













解讀現(xiàn)代存儲(chǔ)系統(tǒng)背后的經(jīng)典算法
應(yīng)用處理的數(shù)據(jù)量在持續(xù)增長(zhǎng)。數(shù)據(jù)的增長(zhǎng),對(duì)擴(kuò)展存儲(chǔ)能力提出了挑戰(zhàn)。就此問(wèn)題,每種數(shù)據(jù)庫(kù)管理系統(tǒng)都有其自身的權(quán)衡考慮。對(duì)于數(shù)據(jù)管理者而言,理解這些權(quán)衡因素非常關(guān)鍵,這有助于從多種方式中做出正確的選擇。
從讀 / 寫(xiě)工作負(fù)載平衡、一致性需求、延遲和訪問(wèn)模式等方面看,應(yīng)用是各異的。如果我們能對(duì)數(shù)據(jù)庫(kù)和存儲(chǔ)內(nèi)部設(shè)施架構(gòu)決策了然于胸,那么將有助于我們理解系統(tǒng)行為模式的原因所在,一旦在問(wèn)題時(shí)能解決問(wèn)題,并能根據(jù)工作負(fù)載調(diào)優(yōu)數(shù)據(jù)庫(kù)。
一個(gè)系統(tǒng)不可能在所有方面上都是***的。確保無(wú)存儲(chǔ)開(kāi)銷(xiāo)、提供***讀寫(xiě)性能的數(shù)據(jù)結(jié)構(gòu)只存在于理想情況下,在實(shí)踐中當(dāng)然是不可能存在的。
本文詳細(xì)剖析了兩種被大多數(shù)現(xiàn)代數(shù)據(jù)庫(kù)使用的存儲(chǔ)系統(tǒng)設(shè)計(jì)方法,即針對(duì)讀優(yōu)化的 B 樹(shù)1和針對(duì)寫(xiě)優(yōu)化的 LSM(日志結(jié)構(gòu)合并,log-structured merge)樹(shù) 5,并分別給出了兩種方法的一些用例和權(quán)衡考慮。
一、B 樹(shù)
B 樹(shù)是一種廣為使用的讀優(yōu)化索引數(shù)據(jù)結(jié)構(gòu),是二叉樹(shù)的一種泛化。它具有多種變體,并已用于多種數(shù)據(jù)庫(kù)(包括 MySQL InnoDB4 和 PostgreSQL 7)和文件系統(tǒng)(例如,HFS+8、ext4 中的 HTrees 9)。B 樹(shù)中的“B”表示“Bayer”,指的是數(shù)據(jù)結(jié)構(gòu)的最初創(chuàng)立者 Rudolf Bayer,也可以說(shuō)是 Bayer 彼時(shí)供職的波音公司(Boeing)。
二叉樹(shù)中,每個(gè)節(jié)點(diǎn)有兩個(gè)子節(jié)點(diǎn)(分別稱(chēng)為左子節(jié)點(diǎn)和右子節(jié)點(diǎn))。保存在左子樹(shù)和右子樹(shù)中的鍵(Key),其值分別小于和大于當(dāng)前節(jié)點(diǎn)的鍵。為維持樹(shù)的深度最小,二叉樹(shù)必須是平衡的。在添加隨機(jī)順序的鍵到樹(shù)中時(shí),最終很自然會(huì)導(dǎo)致樹(shù)的一邊比另一邊更深。
一種二叉樹(shù)重平衡(rebalance)的法是稱(chēng)為“旋轉(zhuǎn)”(rotation)方法。旋轉(zhuǎn)方法實(shí)現(xiàn)節(jié)點(diǎn)的重新排列,它將更深子樹(shù)的父節(jié)點(diǎn)下推到其子節(jié)點(diǎn)之下,并上移子節(jié)點(diǎn)為有效地置于父節(jié)點(diǎn)的原位置。圖 1 給出了一個(gè)旋轉(zhuǎn)方法的例子,實(shí)現(xiàn)了一個(gè)二叉樹(shù)的平衡。左圖的二叉樹(shù)在添加了節(jié)點(diǎn)“2”之后,是不平衡的。為了平衡二叉樹(shù),我們以節(jié)點(diǎn)“3”為軸心旋轉(zhuǎn)樹(shù),然后以節(jié)點(diǎn)“5”為軸線。節(jié)點(diǎn)“5”是原先的根節(jié)點(diǎn),也是節(jié)點(diǎn)“3”的父節(jié)點(diǎn),旋轉(zhuǎn)后成為節(jié)點(diǎn)“3”的子節(jié)點(diǎn)。在完成旋轉(zhuǎn)后得到右圖的樹(shù),其中左子樹(shù)深度降低了 1,右子樹(shù)的深度增加了 1,而樹(shù)的***深度降低了。
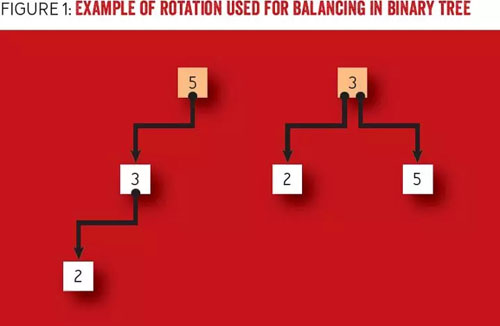
圖 1 例子:使用旋轉(zhuǎn)方法平衡二叉樹(shù)
