Spark核心技術原理透視一(Spark運行原理)
在大數據領域,只有深挖數據科學領域,走在學術前沿,才能在底層算法和模型方面走在前面,從而占據領先地位。
Spark的這種學術基因,使得它從一開始就在大數據領域建立了一定優勢。無論是性能,還是方案的統一性,對比傳統的Hadoop,優勢都非常明顯。Spark提供的基于RDD的一體化解決方案,將MapReduce、Streaming、SQL、Machine Learning、Graph Processing等模型統一到一個平臺下,并以一致的API公開,并提供相同的部署方案,使得Spark的工程應用領域變得更加廣泛。本文主要分以下章節:
- 一、Spark專業術語定義
- 二、Spark運行基本流程
- 三、Spark運行架構特點
- 四、Spark核心原理透視
一、Spark專業術語定義
1、Application:Spark應用程序
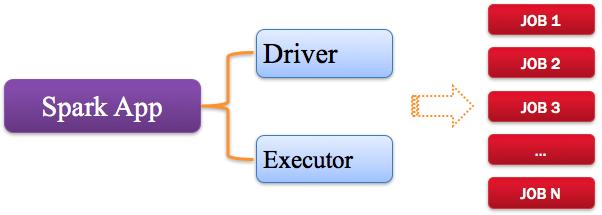
指的是用戶編寫的Spark應用程序,包含了Driver功能代碼和分布在集群中多個節點上運行的Executor代碼。
Spark應用程序,由一個或多個作業JOB組成,如下圖所示:
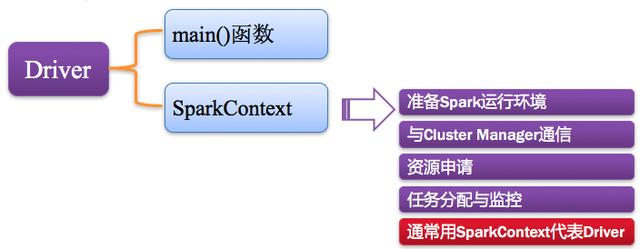
2、Driver:驅動程序
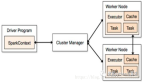
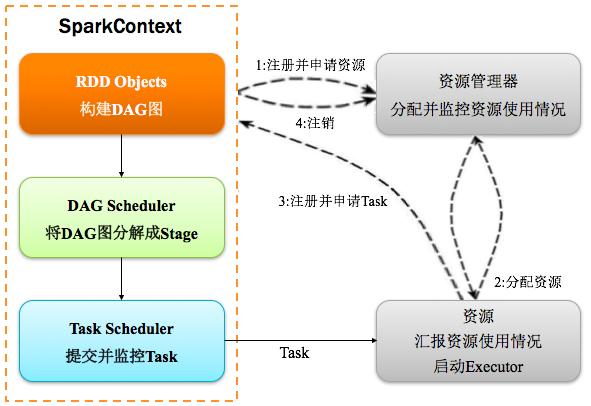
Spark中的Driver即運行上述Application的Main()函數并且創建SparkContext,其中創建SparkContext的目的是為了準備Spark應用程序的運行環境。在Spark中由SparkContext負責和ClusterManager通信,進行資源的申請、任務的分配和監控等;當Executor部分運行完畢后,Driver負責將SparkContext關閉。通常SparkContext代表Driver,如下圖所示:
