MySQL:邏輯架構與存儲引擎
本文概述了MySQL的服務器架構、各種存儲引擎之間的主要區別,以及這些區別的重要性。
MySQL邏輯架構整體分為三層
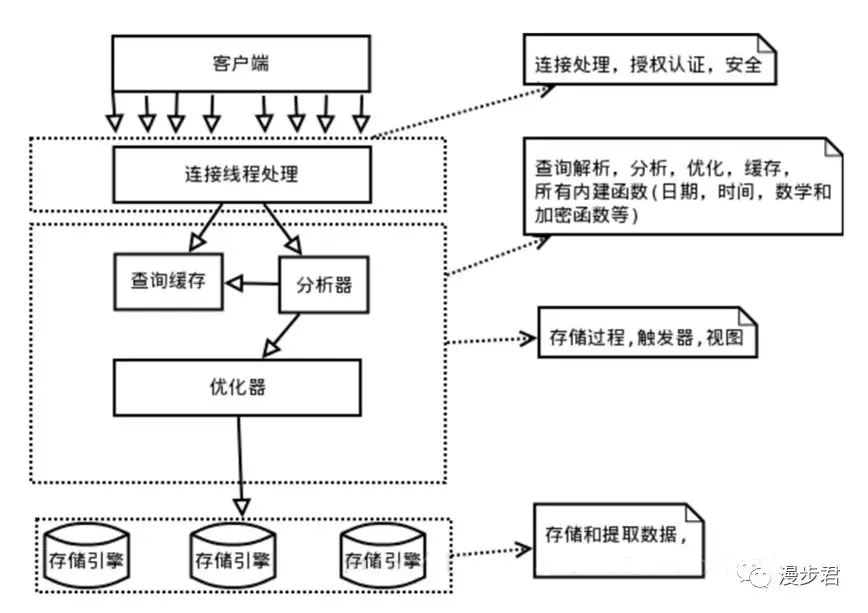
>最上層并非MySQL所獨有,主要進行如連接處理、授權認證、安全等功能的處理。
>MySQL大多數核心服務均在第二層架構,包括查詢解析、分析、優化、緩存、內置函數(如日期、時間、數學和加密等函數)。所有的跨存儲引擎的功能也在這一層實現:存儲過程、觸發器、視圖等。
>最下層為存儲引擎,負責MySQL中的數據存儲和提取。每種存儲引擎都有其優勢和劣勢。服務器通過API與存儲引擎進行通信,這些API接口屏蔽了不同存儲引擎間的差異。存儲引擎API包含幾十個底層函數用于執行,但不會去解析SQL(InnoDB是個例外,他會解析外鍵定義,因為MySQL服務器沒有實現該功能);不同引擎只會簡單的響應上層服務器的請求,而不會相互通信。
對于存儲引擎,本文以及之后的文章只對MyISAM和InnoDB進行探究。
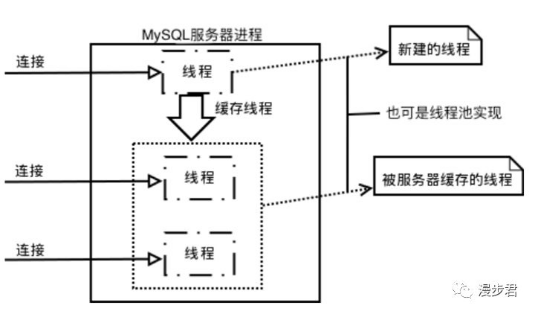
1.連接管理與安全性
對于每個客戶端連接,服務器都會在進程中新建一個線程處理(如果是線程池的話,則是分配一個空的線程),這個連接的查詢只會在這個單獨的線程中執行(每個線程相互獨立),該線程只能輪流在某個CPU核心(多核CPU)或者CPU中運行。服務器會負責緩存線程,因此不需要為每個新建的連接創建或者銷毀線程(線程的重用和銷毀都由服務器控制)。
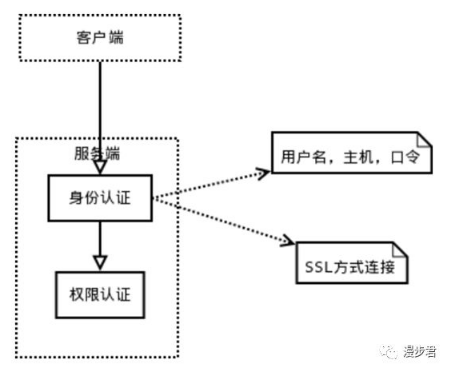
當客戶端連接到MySQL服務器時,服務器需要對其進行認證,如基于用戶名、原始主機信息和密碼;一旦連接成功,服務器會繼續驗證客戶端是否具有執行某個特定查詢的權限。
2.優化與執行
MySQL會解析查詢,并創建內部數據結構(解析樹),然后對其進行各種優化,包括重寫查詢、決定表的讀取順序,以及選擇合適的索引等。
優化器并不關心表使用的是什么存儲引擎,但存儲引擎對于優化查詢查詢是有影響的。優化器會請求存儲引擎提供容量或某個具體操作的開銷信息,以及表數據的統計信息等。
對于SELECT語句,服務器會優先查詢緩存(Query Cache)。如果有緩存就直接返回緩存中的結果集,否則就執行查詢解析、優化和執行的整個過程。
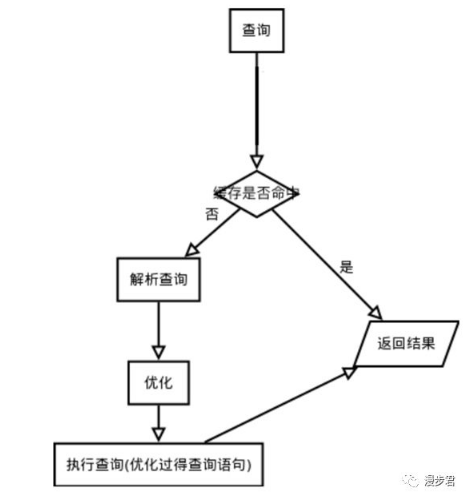
具體優化措施我們之后再進行探討。
3.并發控制
無論何時,只要有多個查詢需要在同一時刻修改數據,都會產生并發控制的問題。在處理并發讀或者寫的時候,可以通過實現一個由兩種類型的鎖組成的鎖系統來解決問題。這兩種類型的鎖通常被稱為共享鎖(讀鎖)和排它鎖(寫鎖)。
讀鎖是共享的,多個客戶在同一時刻可以同時讀取一個資源,互不干擾;而寫鎖是排他的,也就是說一個寫鎖會阻塞其他的寫鎖和讀鎖,這樣才能保證數據安全。