二叉樹(shù)是一種十分有用的內(nèi)存數(shù)據(jù)結(jié)構(gòu)。由于平衡(即需要保持所有子樹(shù)的深度最小)和低扇出(每個(gè)節(jié)點(diǎn)最多具有兩個(gè)指針)特性,二叉樹(shù)在磁盤(pán)上的性能并不好。B 樹(shù)允許每個(gè)節(jié)點(diǎn)存儲(chǔ)兩個(gè)以上的指針,并可將節(jié)點(diǎn)大小調(diào)整為適合頁(yè)面的大小(例如,4KB),因此可在塊設(shè)備上良好工作。當(dāng)前,有一些實(shí)現(xiàn)中使用了更大規(guī)模的節(jié)點(diǎn),甚至橫跨多個(gè)頁(yè)面。
B 數(shù)據(jù)有如下屬性:
- 排序:排序支持順序掃描,簡(jiǎn)化了查找。
- 自平衡:插入和刪除操作無(wú)需重平衡樹(shù)。一個(gè) B 樹(shù)節(jié)點(diǎn)在占滿后,將分割(split)為兩個(gè)節(jié)點(diǎn)。如果兩個(gè)近鄰節(jié)點(diǎn)的利用率(occupancy)降至某個(gè)閾值以下時(shí),那么節(jié)點(diǎn)會(huì)合并(merge)。這意味著,各個(gè)葉子節(jié)點(diǎn)與根節(jié)點(diǎn)間是等距的,在查找時(shí)可以使用同樣的步數(shù)定位。
- 查找操作有對(duì)數(shù)時(shí)間復(fù)雜度保證。這一點(diǎn)使 B 樹(shù)成為數(shù)據(jù)庫(kù)索引的很好選擇,因?yàn)樵跀?shù)據(jù)庫(kù)中,查找時(shí)間是非常關(guān)鍵的。
- 支持可變數(shù)據(jù)結(jié)構(gòu)。插入、更新和刪除(以及隨后的節(jié)點(diǎn)分割和合并)是在磁盤(pán)上執(zhí)行的,實(shí)現(xiàn)就地(in-depth)更新需要一定的空間開(kāi)銷(xiāo)。B 樹(shù)可以組織為聚束索引,將實(shí)際數(shù)據(jù)存儲(chǔ)在葉子節(jié)點(diǎn)上,也可以使用非聚束索引,將數(shù)據(jù)存儲(chǔ)為堆文件。
本文還將介紹 B+ 樹(shù) 3。B+ 樹(shù)是 B 樹(shù)的一種變體,常用于數(shù)據(jù)庫(kù)存儲(chǔ)。與原始 B 樹(shù)相比,B+ 樹(shù)的不同之處在于:1. B+ 樹(shù)的葉子節(jié)點(diǎn)存儲(chǔ)值并形成一個(gè)額外的鏈接層。2.B+ 樹(shù)的內(nèi)部節(jié)點(diǎn)并不存儲(chǔ)值。
B 樹(shù)剖析
下面我們仔細(xì)查看 B 樹(shù)的構(gòu)建模塊,如圖 2 所示。B 樹(shù)具有多種節(jié)點(diǎn)類(lèi)型,包括根節(jié)點(diǎn)、內(nèi)部節(jié)點(diǎn)和葉子節(jié)點(diǎn)。根節(jié)點(diǎn)(頂端)是沒(méi)有父節(jié)點(diǎn)的節(jié)點(diǎn)(即它不是任何其它節(jié)點(diǎn)的子節(jié)點(diǎn))。內(nèi)部節(jié)點(diǎn)(中間)具有父節(jié)點(diǎn)和子節(jié)點(diǎn),它們連接了根節(jié)點(diǎn)和葉子節(jié)點(diǎn)。葉子節(jié)點(diǎn)(底端)保存數(shù)據(jù),它沒(méi)有子節(jié)點(diǎn)。圖 2 顯示的 B 樹(shù)的分支因子(branching factor)為 4,即具有四個(gè)指針,內(nèi)部節(jié)點(diǎn)有三個(gè)鍵值,葉子節(jié)點(diǎn)有四個(gè)鍵值對(duì)。
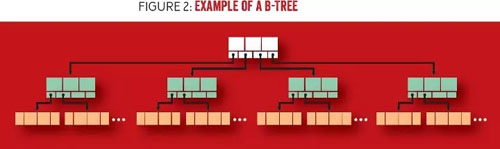
圖 2 例子:B 樹(shù)
標(biāo)識(shí)一個(gè) B 樹(shù),可使用如下指標(biāo):
- 分支因子:即指向子節(jié)點(diǎn)的指針數(shù)(N)。考慮存在指針,根節(jié)點(diǎn)和內(nèi)部節(jié)點(diǎn)***可保存 N-1 個(gè)鍵值。
- 利用率:***可用指針數(shù)中,當(dāng)前有多少指向子項(xiàng)的指針在用。例如,如果樹(shù)的分支因子是 N,節(jié)點(diǎn)當(dāng)前保持了 N/2 個(gè)指針,那么利用率就是 50%。
- 高度:B 樹(shù)的層數(shù),指明了在查找中需遍歷的指針個(gè)數(shù)。