3、Cluster Manager:資源管理器
指的是在集群上獲取資源的外部服務,常用的有:Standalone,Spark原生的資源管理器,由Master負責資源的分配;Haddop Yarn,由Yarn中的ResearchManager負責資源的分配;Messos,由Messos中的Messos Master負責資源管理,如下圖所示:

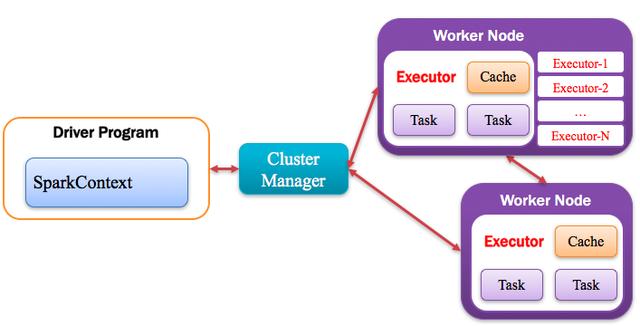
4、Executor:執行器
Application運行在Worker節點上的一個進程,該進程負責運行Task,并且負責將數據存在內存或者磁盤上,每個Application都有各自獨立的一批Executor,如下圖所示:
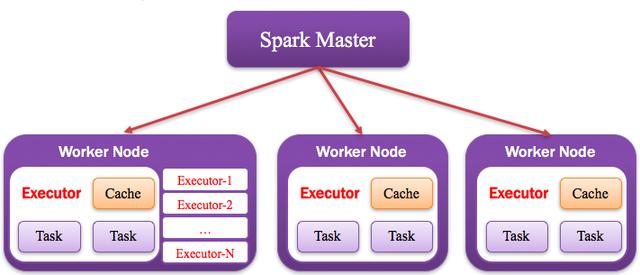
5、Worker:計算節點
集群中任何可以運行Application代碼的節點,類似于Yarn中的NodeManager節點。在Standalone模式中指的就是通過Slave文件配置的Worker節點,在Spark on Yarn模式中指的就是NodeManager節點,在Spark on Messos模式中指的就是Messos Slave節點,如下圖所示:
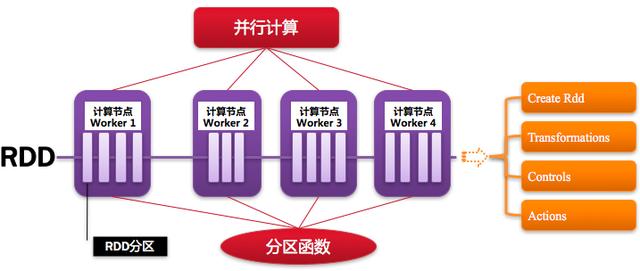
6、RDD:彈性分布式數據集
Resillient Distributed Dataset,Spark的基本計算單元,可以通過一系列算子進行操作(主要有Transformation和Action操作),如下圖所示:
7、窄依賴
父RDD每一個分區最多被一個子RDD的分區所用;表現為一個父RDD的分區對應于一個子RDD的分區,或兩個父RDD的分區對應于一個子RDD 的分區。如圖所示:
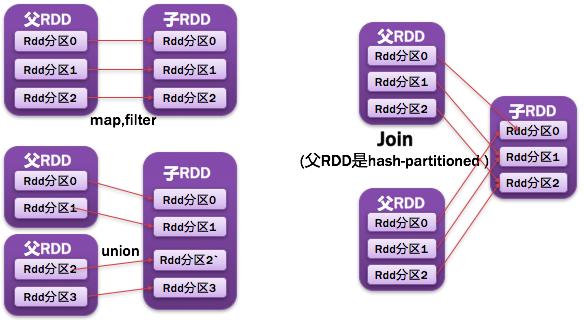
8、寬依賴
