技術分享:Hadoop框架
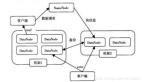
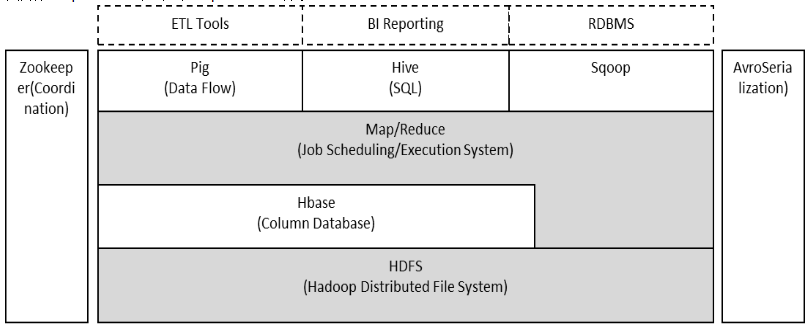
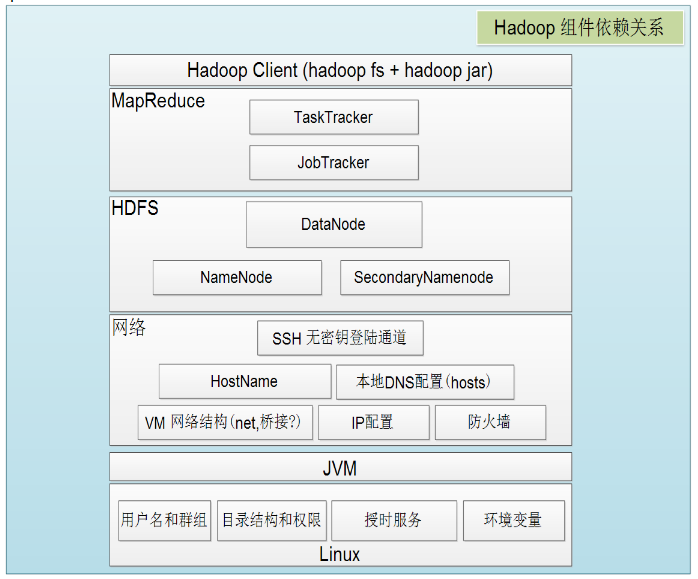
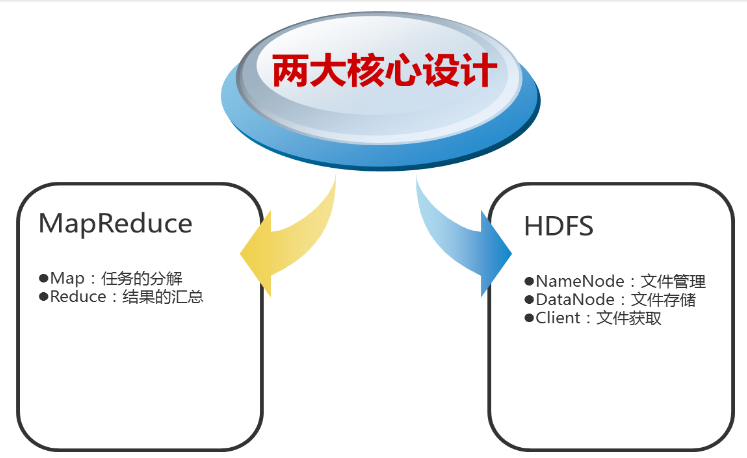
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成員組成,其中最基礎最重要元素為底層用于存儲集群中所有存儲節點文件的文件系統HDFS(Hadoop Distributed File System)來執行MapReduce程序的MapReduce引擎。
- Pig是一個基于Hadoop的大規模數據分析平臺,Pig為復雜的海量數據并行計算提供了一個簡單的操作和編程接口
- Hive是基于Hadoop的一個工具,提供完整的SQL查詢,可以將sql語句轉換為MapReduce任務進行運行
- ZooKeeper:高效的,可拓展的協調系統,存儲和協調關鍵共享狀態;
- HBase是一個開源的,基于列存儲模型的分布式數據庫;
- HDFS是一個分布式文件系統,有著高容錯性的特點,適合那些超大數據集的應用程序;
- MapReduce是一種編程模型,用于大規模數據集(大于1TB)的并行運算。
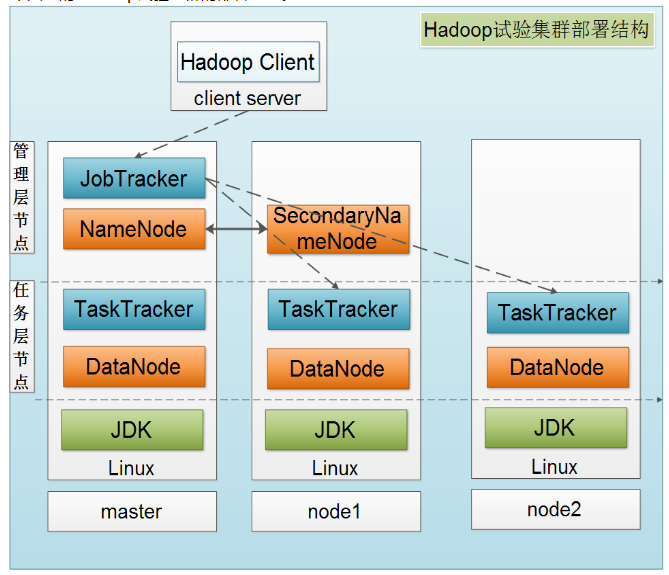
下圖是一個典型的Hadoop集群的部署結構:
接著給出Hadoop各組件依賴共存關系:
HDFS是一個高度容錯性的分布式文件系統,可以被廣泛的部署于廉價的PC上。它以流式訪問模式訪問應用程序的數據,這大大提高了整個系統的數據吞吐量,因而非常適合用于具有超大數據集的應用程序中。
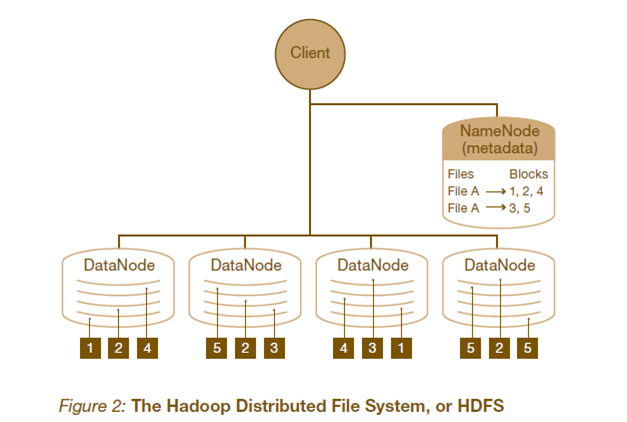