樹(shù)中每個(gè)非葉子節(jié)點(diǎn)最多保持 N 個(gè)鍵(索引項(xiàng)),將樹(shù)分割為 N+1 個(gè)子樹(shù),這些子樹(shù)可用相應(yīng)的指針定位。在條目 Ki 中的指針 i 指向的子樹(shù)中,所有索引項(xiàng)是 Ki-1 <= Ksearched < Ki(其中 k 是一組鍵)。***個(gè)和***一個(gè)指針是特例,最左子節(jié)點(diǎn)指向的子樹(shù)中,所有的條目小于或等于 K0;最右子節(jié)點(diǎn)指向的子樹(shù)中,所有的條目大于 KN-1。葉子節(jié)點(diǎn)中包含的指針,可指向同一層中前一個(gè)或后一個(gè)節(jié)點(diǎn),形成近鄰節(jié)點(diǎn)的雙向鏈接列表。所有節(jié)點(diǎn)中,鍵總是排序的。
查找
在執(zhí)行查找時(shí),搜索將從根節(jié)點(diǎn)開(kāi)始,沿內(nèi)部節(jié)點(diǎn)遞歸下行至葉子層級(jí)。在每一層級(jí),通過(guò)追隨子節(jié)點(diǎn)指針,搜索空間可縮減到子樹(shù)范圍(該子樹(shù)包括搜索值)。圖 3 顯示的是 B 樹(shù)中的一次查找,即一次沿著兩個(gè)鍵間的指針由根到葉子的遍歷,一個(gè)指針大于或等于搜索項(xiàng),另一個(gè)指針小于搜索項(xiàng)。執(zhí)行一個(gè)點(diǎn)查詢(xún)(Point Query)時(shí),搜索在定位到葉子節(jié)點(diǎn)后結(jié)束。在范圍搜索中,會(huì)遍歷所找到葉子節(jié)點(diǎn)的鍵和值,然后是近鄰的葉子節(jié)點(diǎn),直到到達(dá)范圍的終點(diǎn)。
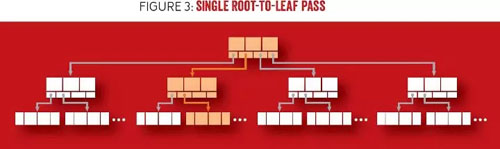
圖 3 單次由根到葉子的遍歷
從復(fù)雜性上看,B 樹(shù)保證了 log(n) 復(fù)雜度的查找,因?yàn)槿绾螐墓?jié)點(diǎn)中找到鍵中使用了二分查找法,如圖 4 所示。二分查找法易于解釋?zhuān)?dāng)從字典中搜索具有某個(gè)首字母的單詞時(shí),所有單詞是按字母順序排列的。首先選擇從確切的中間位置打開(kāi)字典。如果搜索字母在字母序上要“小于”(先出現(xiàn))打開(kāi)的字母,那么繼續(xù)在左半部份字典中搜索。否則,在詞典右半部份中搜索。然后繼續(xù)縮減剩余頁(yè)面范圍,通過(guò)減半并選擇搜索方向,直到找到所需的字母。每步將搜索空間減半,使查找呈對(duì)數(shù)時(shí)間復(fù)雜度。B 樹(shù)中的搜索具有對(duì)數(shù)時(shí)間復(fù)雜度,因?yàn)楣?jié)點(diǎn)層級(jí)鍵是排序的,并在查找匹配總使用了二分查找。這也是為什么在整個(gè)樹(shù)中保持高利用率和一致性是非常重要的。
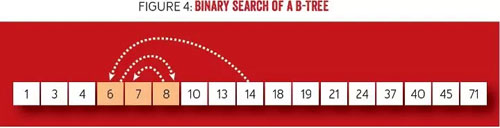
圖 4 B 樹(shù)的二分查找
插入、更新和刪除
執(zhí)行插入時(shí),***步是定位目標(biāo)葉子節(jié)點(diǎn)。在此可使用上面介紹的搜索算法。定位目標(biāo)節(jié)點(diǎn)后,鍵和值將添加到該節(jié)點(diǎn)中。如果葉子節(jié)點(diǎn)的空間不夠用,這種情況稱(chēng)為“溢出”(Overflow),葉子節(jié)點(diǎn)必須分割為兩個(gè)。分割的實(shí)現(xiàn)是通過(guò)分配一個(gè)新葉子,將原葉子節(jié)點(diǎn)中的半數(shù)元素移動(dòng)到新的葉子節(jié)點(diǎn),并在父節(jié)點(diǎn)中分配一個(gè)指向新葉子節(jié)點(diǎn)的指針。如果父節(jié)點(diǎn)中也沒(méi)有空余的空間,那么就在父節(jié)點(diǎn)層級(jí)執(zhí)行分割操作。操作將持續(xù)直至到達(dá)根節(jié)點(diǎn)。如果根節(jié)點(diǎn)溢出,節(jié)點(diǎn)內(nèi)容在新分配節(jié)點(diǎn)間分割。然后根節(jié)點(diǎn)自身將被覆蓋,以避免重新分配。這也意味著,樹(shù)(及樹(shù)的高度)的高度總是在分割根節(jié)點(diǎn)時(shí)增長(zhǎng)。
二、LSM 樹(shù)
日志結(jié)構(gòu)合并(LSM)樹(shù)是一種寫(xiě)優(yōu)化的數(shù)據(jù)結(jié)構(gòu),它是不可變的、駐留于磁盤(pán)的,適用于寫(xiě)操作比查找和檢索記錄更為頻繁的系統(tǒng)。由于 LSM 樹(shù)消除了隨機(jī)插入、更新和刪除,因此它得到了更多的關(guān)注。
LSM 樹(shù)剖析