父RDD的每個分區都可能被多個子RDD分區所使用,子RDD分區通常對應所有的父RDD分區。如圖所示:
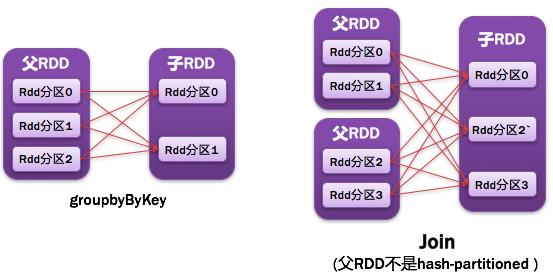
常見的窄依賴有:map、filter、union、mapPartitions、mapValues、join(父RDD是hash-partitioned :如果JoinAPI之前被調用的RDD API是寬依賴(存在shuffle), 而且兩個join的RDD的分區數量一致,join結果的rdd分區數量也一樣,這個時候join api是窄依賴)。
常見的寬依賴有groupByKey、partitionBy、reduceByKey、join(父RDD不是hash-partitioned :除此之外的,rdd 的join api是寬依賴)。
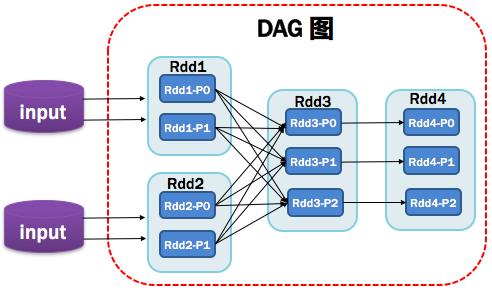
9、DAG:有向無環圖
Directed Acycle graph,反應RDD之間的依賴關系,如圖所示:
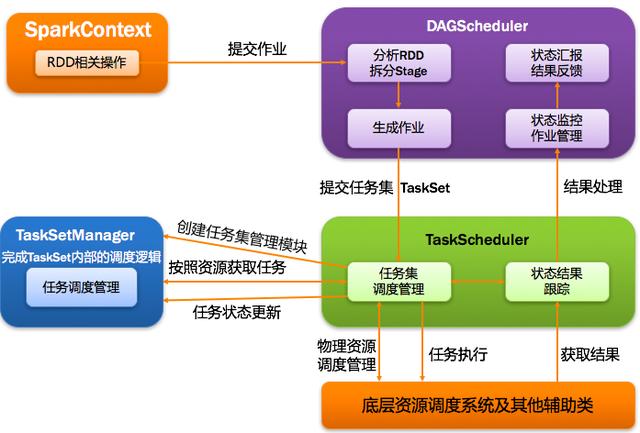
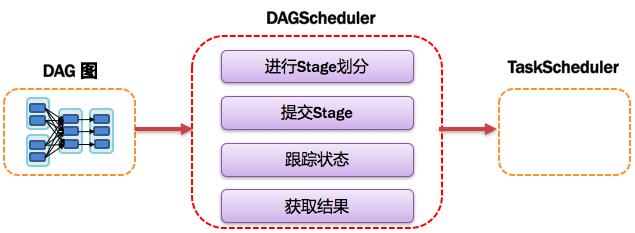
10、DAGScheduler:有向無環圖調度器
基于DAG劃分Stage 并以TaskSet的形勢提交Stage給TaskScheduler;負責將作業拆分成不同階段的具有依賴關系的多批任務;最重要的任務之一就是:計算作業和任務的依賴關系,制定調度邏輯。在SparkContext初始化的過程中被實例化,一個SparkContext對應創建一個DAGScheduler。
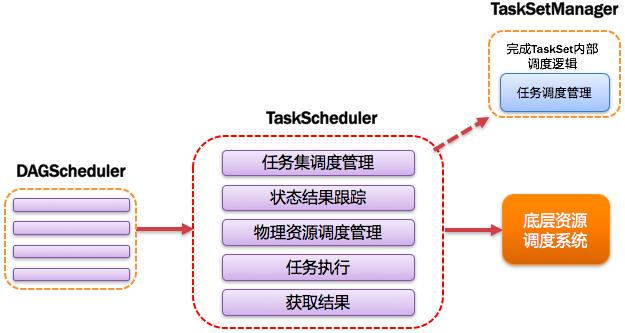
11、TaskScheduler:任務調度器
將Taskset提交給worker(集群)運行并回報結果;負責每個具體任務的實際物理調度。如圖所示:
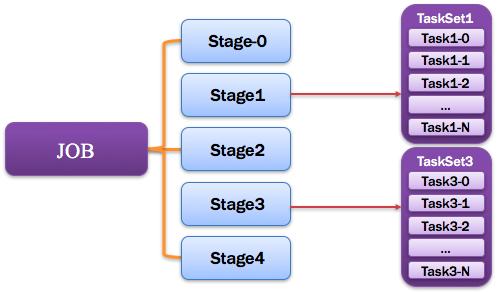
