HBase存儲(chǔ)剖析與數(shù)據(jù)遷移
1.概述
HBase的存儲(chǔ)結(jié)構(gòu)和關(guān)系型數(shù)據(jù)庫(kù)不一樣,HBase面向半結(jié)構(gòu)化數(shù)據(jù)進(jìn)行存儲(chǔ)。所以,對(duì)于結(jié)構(gòu)化的SQL語言查詢,HBase自身并沒有接口支持。在大數(shù)據(jù)應(yīng)用中,雖然也有SQL查詢引擎可以查詢HBase,比如Phoenix、Drill這類。但是閱讀這類SQL查詢引擎的底層實(shí)現(xiàn),依然是調(diào)用了HBase的Java API來實(shí)現(xiàn)查詢,寫入等操作。這類查詢引擎在業(yè)務(wù)層創(chuàng)建Schema來映射HBase表結(jié)構(gòu),然后通過解析SQL語法數(shù),***底層在調(diào)用HBase的Java API實(shí)現(xiàn)。

本篇內(nèi)容筆者并不是給大家來介紹HBase的SQL引擎,我們來關(guān)注HBase更低層的東西,那就是HBase的存儲(chǔ)實(shí)現(xiàn)。以及跨集群的HBase集群數(shù)據(jù)遷移。
2.內(nèi)容
HBase數(shù)據(jù)庫(kù)是唯一索引就是RowKey,所有的數(shù)據(jù)分布和查詢均依賴RowKey。所以,HBase數(shù)據(jù)庫(kù)在表的設(shè)計(jì)上會(huì)有很嚴(yán)格的要求,從存儲(chǔ)架構(gòu)上來看,HBase是基于分布式來實(shí)現(xiàn)的,通過Zookeeper集群來管理HBase元數(shù)據(jù)信息,比如表名就存放在Zookeeper的/hbase/table目錄下。如下圖所示:
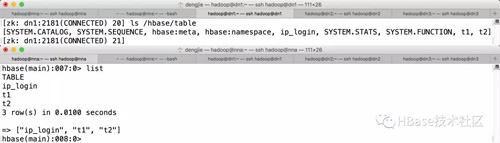
2.1 Architecture
HBase是一個(gè)分布式存儲(chǔ)系統(tǒng),底層數(shù)據(jù)存儲(chǔ)依賴Hadoop的分布式存儲(chǔ)系統(tǒng)(HDFS)。HBase架構(gòu)分三部分來組成,它們分別是:ZooKeeper、HMaster和HRegionServer。
- ZooKeeper:HBase的元數(shù)據(jù)信息、HMaster進(jìn)程的地址、Master和RegionServer的監(jiān)控維護(hù)(節(jié)點(diǎn)之間的心跳,判斷節(jié)點(diǎn)是否下線)等內(nèi)容均需要依賴ZooKeeper來完成。是HBase集群中不可缺少的核心之一。
- HMaster:HMaster進(jìn)程在HBase中承擔(dān)Master的責(zé)任,負(fù)責(zé)一些管理操作,比如給表分配Region、和數(shù)據(jù)節(jié)點(diǎn)的心跳維持等。一般客戶端的讀寫數(shù)據(jù)的請(qǐng)求操作不會(huì)經(jīng)過Master,所以在分配JVM內(nèi)存的適合,一般32GB大小即可。
- HRegionServer:HRegionServer進(jìn)程在HBase中承擔(dān)RegionServer的責(zé)任,負(fù)責(zé)數(shù)據(jù)的存儲(chǔ)。每個(gè)RegionServer由多個(gè)Region組成,一個(gè)Region維護(hù)一定區(qū)間的RowKey的數(shù)據(jù)。如下圖所示:

圖中Region(dn2:16030)維護(hù)的RowKey范圍為0001~0002。