為支持順序?qū)懀琇SM 樹(shù)在一個(gè)駐留內(nèi)存表(通常使用支持對(duì)數(shù)時(shí)間復(fù)雜度查找的數(shù)據(jù)結(jié)構(gòu)實(shí)現(xiàn),例如二分查找樹(shù)或跳表)中批量寫(xiě)入和更新,直至內(nèi)存表規(guī)模達(dá)到一個(gè)設(shè)定的閾值,這時(shí)再寫(xiě)入到磁盤(pán),該操作稱(chēng)為“刷新”(flush)。檢索數(shù)據(jù)需要搜索樹(shù)駐留磁盤(pán)的所有部分,檢查駐留內(nèi)存表,并在返回結(jié)果前合并內(nèi)容。圖 5 顯示了一個(gè) LSM 樹(shù)的結(jié)構(gòu),其中的駐留內(nèi)存表用于寫(xiě)入。一旦內(nèi)存表達(dá)到了一定規(guī)模大,其中經(jīng)排序的內(nèi)容就要就寫(xiě)入到磁盤(pán)。讀取時(shí)需要訪問(wèn)駐留磁盤(pán)和駐留內(nèi)存表,并需要一個(gè)合并過(guò)程去整合數(shù)據(jù)。
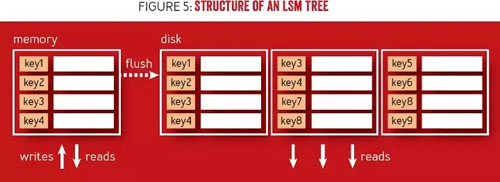
圖 5 LSM 樹(shù)的結(jié)構(gòu)
排序字符串表(SSTable)
現(xiàn)代多種系統(tǒng)中,例如 RocksDB 和 Apache Cassandra,將 LSM 樹(shù)的駐留磁盤(pán)表實(shí)現(xiàn)為一種 SSTable(排序字符串表)。SSTable 具有簡(jiǎn)單性(易于寫(xiě)入、搜索和讀取)及合并屬性(在合并期間,源 SSTable 掃描和合并結(jié)果寫(xiě)是順序操作)。
SSTable 是一種不可變的、駐留磁盤(pán)的排序數(shù)據(jù)結(jié)構(gòu)。如圖 6 所示,SSTable 在結(jié)構(gòu)上可分為兩個(gè)部分,即數(shù)據(jù)塊和索引塊。數(shù)據(jù)塊是由順序?qū)懭氲奈ㄒ绘I值對(duì)組成,鍵值對(duì)按鍵排序。索引塊中的鍵包含映射到數(shù)據(jù)塊指針,指針指向?qū)嶋H記錄的位置。索引通常實(shí)現(xiàn)為針對(duì)快速搜索優(yōu)化的格式,例如 B 樹(shù),或是對(duì)于點(diǎn)查詢(xún)使用哈希表。SSTable 中的每個(gè)值項(xiàng)具有一個(gè)與之相關(guān)聯(lián)的時(shí)間戳。時(shí)間戳指定了插入和更新的寫(xiě)入時(shí)間(通常不做區(qū)分),以及刪除的移除時(shí)間。
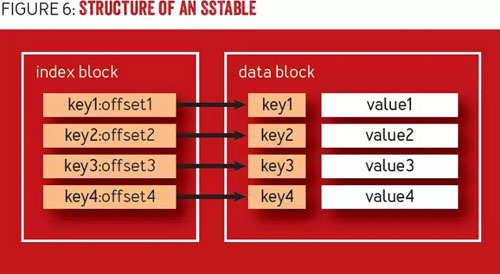
圖 6 SSTable 的結(jié)構(gòu)
SSTable 具有一些很好的特性:
- 點(diǎn)查詢(xún)(即根據(jù)鍵找到一個(gè)值)可通過(guò)查找主索引快速完成。
- 掃描(即在指定鍵范圍內(nèi)迭代所有鍵值對(duì))可以高效完成,僅通過(guò)在數(shù)據(jù)塊內(nèi)順序讀取鍵值對(duì)。
SSTable 給出了一段時(shí)間內(nèi)所有數(shù)據(jù)庫(kù)操作的快照。因?yàn)?SSTable 是由駐留內(nèi)存表的刷新操作創(chuàng)建的,該表作為此時(shí)期內(nèi)對(duì)數(shù)據(jù)庫(kù)狀態(tài)操作的一個(gè)緩沖區(qū)。
查找
檢索數(shù)據(jù)時(shí),需要搜索磁盤(pán)上所有的 SSTable,檢查駐留內(nèi)存表,并在返回結(jié)果前合并其中的內(nèi)容。讀操作需要合并過(guò)程,因?yàn)樗阉鞯臄?shù)據(jù)可能存在于多個(gè) SSTable 中。
為確保實(shí)現(xiàn)刪除和更新,也必須要合并步驟。刪除時(shí),會(huì)在 LSM 樹(shù)中插入一個(gè)占位符,通常稱(chēng)為“墓碑”(tombstone)。墓碑用于標(biāo)記被刪除的鍵。類(lèi)似地,更新時(shí)也僅是增加一個(gè)具有更遲時(shí)間戳的記錄。在讀取期間,將跳過(guò)被標(biāo)記為刪除的記錄,不返回給客戶。更新中也采取類(lèi)似的做法,對(duì)于兩個(gè)具有同一鍵的記錄,只返回時(shí)間戳更晚的記錄。圖 7 顯示了合并是如何整合存儲(chǔ)在獨(dú)立表中具有同一鍵的數(shù)據(jù)。如圖所示,Alex 的記錄寫(xiě)入的時(shí)間戳為 100,更新了電話后記錄的時(shí)間戳為 200。John 的記錄是被刪除的。其它兩個(gè)條目保持原狀,因?yàn)樗鼈儾⑽醋鰳?biāo)記。

圖 7 例子:合并步驟