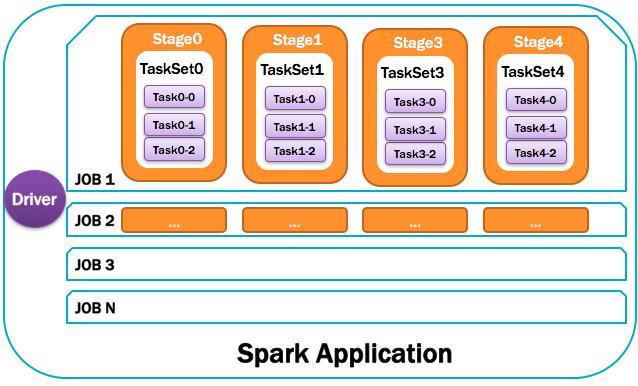
12、Job:作業
由一個或多個調度階段所組成的一次計算作業;包含多個Task組成的并行計算,往往由Spark Action催生,一個JOB包含多個RDD及作用于相應RDD上的各種Operation。如圖所示:
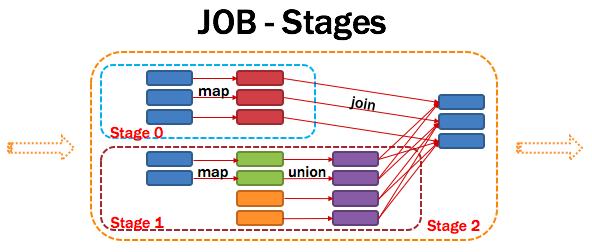
13、Stage:調度階段
一個任務集對應的調度階段;每個Job會被拆分很多組Task,每組任務被稱為Stage,也可稱TaskSet,一個作業分為多個階段;Stage分成兩種類型ShuffleMapStage、ResultStage。如圖所示:
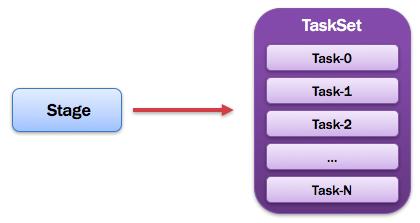
14、TaskSet:任務集
由一組關聯的,但相互之間沒有Shuffle依賴關系的任務所組成的任務集。如圖所示:
提示:
- 一個Stage創建一個TaskSet;
- 為Stage的每個Rdd分區創建一個Task,多個Task封裝成TaskSet
15、Task:任務
被送到某個Executor上的工作任務;單個分區數據集上的最小處理流程單元。如圖所示:
總體如圖所示:
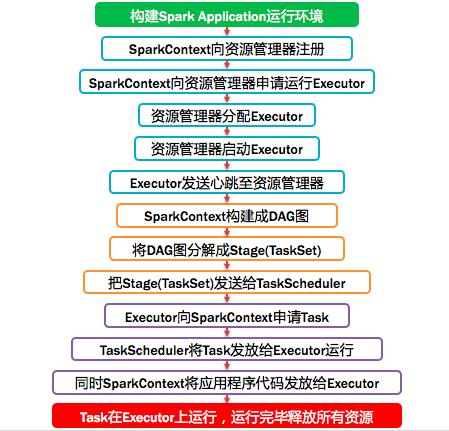
二、Spark運行基本流程
三、Spark運行架構特點
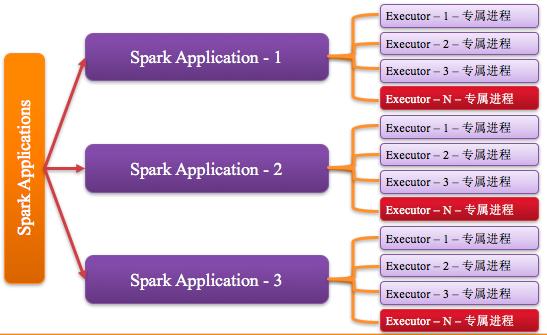
1、Executor進程專屬
每個Application獲取專屬的executor進程,該進程在Application期間一直駐留,并以多線程方式運行tasks。Spark Application不能跨應用程序共享數據,除非將數據寫入到外部存儲系統。如圖所示:
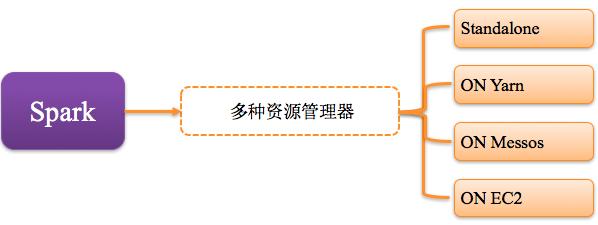
2、支持多種資源管理器
