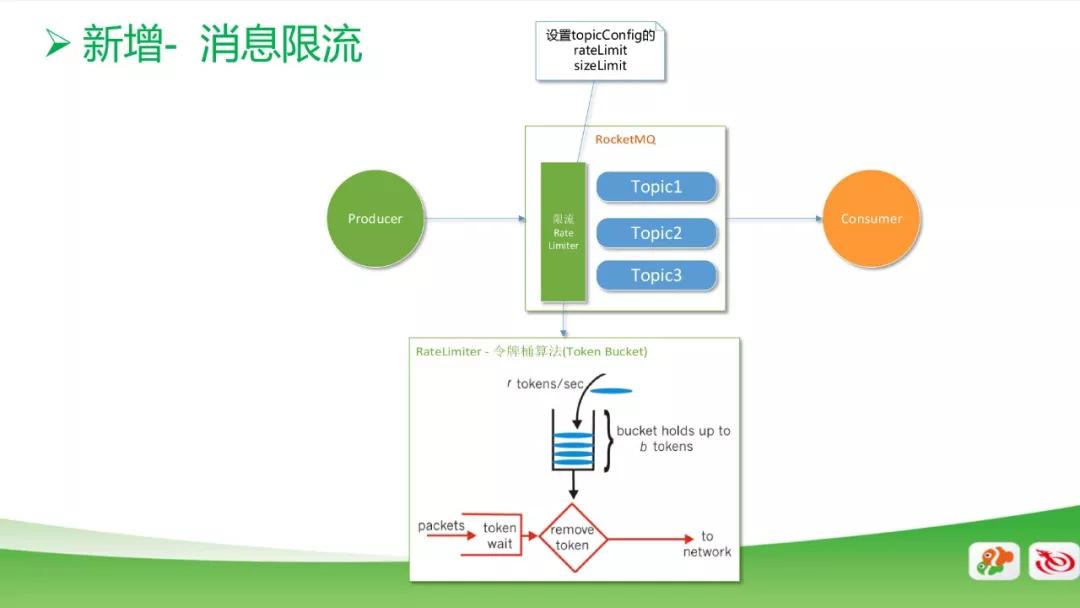
上圖是限流的模型圖,我們把限流功能加在 Topic 之前。通過限流功能可以設置 rate limit 和 size limit 等。
其中 rate limit 是通過令牌桶算法來實現的,即每秒往桶里放多少個令牌,每秒就消費多少速度,或者是往 Topic 里寫多少數據。以上的兩個配置是支持動態修改的。
后臺監控
我們還做了一個監控后臺,用于監控消息的全鏈路過程,包括:
- 消息全鏈路追蹤,覆蓋消息產生、消費、過期整個生命周期
- 消息生產、消費曲線
- 消息生產異常報警
- 消息堆積報警,通知哪個 IP 消費過慢
其他功能:
- HTTP 方式生產,消費消息
- Topic 消費權限設置,Topic 只能被指定 Group 消費,防止線上錯亂訂閱
- 支持新消費組從***位置消費 (默認是從***條開始消費)
- 廣播模式消費進度同步 (服務端顯示進度)
以上便是同程藝龍在消息系統建設方面的實踐。





















