存儲性能瓶頸的背后,這篇文章帶來的參考價值
在項目實戰中,需根據業務真實訴求,針對業務模型進行***實踐分析和洞察,從主機端口、存儲系統、后端磁盤等端到端進行分析和評估,才能提供比較切合業務訴求的配置。
那么,通常有哪些因素會影響對性能的準確評估呢?在本文中會把項目性能評估中遇到的難點話題依次羅列,希望對大家有所幫助。
一、IO聚合優化寫懲罰
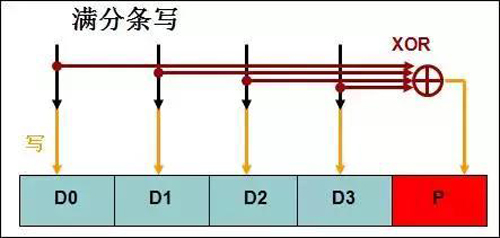
IO聚合成滿分條大小的情況下,無需做預讀操作,不會觸發RAID寫懲罰,RAID寫懲罰在不是滿分條寫的時候,才會觸發預讀的流程。以RAID5-5小寫為例,寫一個數據位,需要預讀兩次,寫校驗位一次。可以認為是一個IO被放大成了四個IO。
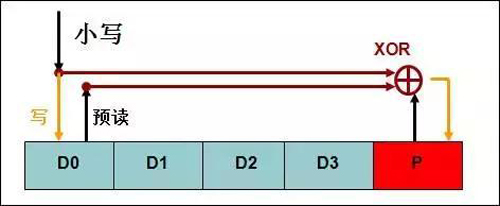
而滿分條寫的時候,同時寫四個數據位,不需要預讀,只需要額外寫一次校驗位,可以認為是四個IO被放大成了五個IO 。對比非滿分條寫,效率大大提高。
存儲的IO合并能力對于數據庫業務是否各家都能做到IO合并呢?一般存儲針對不同類型的IO有不同的合并能力;數據庫業務主要是隨機IO,各廠商都做不到完全滿分條IO合并。存儲收到的IO是否能夠合并,主要取決于兩個方面。
1、主機側發下來的業務IO是否順序,是否連續,與主機業務軟件本身、主機側塊設備、卷管理策略、HBA卡拆分策略等相關。主機下發的IO越順序、越連續,到達陣列后的合并效果越好。
2、IO路徑上的Cache、存儲塊設備、硬盤等模塊都會對IO進行排序與合并的操作,試圖盡可能將小IO合成大IO下盤。
對于順序小IO而言,基本上能夠實現將IO都合并成滿分條后下盤。而對于IO隨機程度較高的數據庫業務,各廠商都無法確保所有IO都能夠合并,只能盡量通過排序和合并,將相鄰地址的小IO合成大IO,但合并程度由于算法實現和內存大小等因素可能會有所差異。
二、場景的業務模型
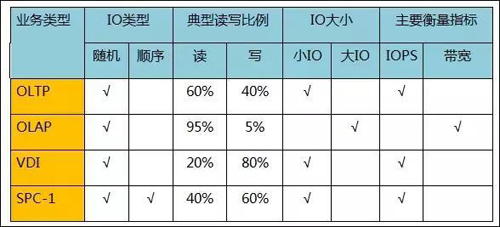
OLTP、OLAP、VDI和SPC-1是當前性能評估中常見的三類業務場景。SPC-1是業界通用的隨機IOPS型的IO模型,在不清楚實際業務類型的條件下,常用此模型來進行性能評估。四種模型的簡單IO特征如下表所示。
1、OLTP業務模型和特征:
每個事務的讀,寫,更改涉及的數據量非常小,同時有很多用戶連接到數據庫,使用數據庫,要求數據庫有很快的響應時間,通常一個事務在幾秒內完成,時延要求一般在10-20ms。
針對Data LUN,主要是隨機小IO,IO大小主要為8KB(IO大小與數據庫的Block塊大小一致),讀寫比約為3:2,讀全隨機,寫有一定合并。 針對LOG LUN,多路順序小IO,大小不定,幾乎都是寫IO。
2、OLAP業務模型和特征:
一般很少有數據修改,除非在批量加載數據時;系統調用非常復雜的查詢語句,同時掃描非常多的行;一個查詢將花費數小時,甚至數天;主要取決于查詢語句的復雜程度;查詢的輸出通常是一個統計值,由group by與order by得出;當讀取操作進行時,發生的寫操作通常在臨時表空間內;平常對在線日志寫入很少,除非在批量加載數據時;分析型業務,一般對時延沒有要求。