為減少需搜索的 SSTable 數(shù)量,避免因?yàn)樗阉髂硞€(gè)鍵而檢查每個(gè) SSTable,一些存儲(chǔ)系統(tǒng)使用了一種稱(chēng)為布隆濾波器 10 的數(shù)據(jù)結(jié)構(gòu)。布隆濾波器是一種概率數(shù)據(jù)結(jié)構(gòu),可用于檢測(cè)一個(gè)元素是否屬于一個(gè)集合的成員。它會(huì)產(chǎn)生誤報(bào)匹配(即指出元素是集合的成員,但是事實(shí)上并不是),但是不會(huì)產(chǎn)生漏報(bào)(即如果返回結(jié)果是不匹配,那么該元素一定不是集合的成員)。換句話說(shuō),布隆濾波器可用于告知一個(gè)鍵是否“可能位于 SSTable 中”,或是“絕對(duì)不在 SSTable 中”。如果一個(gè) SSTable 被布隆濾波器返回為不匹配,那么將在查詢(xún)中跳過(guò)。
維護(hù) LSM 樹(shù)
鑒于 SSTable 是不可變的、是順序?qū)懙模⑶也⑽幢A艟偷馗牡目臻g。這意味著,插入、更新和刪除操作需要重寫(xiě)整個(gè)文件。所有修改數(shù)據(jù)庫(kù)狀態(tài)的操作,是在內(nèi)存駐留表中“批量處理”的。隨時(shí)間的推進(jìn),駐留磁盤(pán)表的數(shù)量將會(huì)增長(zhǎng)(對(duì)應(yīng)同一鍵的數(shù)據(jù)可能會(huì)位于多個(gè)文件、同一記錄的多個(gè)版本,或標(biāo)記為刪除的冗余記錄中),讀取將繼續(xù)變得代價(jià)更為昂貴。
為降低讀取的代價(jià)、整合被標(biāo)記的記錄空間并降低駐留磁盤(pán)表的數(shù)量,LSM 樹(shù)需要一個(gè)緊縮(compaction)過(guò)程。緊縮過(guò)程從磁盤(pán)讀取整個(gè) SSTable,并合并它們。因?yàn)?SSTable 是按鍵排序的,緊縮過(guò)程的工作方式類(lèi)似于歸并排序,所以該操作也是非常高效。記錄從多個(gè)數(shù)據(jù)源順序讀取,合并的輸出可以即刻順序地附加到結(jié)果文件中。歸并排序的一個(gè)優(yōu)點(diǎn)是工作高效,即便是對(duì)于歸并無(wú)法放入內(nèi)存中的大型文件。生成的表將保持原始 SSTable 的排序。
在緊縮過(guò)程中,合并后的 SSTable 將被拋棄,并被更“緊縮”的表替代,如圖 8 所示。緊縮操作輸入為多個(gè) SSTable,輸出為合并后的一個(gè)表。一些數(shù)據(jù)庫(kù)系統(tǒng)在邏輯上將同一規(guī)模的表分組為同一“層級(jí)”,并在某個(gè)層級(jí)中的表數(shù)量足夠多時(shí),開(kāi)始合并過(guò)程。緊縮減少了必須要處理的 SSTable 數(shù)量,使查詢(xún)更加高效。

圖 8 緊縮過(guò)程
原子性和持久性
為實(shí)現(xiàn) I/O 操作數(shù)量減少和順序化,B 樹(shù)和 LSM 樹(shù)均在更新實(shí)際發(fā)生前做內(nèi)存中的批處理。這意味著,一旦發(fā)生失敗,不能保證數(shù)據(jù)的完整性,而且也不能確保原子性(指一組更改的應(yīng)用是原子化的,如同單個(gè)操作一樣,或者全部應(yīng)用,或者全不應(yīng)用)和持久性(確保在進(jìn)程崩潰或掉電時(shí),數(shù)據(jù)處于一致性存儲(chǔ)中)。
為解決這個(gè)問(wèn)題,很多現(xiàn)代存儲(chǔ)系統(tǒng)使用了 WAL 技術(shù)(預(yù)寫(xiě)式日志,Write-Ahead Logging)。WAL 的主要理念是所有數(shù)據(jù)庫(kù)狀態(tài)修改首先持久保持在位于磁盤(pán)上的只添加日志中。一旦操作過(guò)程中發(fā)生進(jìn)程崩潰,就會(huì)重執(zhí)行日志,以確保沒(méi)有數(shù)據(jù)丟失,實(shí)現(xiàn)所有更改的原子化。
B 樹(shù)中,使用 WAL 可理解為更改只有做日志后,才寫(xiě)到數(shù)據(jù)文件中。通常情況下,B 樹(shù)存儲(chǔ)系統(tǒng)的日志規(guī)模相對(duì)較小。一旦更改應(yīng)用到持久存儲(chǔ),就會(huì)被丟棄。WAL 作為一種對(duì)未日志化(in-flight)操作的備份機(jī)制,即應(yīng)用到數(shù)據(jù)頁(yè)面的任何更改都可以從日志記錄重做。
LSM 樹(shù)中,WAL 用于持久化那些操作了內(nèi)存表但是并未完全刷新到磁盤(pán)的更改。一旦內(nèi)存表完全刷新并切換,讀取操作可以在新創(chuàng)建的 SSTable 上完成,就可以丟棄保持了刷新內(nèi)存表數(shù)據(jù)的 WAL 段。
總結(jié)