HDFS的架構如圖所示。HDFS架構采用主從架構(master/slave)。一個典型的HDFS集群包含一個NameNode節點和多個DataNode節點。NameNode節點負責整個HDFS文件系統中的文件的元數據的保管和管理,集群中通常只有一臺機器上運行NameNode實例,DataNode節點保存文件中的數據,集群中的機器分別運行一個DataNode實例。在HDFS中,NameNode節點被稱為名稱節點,DataNode節點被稱為數據節點。DataNode節點通過心跳機制與NameNode節點進行定時的通信。
NameNode
NameNode可以看作是分布式文件系統中的管理者,存儲文件系統的meta-data,主要負責管理文件系統的命名空間,集群配置信息,存儲塊的復制。
DataNode
DataNode是文件存儲的基本單元。它存儲文件塊在本地文件系統中,保存了文件塊的meta-data,同時周期性的發送所有存在的文件塊的報告給NameNode。
Client
Client就是需要獲取分布式文件系統文件的應用程序。
以下來說明HDFS如何進行文件的讀寫操作:
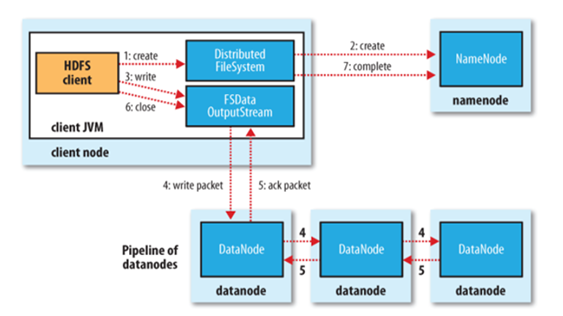
文件寫入
- Client向NameNode發起文件寫入的請求
- NameNode根據文件大小和文件塊配置情況,返回給Client它所管理部分DataNode的信息。
- Client將文件劃分為多個文件塊,根據DataNode的地址信息,按順序寫入到每一個DataNode塊中。
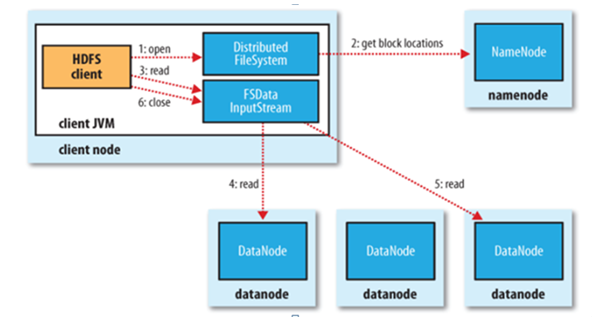
文件讀取
- Client向NameNode發起文件讀取的請求
- NameNode返回文件存儲的DataNode的信息
- Client讀取文件信息