針對Data LUN,多路順序大IO(可以近似認為是隨機大IO),IO大小與主機側設置的分條大小有關(如512KB),90%以上為讀業務,混合間斷讀寫。針對TMP LUN,隨機IO,讀寫混合(先寫后讀,計算時寫,讀臨時表時讀,大部分是寫,占整個業務中很少部分的IO),IO大小基本為200KB以上大IO。
3、VDI業務模型和特征
可以分為啟動風暴、登錄風暴和平穩狀態幾個常見場景,在不同的狀態下,業務壓力相差很大。啟動風暴,即大量虛擬機同時啟動時的突發狀態,是讀密集型操作。登錄風暴,即大量用戶同時登錄到桌面,導致共享存儲產生大量爆發性負載的情況,是寫密集型的,很難通過技術方式避免。平穩狀態,即所有用戶在同時使用桌面時,產生負載波動較小的狀態。不同的用戶類型,平穩狀態的負載有所不同。時延要求一般在10ms左右。
平穩狀態下,讀寫比例約為2:8,多路順序小IO,主要是寫,存在一定的合并,IO大小從512B到16KB都有;少量的讀IO,基本都是16KB,在負載穩定之后,Cache***率在80%以上。
4、SPC-1業務模型和特征
SPC-1設計一個專門為測試存儲系統在典型業務應用場合下的負載模型,這個負載模型連續不斷地對業務系統并發的做查詢和更新的工作,因此其主要由隨機I/O組成。這些隨機I/O的操作主要涉及數據庫型的OLTP應用以及E-mail系統應用,能夠很好地衡量存儲系統的IOPS指標。
它抽象的測試區域稱為ASU,包括ASU1臨時數據區域,ASU2用戶數據區域和ASU3日志區域。對整體而言,讀寫比約為4:6,順序IO與隨機IO的比例約為3:7,IO大小主要為4KB,有較明顯的熱點訪問區域。
三、如何考慮校驗對性能的影響
對于順序寫業務,IO經過cache的IO合并后下發到RAID層,基本能夠確保都是滿分條寫。對于RAID5-5(4D+1P)這種配置來說,每4個數據IO(D)下盤同時會有一個校驗IO(P)需要下盤。校驗IO下盤所占的硬盤帶寬用于保障數據的可靠性,而對于用戶上層業務來說并沒有提供可用帶寬,因此需要扣除掉校驗位下盤所占的帶寬開銷。
對于順序讀業務,在滿分條的情況下,在每個分條內部只需要讀數據位所在的磁盤,不需要讀校驗位所在的磁盤。
例如,某一款產品,能夠提供的***寫帶寬為3200MB,規劃配置96塊600GB 15k SAS盤(推薦單盤寫帶寬為30MB),部署RAID6-6(4D+2P),估算這款產品能夠提供的有效寫帶寬。
硬盤提供的有效寫帶寬 = 單盤順序寫帶寬 * 硬盤數量 * (RAID數據盤數量/RAID總盤數)= 30MB * 96 * (4/6)= 1920 MB
產品能提供的有效寫帶寬 = MIN(產品能提供的***寫帶寬,硬盤提供的有效寫帶寬)= MIN(3200MB,1920MB)= 1920 MB
四、讀寫比和對性能影響
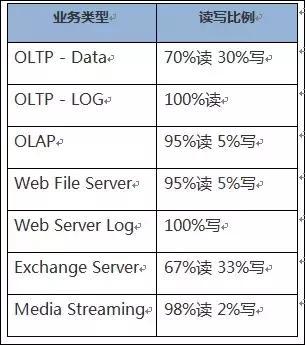
讀寫比指的是上層應用下發的讀IO和寫IO的比例分布。此數據是存儲規劃的重要參考依據。讀業務與寫業務消耗的存儲資源差異很大。下面是一些典型業務模型的常見讀寫比例