B 樹(shù)和 LSM 樹(shù)結(jié)構(gòu)上的***差別之一,在于優(yōu)化的目的,以及優(yōu)化的意義。
下面對(duì) B 樹(shù)和 LSM 樹(shù)做一個(gè)對(duì)比。總而言之,B 樹(shù)具有如下屬性:
- B 樹(shù)是可變的,這支持通過(guò)引入一些空間開(kāi)銷(xiāo),以及更為關(guān)聯(lián)的寫(xiě)路徑,實(shí)現(xiàn)就地更新。B 樹(shù)并不需要完全的文件重寫(xiě)或多源合并。
- B 樹(shù)是讀優(yōu)化的。即 B 樹(shù)不需要從多個(gè)源讀取(因此也不需要此后的合并操作),這簡(jiǎn)化了讀路徑。
- 寫(xiě)可能會(huì)觸發(fā)節(jié)點(diǎn)的級(jí)聯(lián)分割,這會(huì)使一些寫(xiě)操作更昂貴。
- B 樹(shù)是針對(duì)分頁(yè)(塊存儲(chǔ))環(huán)境優(yōu)化的,其中不存在字節(jié)地址。They are optimized for paged environments (block storage), where byte addressing is not possible.
- 雖然也需要重寫(xiě),但是通常情況下 B 樹(shù)存儲(chǔ)要比 LSM 樹(shù)存儲(chǔ)需要更少的維護(hù)。
- 并發(fā)訪問(wèn)需要讀 / 寫(xiě)隔離,其中一系列的鎖和閂(latch)。
LSM 樹(shù)具有如下特性:
- LSM 樹(shù)是不可寫(xiě)的。SSTable 是一次性寫(xiě)入磁盤(pán)的,永不更新。緊縮操作通過(guò)從多個(gè)數(shù)據(jù)文件移除條目,并合并具有相同鍵的數(shù)據(jù),實(shí)現(xiàn)空間的整合。在緊縮過(guò)程中,已合并的 SSTable 將被丟棄,并在成功合并后移除。不可寫(xiě)提供的另一個(gè)有用特性,就是刷新后的表可并發(fā)訪問(wèn)。
- LSM 是寫(xiě)優(yōu)化的。這意味著寫(xiě)入操作將被緩存,并順序地刷新到磁盤(pán)中,潛在地支持磁盤(pán)上的空間本地性。
- 讀操作可能需要從多個(gè)數(shù)據(jù)源訪問(wèn)數(shù)據(jù)。因?yàn)椴煌瑫r(shí)間寫(xiě)入的具有相同鍵的數(shù)據(jù),可能會(huì)落在不同的數(shù)據(jù)文件中。記錄在返回給客戶前,必須經(jīng)過(guò)合并過(guò)程。
- LSM 樹(shù)需要做維護(hù)和緊縮,因?yàn)榫彺娴膶?xiě)入操作將被刷新到磁盤(pán)。
三、存儲(chǔ)系統(tǒng)的評(píng)估
在存儲(chǔ)系統(tǒng)的開(kāi)發(fā)中,總是需要考慮一些挑戰(zhàn)和因素。優(yōu)化目標(biāo)對(duì)存儲(chǔ)系統(tǒng)選擇有著切實(shí)的影響。如果可以在寫(xiě)操作上花費(fèi)更多時(shí)間,那么就可以部署針對(duì)更高效讀操作的結(jié)構(gòu),預(yù)留額外的空間用于就地更新。這有利于實(shí)現(xiàn)更快的寫(xiě)操作,并支持將數(shù)據(jù)緩存在內(nèi)存中,以確保順序的寫(xiě)操作。但是,所有這些是不可能一次性達(dá)成的。我們理想中的存儲(chǔ)系統(tǒng)具有***的讀代價(jià)、***的寫(xiě)代價(jià),并沒(méi)有其它開(kāi)銷(xiāo)。但在實(shí)踐中,數(shù)據(jù)結(jié)構(gòu)需折衷考慮多個(gè)因素。理解這些折衷考慮是非常重要的。
哈佛大學(xué) DASlab(數(shù)據(jù)系統(tǒng)實(shí)驗(yàn)室)的研究人員總結(jié)了數(shù)據(jù)庫(kù)系統(tǒng)優(yōu)化的三個(gè)關(guān)鍵參數(shù):讀開(kāi)銷(xiāo)、更新開(kāi)銷(xiāo)和內(nèi)存開(kāi)銷(xiāo),統(tǒng)稱(chēng)為“RUM”。對(duì)于特定的用例,理解這些參數(shù)中哪個(gè)是最重要的,將對(duì)數(shù)據(jù)結(jié)構(gòu)、訪問(wèn)方法,甚至是特定工作負(fù)載的適用性產(chǎn)生影響,因?yàn)樗惴ㄐ枰鶕?jù)特定的用例做出調(diào)整。