HBase為了保證高可用性(HA),一般都會(huì)部署兩個(gè)Master節(jié)點(diǎn),其中一個(gè)作為主,另一個(gè)作為Backup節(jié)點(diǎn)。這里誰是主,誰是Backup取決于那個(gè)HMaster進(jìn)程能從Zookeeper上對(duì)應(yīng)的Master目錄中競(jìng)爭(zhēng)到Lock,持有該目錄Lock的HMaster進(jìn)程為主Master,而另外一個(gè)為Backup,當(dāng)主Master發(fā)生意外或者宕機(jī)時(shí),Backup的Master會(huì)立刻競(jìng)爭(zhēng)到Master目錄下的Lock從而接管服務(wù),成為主Master對(duì)外提供服務(wù),保證HBase集群的高可用性。
2.2 RegionServer
HBase負(fù)責(zé)數(shù)據(jù)存儲(chǔ)的就是RegionServer,簡(jiǎn)稱RS。在HBase集群中,如果只有一份副本時(shí),整個(gè)HBase集群中的數(shù)據(jù)都是唯一的,沒有冗余的數(shù)據(jù)存在,也就是說HBase集群中的每個(gè)RegionServer節(jié)點(diǎn)上保存的數(shù)據(jù)都是不一樣的,這種模式由于副本數(shù)只有一份,即是配置多個(gè)RegionServer組成集群,也并不是高可用的。這樣的RegionServer是存在單點(diǎn)問題的。雖然,HBase集群內(nèi)部數(shù)據(jù)有Region存儲(chǔ)和Region遷移機(jī)制,RegionServer服務(wù)的單點(diǎn)問題可能花費(fèi)很小的代價(jià)可以恢復(fù),但是一旦停止RegionServre上含有ROOT或者M(jìn)ETA表的Region,那這個(gè)問題就嚴(yán)重,由于數(shù)據(jù)節(jié)點(diǎn)RegionServer停止,該節(jié)點(diǎn)的數(shù)據(jù)將在短期內(nèi)無法訪問,需要等待該節(jié)點(diǎn)的HRegionServer進(jìn)程重新啟動(dòng)才能訪問其數(shù)據(jù)。這樣HBase的數(shù)據(jù)讀寫請(qǐng)求如果恰好指向該節(jié)點(diǎn)將會(huì)收到影響,比如:拋出連接異常、RegionServer不可用等異常。
3.日志信息
HBase在實(shí)現(xiàn)WAL方式時(shí)會(huì)產(chǎn)生日志信息,即HLog。每一個(gè)RegionServer節(jié)點(diǎn)上都有一個(gè)HLog,所有該RegionServer節(jié)點(diǎn)上的Region寫入數(shù)據(jù)均會(huì)被記錄到該HLog中。HLog的主要職責(zé)就是當(dāng)遇到RegionServer異常時(shí),能夠盡量的恢復(fù)數(shù)據(jù)。
在HBase運(yùn)行的過程當(dāng)中,HLog的容量會(huì)隨著數(shù)據(jù)的寫入越來越大,HBase會(huì)通過HLog過期策略來進(jìn)行定期清理HLog,每個(gè)RegionServer內(nèi)部均有一個(gè)HLog的監(jiān)控線程。HLog數(shù)據(jù)從MemStore Flush到底層存儲(chǔ)(HDFS)上后,說明該時(shí)間段的HLog已經(jīng)不需要了,就會(huì)被移到“oldlogs”這個(gè)目錄中,HLog監(jiān)控線程監(jiān)控該目錄下的HLog,當(dāng)該文件夾中的HLog達(dá)到“hbase.master.logcleaner.ttl”(單位是毫秒)屬性所配置的閥值后,監(jiān)控線程會(huì)立即刪除過期的HLog數(shù)據(jù)。
4.數(shù)據(jù)存儲(chǔ)