確切了解上層應用的讀寫比例直接影響到對cache策略、RAID級別和LUN配置的選擇。寫業務比讀業務會消耗更多的存儲系統資源。
1、在回寫的場景下,寫IO下發到cache之后需要通過交換通道“鏡像”到對端控制器,IO路徑更長,并需要占用交換通道的帶寬;
2、為保證寫數據的可靠性和一致性,智能存儲通常會采用一些可靠性技術,例如writehole方案,需要將寫數據額外保存一份在cache或磁盤上;
3、對于不同的RAID級別而言,寫懲罰的存在會造成更大的時延和資源的開銷;此外對于磁盤(包括SSD盤)而言,寫速度低于讀速度。
而對于讀業務來說,通常消耗較少的系統資源。例如,讀業務不需要生成額外的數據來保證數據一致。此外,絕大部分存儲設備的讀速度都比寫速度要快。當讀IO發現它所需讀取的數據已經在Cache中(讀***)時,可以直接返回而不需要再下盤讀取。在讀***的情況下,通常意味著最短的響應時延。
同樣數量的主機IO,如果讀寫比例不同,最終需要下盤的IO數量不同,意味著需要提供的磁盤能力不同。
五、RAID級別對性能影響
由于各RAID級別的寫懲罰不同,對于相同的業務類型、同樣數量的硬盤而言,選擇不同的RAID算法,能夠提供給主機的性能是不相等的。
針對各種典型場景的RAID10、RAID5和RAID6的性能對比,其中假設某存儲設備上所有硬盤能夠提供的性能為100%,按照各個應用場景的讀寫比例,經過寫懲罰系數的折算,得到配置成各個RAID級別后能提供給用戶的實際性能。
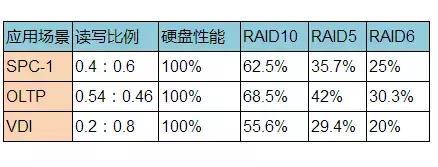
從數據中也可以看出,對于不同的業務類型、同樣數量的硬盤、相同的RAID算法,寫比例越大,性能越差。以SPC-1場景配置RAID6為例,假設用戶實際性能為x(0.4x + 0.6x * 6 = 100%),實際性能只是磁盤能提供的x = 25%。
由于RAID算法的實現原理不同(RAID10的鏡像、RAID5/6的校驗盤),對于同樣大小的裸容量來說,選擇不同的RAID算法,可提供給用戶的可用容量是不同的(不考慮熱備空間和系統預留的影響)。

從可靠性的層面來看,RAID6的可靠性***,RAID10次之,RAID5最差。RAID6和RAID10都支持同時壞2塊盤不丟數據,但是RAID10對壞的2塊盤是有條件要求的。
六、順序、隨機特性對性能影響
在磁盤層面,順序IO的性能優于隨機IO。這是由于傳統的機械磁盤讀寫數據需要盤片轉動和磁頭移動,使得隨機讀寫的盤片旋轉和磁頭尋道時間要遠大于順序讀寫。
在智能存儲系統層面,通常情況下,順序IO的性能同樣大大優于隨機IO,特別是對于小IO的IOPS性能而言。
1、小IO讀:通過順序流識別和預取算法,系統提前在磁盤上讀取大塊的連續數據存放在cache中,后續的大量順序小IO在cache中***,無需下盤處理。而隨機小IO在cache中***率極低,只能逐個下盤讀。
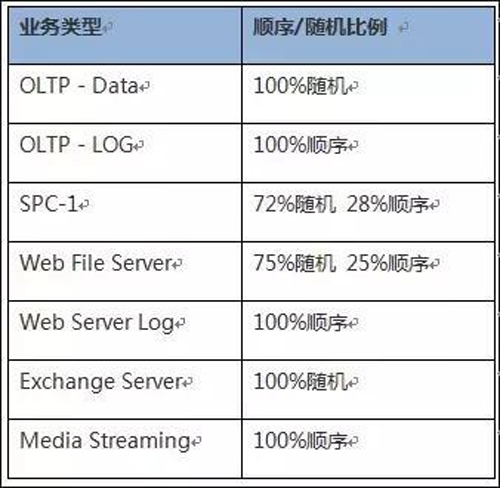