Spark與資源管理器無關,只要能夠獲取executor進程,并能保持相互通信就可以了,Spark支持資源管理器包含: Standalone、On Mesos、On YARN、Or On EC2。如圖所示:
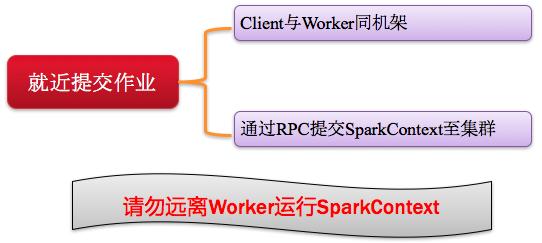
3、Job提交就近原則
提交SparkContext的Client應該靠近Worker節點(運行Executor的節點),***是在同一個Rack(機架)里,因為Spark Application運行過程中SparkContext和Executor之間有大量的信息交換;如果想在遠程集群中運行,***使用RPC將SparkContext提交給集群,不要遠離Worker運行SparkContext。如圖所示:
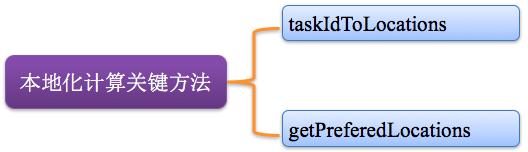
4、移動程序而非移動數據的原則執行
Task采用了數據本地性和推測執行的優化機制。關鍵方法:taskIdToLocations、getPreferedLocations。如圖所示:
四、Spark核心原理透視
1、計算流程
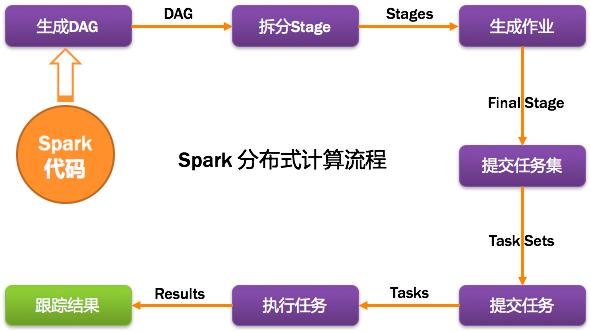
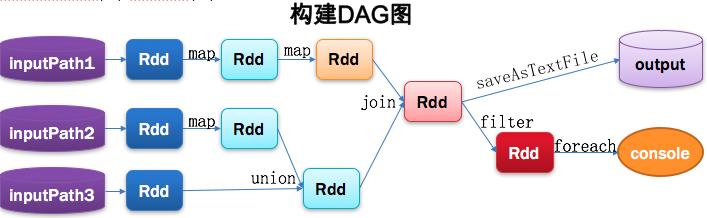
2、從代碼構建DAG圖
Spark program
- Val lines1 = sc.textFile(inputPath1). map(···)). map(···)
- Val lines2 = sc.textFile(inputPath2) . map(···)
- Val lines3 = sc.textFile(inputPath3)
- Val dtinone1 = lines2.union(lines3)
- Val dtinone = lines1.join(dtinone1)
- dtinone.saveAsTextFile(···)
- dtinone.filter(···).foreach(···)