HBase通過MemStore來緩存Region數(shù)據(jù),大小可以通過“hbase.hregion.memstore.flush.size”(單位byte)屬性來進(jìn)行設(shè)置。RegionServer在寫完HLog后,數(shù)據(jù)會(huì)接著寫入到Region的MemStore。由于MemStore的存在,HBase的數(shù)據(jù)寫入并非是同步的,不需要立刻響應(yīng)客戶端。由于是異步操作,具有高性能和高資源利用率等優(yōu)秀的特性。數(shù)據(jù)在寫入到MemStore中的數(shù)據(jù)后都是預(yù)先按照RowKey的值來進(jìn)行排序的,這樣便于查詢的時(shí)候查找數(shù)據(jù)。
5.Region分割
在HBase存儲(chǔ)中,通過把數(shù)據(jù)分配到一定數(shù)量的Region來達(dá)到負(fù)載均衡。一個(gè)HBase表會(huì)被分配到一個(gè)或者多個(gè)Region,這些Region會(huì)被分配到一個(gè)或者多個(gè)RegionServer中。在自動(dòng)分割策略中,當(dāng)一個(gè)Region中的數(shù)據(jù)量達(dá)到閥值就會(huì)被自動(dòng)分割成兩個(gè)Region。HBase的表中的Region按照RowKey來進(jìn)行排序,并且一個(gè)RowKey所對(duì)應(yīng)的Region只有一個(gè),保證了HBase的一致性。
一個(gè)Region中由一個(gè)或者多個(gè)Store組成,每個(gè)Store對(duì)應(yīng)一個(gè)列族。一個(gè)Store中包含一個(gè)MemStore和多個(gè)Store Files,每個(gè)列族是分開存放以及分開訪問的。自動(dòng)分割有三種策略,分別是:
- ConstantSizeRegionSplitPolicy:在HBase-0.94版本之前是默認(rèn)和唯一的分割策略。當(dāng)某一個(gè)Store的大小超過閥值時(shí)(hbase.hregion.max.filesize,默認(rèn)時(shí)10G),Region會(huì)自動(dòng)分割。
- IncreasingToUpperBoundRegionSplitPolicy:在HBase-0.94中,這個(gè)策略分割大小和表的RegionServer中的Region有關(guān)系。分割計(jì)算公式為:Min(R*R*'hbase.hregion.memstore.flush.size','hbase.hregion.max.filesize'),其中,R表示RegionServer中的Region數(shù)。比如:hbase.hregion.memstore.flush.size=256MB,hbase.hregion.max.filesize=20GB,那么***次分割的大小為Min(1*1*256,20GB)=256MB,也就是在***次大到256MB會(huì)分割成2個(gè)Region,后續(xù)以此公式類推計(jì)算。
- KeyPrefixRegionSplitPolicy:可以保證相同前綴的RowKey存放在同一個(gè)Region中,可以通過hbase.regionserver.region.split.policy屬性來指定分割策略。
6.磁盤合理規(guī)劃
部署HBase集群時(shí),磁盤和內(nèi)存的規(guī)劃是有計(jì)算公式的。隨意分配可能造成集群資源利用率不高導(dǎo)致存在浪費(fèi)的情況。公式如下:
- # 通過磁盤維度的Region數(shù)和Java Heap維度的Region數(shù)來推導(dǎo) Disk Size/(RegionSize*ReplicationFactor)=Java Heap*HeapFractionForMemstore/(MemstoreSize/2)
公式中對(duì)應(yīng)的hbase-site.xml文件中的屬性中,見下表:
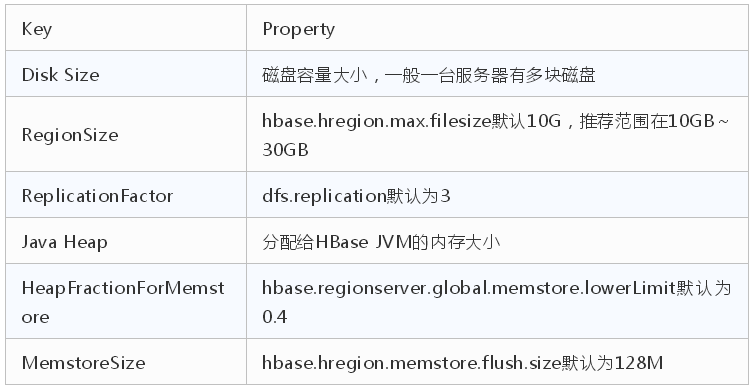