MapReduce是一種編程模型,用于大規模數據集的并行運算。Map(映射)和Reduce(化簡),采用分而治之思想,先把任務分發到集群多個節點上,并行計算,然后再把計算結果合并,從而得到最終計算結果。多節點計算,所涉及的任務調度、負載均衡、容錯處理等,都由MapReduce框架完成,不需要編程人員關心這些內容。
下圖是MapReduce的處理過程:
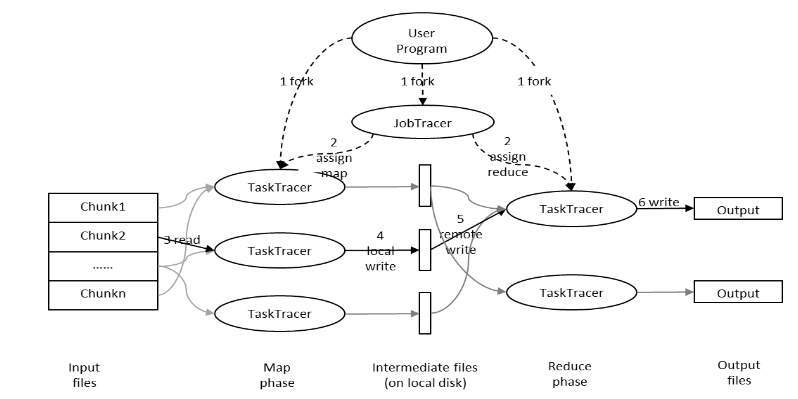
用戶提交任務給JobTracer,JobTracer把對應的用戶程序中的Map操作和Reduce操作映射至TaskTracer節點中;輸入模塊負責把輸入數據分成小數據塊,然后把它們傳給Map節點;Map節點得到每一個key/value對,處理后產生一個或多個key/value對,然后寫入文件;Reduce節點獲取臨時文件中的數據,對帶有相同key的數據進行迭代計算,然后把終結果寫入文件。
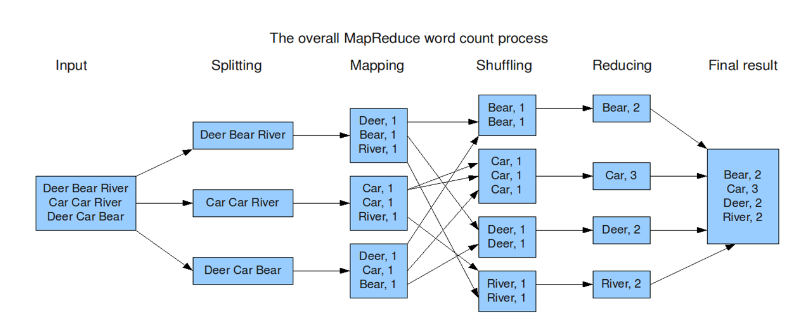
如果這樣解釋還是太抽象,可以通過下面一個具體的處理過程來理解:(WordCount實例)
Hadoop的核心是MapReduce,而MapReduce的核心又在于map和reduce函數。它們是交給用戶實現的,這兩個函數定義了任務本身。
map函數:接受一個鍵值對(key-value pair)(例如上圖中的Splitting結果),產生一組中間鍵值對(例如上圖中Mapping后的結果)。Map/Reduce框架會將map函數產生的中間鍵值對里鍵相同的值傳遞給一個reduce函數。
reduce函數:接受一個鍵,以及相關的一組值(例如上圖中Shuffling后的結果),將這組值進行合并產生一組規模更小的值(通常只有一個或零個值)(例如上圖中Reduce后的結果)
但是,Map/Reduce并不是***的,適用于Map/Reduce計算有先提條件:
- 待處理的數據集可以分解成許多小的數據集
- 每一個小數據集都可以完全并行地進行處理
若不滿足以上兩條中的任意一條,則不適合適用Map/Reduce模式。