Spark的計算發生在RDD的Action操作,而對Action之前的所有Transformation,Spark只是記錄下RDD生成的軌跡,而不會觸發真正的計算。
Spark內核會在需要計算發生的時刻繪制一張關于計算路徑的有向無環圖,也就是DAG。
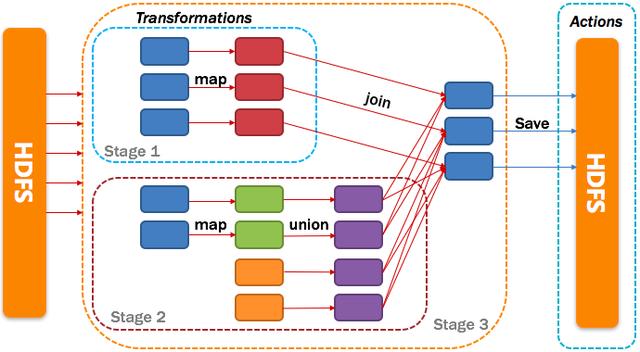
3、將DAG劃分為Stage核心算法
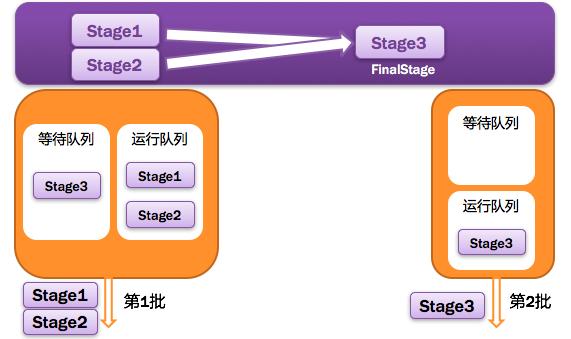
Application多個job多個Stage:Spark Application中可以因為不同的Action觸發眾多的job,一個Application中可以有很多的job,每個job是由一個或者多個Stage構成的,后面的Stage依賴于前面的Stage,也就是說只有前面依賴的Stage計算完畢后,后面的Stage才會運行。
劃分依據:Stage劃分的依據就是寬依賴,何時產生寬依賴,reduceByKey, groupByKey等算子,會導致寬依賴的產生。
核心算法:從后往前回溯,遇到窄依賴加入本stage,遇見寬依賴進行Stage切分。Spark內核會從觸發Action操作的那個RDD開始從后往前推,首先會為***一個RDD創建一個stage,然后繼續倒推,如果發現對某個RDD是寬依賴,那么就會將寬依賴的那個RDD創建一個新的stage,那個RDD就是新的stage的***一個RDD。然后依次類推,繼續繼續倒推,根據窄依賴或者寬依賴進行stage的劃分,直到所有的RDD全部遍歷完成為止。
4、將DAG劃分為Stage剖析
從HDFS中讀入數據生成3個不同的RDD,通過一系列transformation操作后再將計算結果保存回HDFS。可以看到這個DAG中只有join操作是一個寬依賴,Spark內核會以此為邊界將其前后劃分成不同的Stage. 同時我們可以注意到,在圖中Stage2中,從map到union都是窄依賴,這兩步操作可以形成一個流水線操作,通過map操作生成的partition可以不用等待整個RDD計算結束,而是繼續進行union操作,這樣大大提高了計算的效率。