2、小IO寫:通過IO合并,系統將多個順序小IO合并成一個較大的IO下盤。如果在RAID5或RAID6場景,IO聚合成滿分條大小的情況下,無需做預讀操作,不會觸發RAID寫懲罰,效率很高。而隨機小IO無法合并,只能逐個下盤寫,且會觸發寫懲罰,導致性能更為低下。典型業務場景的順序/隨機特性,以下是一些典型業務場景的順序/隨機特性。
七、IO大小對性能的影響
IO的大小取決于上層應用程序本身。對性能而言,小IO一般用IOPS來衡量,大IO一般用帶寬來衡量。例如我們熟悉的SPC-1,主要衡量存儲系統在隨機小IO負荷下的IOPS,而SPC-2則主要衡量在各種高負荷連續讀寫應用場合下存儲系統的帶寬。
就單個IO而言,大IO從微觀角度相比小IO會需要更多的處理資源。對于隨機IO而言,隨著隨機IO塊大小的增加,IOPS會隨之降低。例如,當隨機IO大小大于16KB時,機械硬盤的IOPS會呈線性下降。因此,我們通常SPC-1測試的IOPS值很高,但因為用戶業務模型不同,IO大小不同,性能值也是變化的。
不過對于智能存儲系統來說,會盡可能通過排序、合并、填充等方法對IO進行整合,將多個小IO組合成單個大IO。例如,典型的Web Server Log業務,一般是8KB大小的順序小IO,在分條大小設置為128KB的存儲設備上,最終會將16個8KB大小的小IO合并成一個128KB的大IO下發到硬盤上。在這種情況下,對比處理多個小IO,處理單個大IO的速度更快、開銷更小。
IO的大小,影響到磁盤選型,緩存、RAID類型、LUN的一些屬性和策略的調優。例如,隨機小IO的場景,由于SSD盤具有快速隨機讀寫的特性,選用SSD盤對比SAS盤能夠大幅提升性能;但如果是隨機大IO,選用帶寬性能相當、價錢便宜的SAS盤更有優勢。
八、緩存Cache對性能影響
Cache是存儲中最重要的模塊之一,對于IOPS性能而言,Cache的主要作用是加速。對于寫業務,Cache加速體現在三個方面。
1、回寫情況下,主機側下到陣列側的數據只需要下到CACHE處而不需要真正寫到磁盤即可以返回通知主機寫完成,當寫CACHE的數據積累到一定程度(水位),陣列才把數據刷到磁盤。由此可以將速度較差的“同步單個寫”轉為“異步批量寫”,在通常情況下,回寫的性能約是透寫性能的兩倍以上。
2、寫***。回寫條件下,新寫到Cache中的數據發現在Cache中已經有準備寫到相同地址但還沒有刷盤的數據。在這種情況下,只需要將新寫入的數據下盤即可。
3、寫合并。例如小IO下到Cache中,Cache會盡可能對IO進行排序與合并,將多個小IO合成單個大IO再下盤。
對于讀業務,Cache加速主要體現在讀***。例如智能預取策略,Cache會主動識別IO流的特征,如果發現是順序IO流,Cache會在下盤讀IO的同時,主動讀取相鄰區域的大塊數據放到Cache中。當順序IO下發到Cache時,發現Cache中已存放了需要的數據,則直接將此數據返回即可,不需要再下盤讀。其中的一個特例是“全***”。在全***條件下,業務需要讀取的數據已經全部保存到Cache中,完全不需要再下盤處理,即所有IO到Cache層就返回了,路徑和時延最短。全***讀的IOPS值,往往是一款存儲產品能夠提供的***IOPS值。