一種提高共享資源并發性的方式就是讓鎖定對象更有選擇性,盡量只鎖定需要修改的部分數據而不是所有的資源。在給定的資源上,鎖定的數據量越少,則系統的并發程度越高,只要相互之間不發生沖突即可。
但加鎖也需要消耗資源,如果花費大量時間和資源來管理所而不是存儲數據,那就得不償失了。所以需要一種鎖策略,在鎖的開銷和數據的安全性之間尋求平衡。
MySQL的每種存儲引擎都可以實現自己的鎖策略,其中有兩種最重要的鎖策略:表鎖和行鎖。
表鎖是MySQL中最基本的鎖策略,并且是開銷最小的策略,他會鎖定整張表;在特定場景中表鎖可以有良好的性能。另外寫鎖也比讀鎖有更高的優先級,一個寫鎖請求可能會被插到讀鎖隊列的前面。
行鎖可以***程度的支持并發,但同時開銷也是***,在InnoDB中實現的就是行鎖(在存儲引擎層實現)。
4.MySQL的InnoDB引擎支持事務
有關事務的描述可以參考《MyBatis:Spring事務管理(十一)》
MySQL服務器層不管理事務,事務是由下層存儲引擎實現的。所以在同一個事務中,使用多種存儲引擎是不可靠的。
InnoDB采用的是兩階段鎖定協議,即在事務執行過程中,隨時都可以執行鎖定,鎖只有在執行COMMIT或者ROLLBACK的時候才會釋放,并且所有的鎖是在同一時刻被釋放的,InnDB會根據隔離級別在需要的時候自動加鎖。
5.多版本并發控制
MySQL的大多數事務性存儲引擎實現的都不是簡單的行級鎖。基于提升并發性能的考慮,他們一般都同時實現了多版本并發控制(MVCC),他可以認為是行級鎖的一種變種,在很多情況下避免了加鎖操作,所以開銷更低。
MVCC的實現,是通過保存數據在某個時間點的快照來實現的,不管需要執行多長時間,每個事務看到的數據都是一致的。根據事務開始的時間不同,每個事務對同一張表,同一時刻看到的數據可能是不一樣的。
下面我們通過InnoDB的簡化版行為來說明MVCC是如何工作的。
InnoDB的MVCC是通過在每行記錄后面保存兩個隱藏列來實現:一個保存了行的創建時間,另一個保存行的過期時間(并不是實際時間值,而是系統版本號)。每開始一個新的事務,系統版本號就會自動遞增。事務開始時刻的系統版本號會作為事務的版本號,用來和查詢到的每行記錄的版本號進行比較。當在默認可重復讀隔離級別下時:
SELECT:InnoDB會根據以下兩個條件檢查每行記錄:
>InnoDB只查找版本早于當前事務版本的數據行,這樣可以確保事務讀取的行,要么是在事務開始之前已經存在的,要么是事務自身插入或者修改過的。
>行的刪除版本要么未定義,要么大于當前事務版本號。這可以確保事務讀取到的行,在事務開始之前未被刪除。
只有符合上述兩個條件的記錄,才能返回作為查詢結果。
INSERT:InnoDB為新插入的每一行保存當前系統版本號作為行版本號。
DELETE:為刪除的每一行保存當前系統版本號作為行刪除標識。