“RUM 假說(shuō)”(http://daslab.seas.harvard.edu/rum-conjecture/)2 指出,如果對(duì) RUM 中的兩項(xiàng)設(shè)置上限,那么也會(huì)對(duì)第三項(xiàng)設(shè)置下限。例如,B 樹(shù)是讀優(yōu)化的,代價(jià)是寫(xiě)開(kāi)銷(xiāo),以及預(yù)留了額外的空間(因而導(dǎo)致了內(nèi)存開(kāi)銷(xiāo))。LSM 樹(shù)空間開(kāi)銷(xiāo)更少,代價(jià)是在讀操作期間必須訪問(wèn)多個(gè)駐留磁盤(pán)表,從而引入了讀開(kāi)銷(xiāo)。這三個(gè)參數(shù)形成了一個(gè)完全三角形,改進(jìn)其中的一項(xiàng),意味著對(duì)其它項(xiàng)的折衷考慮。圖 9 展示了 RUM 假說(shuō)。
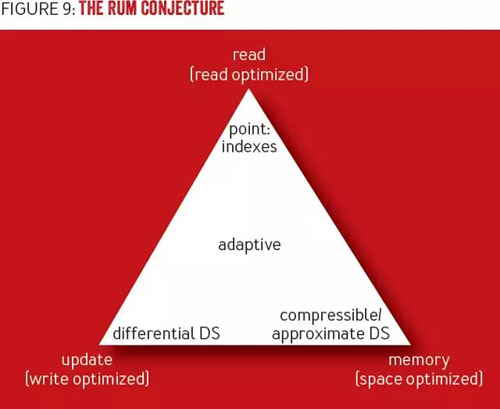
圖 9 RUM 假說(shuō)
B 樹(shù)是針對(duì)讀性能優(yōu)化的。索引的布局方式使得遍歷樹(shù)所需的磁盤(pán)訪問(wèn)次數(shù)最小化。定位數(shù)據(jù)時(shí),只需訪問(wèn)單個(gè)索引文件。這是通過(guò)保持索引文件可寫(xiě)而實(shí)現(xiàn)的。可寫(xiě)增加了寫(xiě)入放大(Write Amplification)問(wèn)題,該問(wèn)題由節(jié)點(diǎn)分割、合并、重定位和碎片化 / 不平衡相關(guān)維護(hù)等導(dǎo)致。為緩解更新的代價(jià),并降低分割的次數(shù),B 樹(shù)在各個(gè)層級(jí)的節(jié)點(diǎn)中預(yù)留了額外的空閑空間。這有助于推遲發(fā)生寫(xiě)入放大問(wèn)題,直至節(jié)點(diǎn)空間滿。簡(jiǎn)而言之,B 樹(shù)是在更新和內(nèi)存開(kāi)銷(xiāo)間做了權(quán)衡,目的是實(shí)現(xiàn)更好的讀性能。
LSM 樹(shù)針對(duì)寫(xiě)性能優(yōu)化。無(wú)論更新或是刪除,都需要定位數(shù)據(jù)在磁盤(pán)上的位置(B 樹(shù)也需要)。LSM 樹(shù)通過(guò)在內(nèi)存駐留表緩存所有插入、更新和刪除操作以保證順序?qū)憽_@樣做的代價(jià)是更高的維護(hù)代價(jià)、需要緊縮操作(緊縮操作只是一種緩解不斷增長(zhǎng)的讀代價(jià)、減少駐留磁盤(pán)表數(shù)量的方式),以及更昂貴的讀(因?yàn)閿?shù)據(jù)必須從多個(gè)源讀取并合并)。同時(shí),LSM 樹(shù)不保持任何空閑空間,這消除了一些內(nèi)存開(kāi)銷(xiāo)(不同于 B 樹(shù)節(jié)點(diǎn)平均利用率為 70%,就地更新需要一定的開(kāi)銷(xiāo))。由于 LSM 樹(shù)最終文件是不寫(xiě)的,為實(shí)現(xiàn)更好的使用率,需要支持塊壓縮。簡(jiǎn)而言之,LSM 樹(shù)是在讀性能和維護(hù)更好寫(xiě)性能和低內(nèi)存開(kāi)銷(xiāo)間的權(quán)衡。
對(duì)于每種所需的特性,都會(huì)存在針對(duì)此特性?xún)?yōu)化的數(shù)據(jù)結(jié)構(gòu)。如果使用相適應(yīng)的數(shù)據(jù)結(jié)構(gòu)以支持更好的讀性能,那么代價(jià)是更高的維護(hù)代價(jià)。添加元數(shù)據(jù)有利于遍歷(例如分散層疊(fractional cascading)),這將影響寫(xiě)的時(shí)間,并占用空間,但是可以改進(jìn)讀的時(shí)間。使用壓縮技術(shù) (例如,Gorilla 壓縮 6、delta encoding 等算法) 可優(yōu)化內(nèi)存效率,將對(duì)寫(xiě)時(shí)數(shù)據(jù)打包和讀時(shí)數(shù)據(jù)解包添加一些開(kāi)銷(xiāo)。有時(shí),我們可以權(quán)衡功能和效率。例如,堆文件和哈希索引由于文件格式的簡(jiǎn)單性,可以給出很好的性能保證,以及更小的空間開(kāi)銷(xiāo),但代價(jià)是只能支持執(zhí)行點(diǎn)查詢(xún)。我們還也可以通過(guò)使用近似數(shù)據(jù)結(jié)構(gòu),例如布隆濾波器、HyperLogLog、Count-Min sketch 等,權(quán)衡空間精度和效率。
讀、更新和內(nèi)存這三種可調(diào)整的開(kāi)銷(xiāo),有助于我們?cè)u(píng)估數(shù)據(jù)庫(kù),并更深入理解數(shù)據(jù)庫(kù)適合何種工作負(fù)載。三者非常直觀,很容易將存儲(chǔ)系統(tǒng)排序在一個(gè)桶中,給出執(zhí)行情況的猜測(cè),進(jìn)而通過(guò)深入的測(cè)試去驗(yàn)證這一假設(shè)。