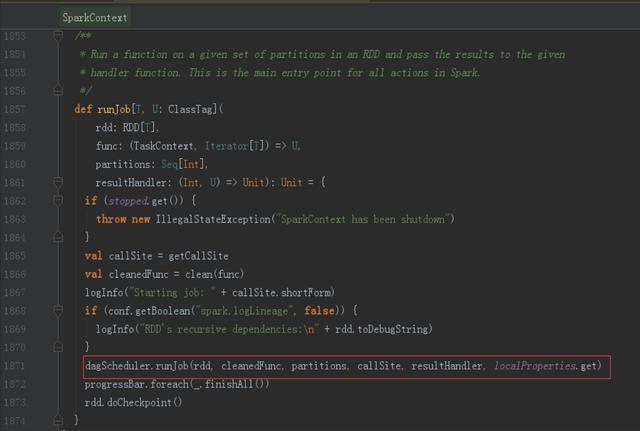
5、相關代碼
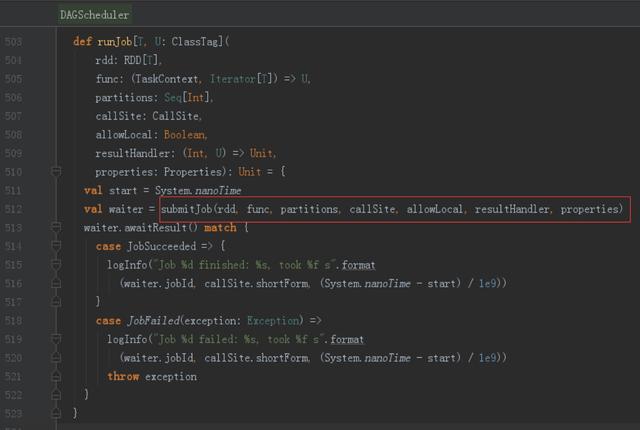
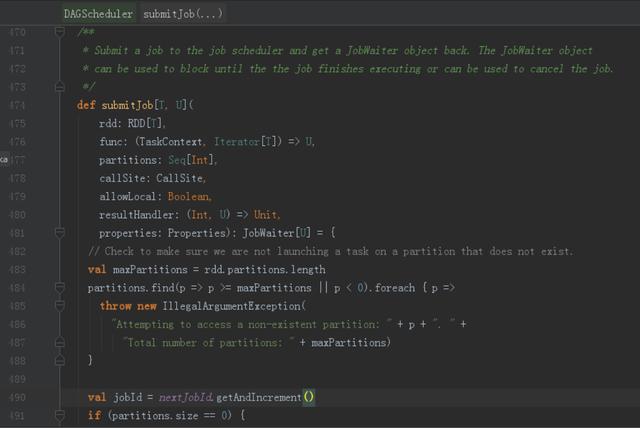
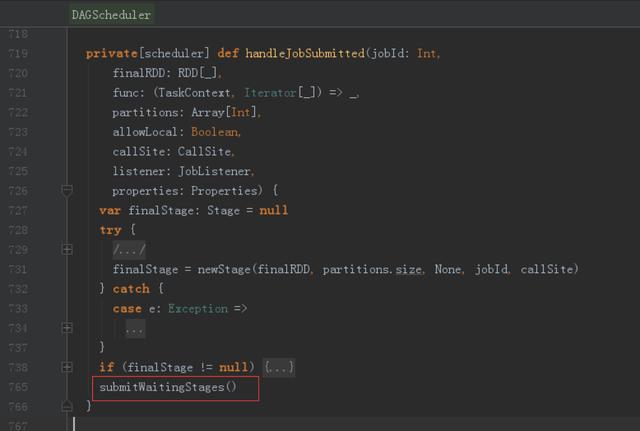
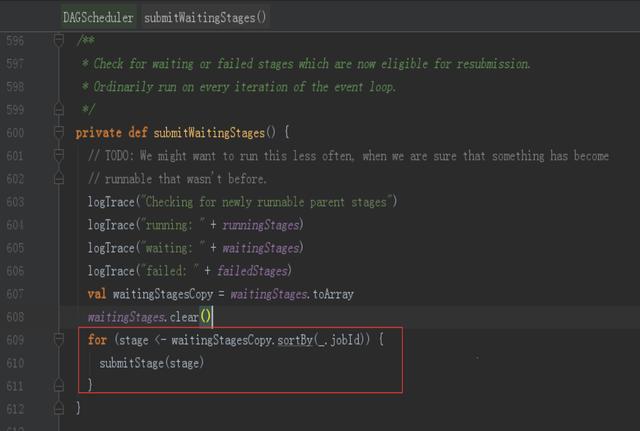
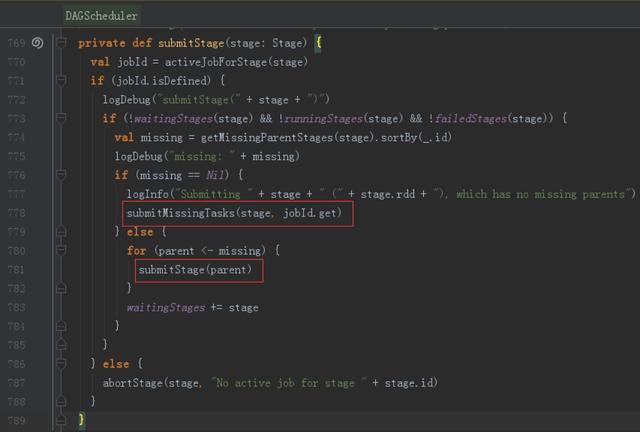
6、提交Stages
調度階段的提交,最終會被轉換成一個任務集的提交,DAGScheduler通過TaskScheduler接口提交任務集,這個任務集最終會觸發TaskScheduler構建一個TaskSetManager的實例來管理這個任務集的生命周期,對于DAGScheduler來說,提交調度階段的工作到此就完成了。而TaskScheduler的具體實現則會在得到計算資源的時候,進一步通過TaskSetManager調度具體的任務到對應的Executor節點上進行運算。
7、相關代碼
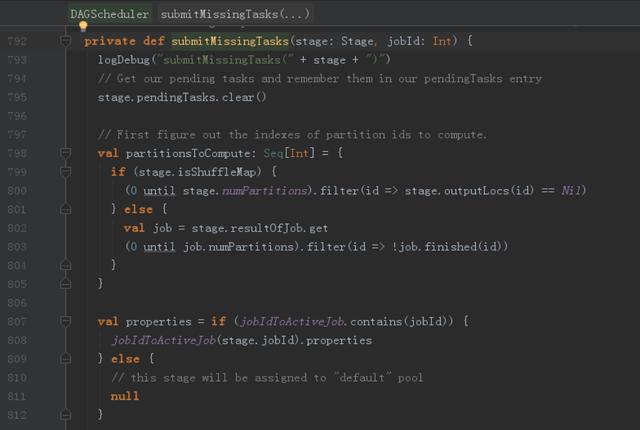
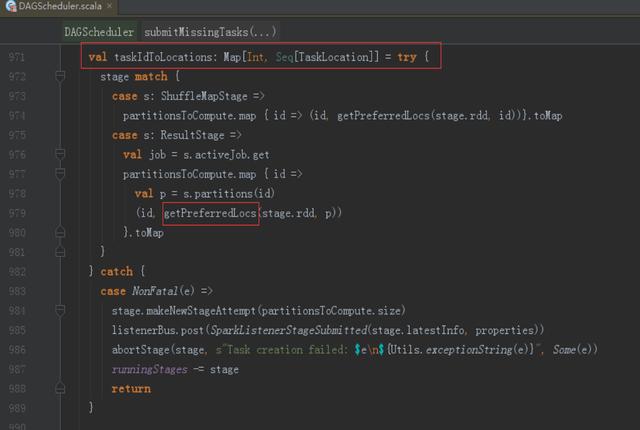
TaskSetManager負責管理TaskSchedulerImpl中一個單獨TaskSet,跟蹤每一個task,如果task失敗,負責重試task直到達到task重試次數的最多次數。
8、監控Job、Task、Executor
DAGScheduler監控Job與Task:要保證相互依賴的作業調度階段能夠得到順利的調度執行,DAGScheduler需要監控當前作業調度階段乃至任務的完成情況。這通過對外暴露一系列的回調函數來實現的,對于TaskScheduler來說,這些回調函數主要包括任務的開始結束失敗、任務集的失敗,DAGScheduler根據這些任務的生命周期信息進一步維護作業和調度階段的狀態信息。