在實(shí)際使用中,MemstoreSize空間打下只使用了一半(1/2)的容量。 舉個(gè)例子,一個(gè)RegionServer的副本數(shù)配置為3,RegionSize為10G,HBase的JVM內(nèi)存分配45G,HBase的MemstoreSize為128M,那此時(shí)根據(jù)公式計(jì)算得出理想的磁盤容量為45G*1024*0.4*2*10G*1024*3/128M=8.5T左右磁盤空間。如果此時(shí),分配一個(gè)節(jié)點(diǎn)中掛載10個(gè)可用盤,共27T。那將有兩倍的磁盤空間不匹配造成浪費(fèi)。 為了提升磁盤匹配度,可以將RegionSize值提升至30G,磁盤空間計(jì)算得出25.5T,基本和27T磁盤容量匹配。
7.數(shù)據(jù)遷移
對(duì)HBase集群做跨集群數(shù)據(jù)遷移時(shí),可以使用Distcp方案來進(jìn)行遷移。該方案需要依賴MapReduce任務(wù)來完成,所以在執(zhí)行遷移命令之前確保新集群的ResourceManager、NodeManager進(jìn)程已啟動(dòng)。同時(shí),為了查看遷移進(jìn)度,推薦開啟proxyserver進(jìn)程和historyserver進(jìn)程,開啟這2個(gè)進(jìn)程可以方便在ResourceManager業(yè)務(wù)查看MapReduce任務(wù)進(jìn)行的進(jìn)度。 遷移的步驟并不復(fù)雜,在新集群中執(zhí)行distcp命令即可。具體操作命令如下所示:
- # 在新集群的NameNode節(jié)點(diǎn)執(zhí)行命令[hadoop@nna ~]$ hadoop distcp -Dmapreduce.job.queue.name=queue_0001_01 -update -skipcrccheck -m 100 hdfs://old_hbase:9000/hbase/data/tabname /hbase/data/tabname
為了遷移方便,可以將上述命令封裝成一個(gè)Shell腳本。具體實(shí)現(xiàn)如下所示:
- #! /bin/bash
- for i in `cat /home/hadoop/hbase/tbl`
- do
- echo $i
- hadoop distcp -Dmapreduce.job.queue.name=queue_0001_01 -update -skipcrccheck -m 100 hdfs://old_hbase:9000/hbase/data/$i /hbase/data/$i
- done
- hbase hbck -repairHoles
將待遷移的表名記錄在/home/hadoop/hbase/tbl文件中,一行代表一個(gè)表。內(nèi)容如下所示:
- [hadoop@nna ~]$ vi /home/hadoop/hbase/tbl
- # 表名列表
- tbl1
- tbl2
- tbl3
- tbl4
***,在循環(huán)迭代遷移完成后,執(zhí)行HBase命令“hbase hbck -repairHoles”來修復(fù)HBase表的元數(shù)據(jù),如表名、表結(jié)構(gòu)等內(nèi)容,會(huì)從新注冊(cè)到新集群的Zookeeper中。
8.總結(jié)
HBase集群中如果RegionServer上的Region數(shù)量很大,可以適當(dāng)調(diào)整“hbase.hregion.max.filesize”屬性值的大小,來減少Region分割的次數(shù)。在執(zhí)行HBase跨集群數(shù)據(jù)遷移時(shí),使用Distcp方案來進(jìn)行,需要保證HBase集群中的表是靜態(tài)數(shù)據(jù),換言之,需要停止業(yè)務(wù)表的寫入。如果在執(zhí)行HBase表中數(shù)據(jù)遷移時(shí),表持續(xù)有數(shù)據(jù)寫入,導(dǎo)致遷移異常,拋出某些文件找不到。