當(dāng)然,評(píng)估存儲(chǔ)系統(tǒng)時(shí)還存在其它一些重要的因素,例如維護(hù)代價(jià)、操作簡(jiǎn)單性、系統(tǒng)需求、對(duì)頻繁更新和刪除的適用性、訪問(wèn)模式等。RUM 假說(shuō)僅是有助于給出直觀感覺(jué),并對(duì)最初方向提供經(jīng)驗(yàn)法則。理解我們自己的工作負(fù)載,這是邁向構(gòu)建可擴(kuò)展的后端系統(tǒng)的***步。
在不同的實(shí)現(xiàn)中,一些因素可能會(huì)發(fā)生變化。即便是使用類(lèi)似存儲(chǔ)設(shè)計(jì)原則的兩個(gè)數(shù)據(jù)庫(kù)間,最終的表現(xiàn)也可能會(huì)完全不同。數(shù)據(jù)庫(kù)是一個(gè)復(fù)雜的系統(tǒng),其中有很多變動(dòng)因素。數(shù)據(jù)庫(kù)也是很多應(yīng)用中重要且不可分割的部分。性能上的權(quán)衡有助于我們一窺數(shù)據(jù)庫(kù)的底層機(jī)制。了解底層數(shù)據(jù)結(jié)構(gòu)及內(nèi)部原理間的差異,有助于我們從中做出***的選擇。
參考文獻(xiàn)
Comer, D. 1979. The ubiquitous B-tree. Computing Surveys 11(2); 121-137;
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.96.6637.
哈佛大學(xué) DASlab 實(shí)驗(yàn)室. The RUM Conjecture;
http://daslab.seas.harvard.edu/rum-conjecture/.
Graefe, G. 2011. Modern B-tree techniques. Foundations and Trends in Databases 3(4): 203-402;
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.219.7269&rep=rep1&type=pdf.
MySQL 5.7 參考手冊(cè). InnoDB 索引的物理結(jié)構(gòu) ;
https://dev.mysql.com/doc/refman/5.7/en/innodb-physical-structure.html.
O'Neil, P., Cheng, E., Gawlick, D., O'Neil, E. 1996. The log-structured merge-tree. Acta Informatica 33(4): 351-385;
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.44.2782.
Pelkonen, T., Franklin, S., Teller, J., Cavallaro, P., Huang, Q., Meza, J., Veeraraghavan, K. 2015. Gorilla: a fast, scalable, in-memory time series database. Proceedings of the VLDB Endowment 8(12): 1816-1827;
http://www.vldb.org/pvldb/vol8/p1816-teller.pdf.
Suzuki, H. 2015-2018. The internals of PostgreSQL;
http://www.interdb.jp/pg/pgsql01.html.
Apple HFS Plus Volume 格式 ;
https://developer.apple.com/legacy/library/technotes/tn/tn1150.html#BTrees
Mathur, A., Cao, M., Bhattacharya, S., Dilger, A., Tomas, A., Vivier, L. (2007). The new ext4 filesystem: current status and future plans. Proceedings of the Linux Symposium. Ottawa, Canada: Red Hat.
Bloom, B. H. (1970), Space/time trade-offs in hash coding with allowable errors, Communications of the ACM, 13 (7): 422-426