DAGScheduler監控Executor的生命狀態:TaskScheduler通過回調函數通知DAGScheduler具體的Executor的生命狀態,如果某一個Executor崩潰了,則對應的調度階段任務集的ShuffleMapTask的輸出結果也將標志為不可用,這將導致對應任務集狀態的變更,進而重新執行相關計算任務,以獲取丟失的相關數據。
9、獲取任務執行結果
結果DAGScheduler:一個具體的任務在Executor中執行完畢后,其結果需要以某種形式返回給DAGScheduler,根據任務類型的不同,任務結果的返回方式也不同。
兩種結果,中間結果與最終結果:對于FinalStage所對應的任務,返回給DAGScheduler的是運算結果本身,而對于中間調度階段對應的任務ShuffleMapTask,返回給DAGScheduler的是一個MapStatus里的相關存儲信息,而非結果本身,這些存儲位置信息將作為下一個調度階段的任務獲取輸入數據的依據。
兩種類型,DirectTaskResult與IndirectTaskResult:根據任務結果大小的不同,ResultTask返回的結果又分為兩類,如果結果足夠小,則直接放在DirectTaskResult對象內中,如果超過特定尺寸則在Executor端會將DirectTaskResult先序列化,再把序列化的結果作為一個數據塊存放在BlockManager中,然后將BlockManager返回的BlockID放在IndirectTaskResult對象中返回給TaskScheduler,TaskScheduler進而調用TaskResultGetter將IndirectTaskResult中的BlockID取出并通過BlockManager最終取得對應的DirectTaskResult。
10、任務調度總體詮釋