UPDATE:InnoDB為插入一行新紀錄,保存當前版本號作為行版本號,同時保存當前系統版本號到原來的行作為行刪除標識。
保存了這兩個額外系統版本號,可以使大多數讀操作都可以不用加鎖,使得讀數據操作很簡單,性能很好,并且也能保證只會讀取到符合標準的行。不足之處是每行記錄都需要額外的存儲空間,需要做更多的行檢查工作以及一些額外的維護工作。
MVCC只在可重復讀和讀寫提交兩個隔離級別下工作。讀未提交下總是讀取***的數據行,而不是符合當前事務版本的數據行;而序列化則會對所有讀取的行都是加鎖,所以這兩個隔離級別與MVCC不兼容。
6.InnoDB存儲引擎
InnoDB的數據存儲在表空間(tablespace)中,表空間是由InnoDB管理的一個黑盒子,由一系列的數據文件組成。在MySQL4.1后,InnoDB可以將每個表的數據和索引存放在單獨的文件中。
InnoDB采用MVCC來支持高并發,并且實現了四個標準的隔離界別,默認是可重復讀,并且通過間隙鎖策略防止幻讀的出現。間隙鎖使得InnoDB不僅僅鎖定查詢涉及的行,還會對索引中的間隙進行鎖定,防止幻影行的插入。
InnoDB表是基于聚簇索引建立的(后面再詳細介紹),對主鍵查詢有很高的性能。不過他的二級索引(非主鍵索引)中必須包含主鍵列,所以如果主鍵列很大的話,其他的所有索引都會很大。
InnoDB內部做了很多優化,包括從磁盤讀取時間時采用的可預測性預讀,能夠自動在內存中創建hash索引以加速讀操作的自適應哈希索引,以及能夠加速插入操作的插入緩沖區等,這些之后再具體分析其實現。同時作為事務型的存儲引擎,InnoDB通過一些機制和工具支持真正的熱備份。
7.MyISAM存儲引擎
在MySQL5.1及之前的版本MyISAM是默認的存儲引擎,他提供了大量的特性如全文索引、壓縮、空間函數等,但他不支持事務和行級鎖,而且崩潰后無法安全恢復。對于只讀的數據,或者表比較小、可以忍受修復操作的,依然可以繼續使用。
>加鎖與并發:MyISAM對整張表加鎖,讀取時會對需要讀到的所有表加共享鎖,寫入時加排它鎖。但在表有讀取查詢的同時,也可以往表中插入新的記錄(并發插入)。
>修復:對于MyISAM表,可以手動或者自動執行檢查和修復工作,但會造成一些數據丟失,而且修復操作很慢。
>索引特性:對于MyISAM即使是BLOB和TEXT字段也可以基于前500個字符創建索引。他也支持全文索引(基于分詞創建的索引),可以支持復雜的查詢。
>延遲更新索引鍵:在創建表時,如果指定了DELAY_KEY_WRITE,在每次修改執行完成時,不會立刻將修改的數據寫入磁盤,而是會寫到內存中的鍵緩沖區,只有在清理緩沖區或者關閉表的時候才會將對應的索引塊寫入磁盤。這樣可以極大提升寫入性能,但遇到數據庫或服務器崩潰時會造成索引損壞。
如果表創建并導入數據行不會再進行修改操作,這時可以采用MyISAM壓縮表(myisampack)。這樣可以極大減少磁盤空間占用、減少磁盤I/O,從而提升查詢性能。壓縮表支持索引,但索引也都是只讀。