Python Selenium爬蟲實(shí)現(xiàn)歌曲免費(fèi)下載
最近發(fā)現(xiàn)越來越多的歌曲下載都需要繳費(fèi)了,對(duì)維護(hù)正版是好事。但有的時(shí)候也想鉆個(gè)空子,正好最近在學(xué)習(xí)python,隨手寫了一個(gè)建議爬蟲,用來爬取某播放軟件的在線音樂。
主要思路就是爬取播放頁(yè)里的播放源文件的url,程序可以讀取用戶輸入并返回歌單,,,因?yàn)樵诰€網(wǎng)站包含大量js,requests就顯得很無奈,又懶得手動(dòng)解析js,于是寄出selenium大殺器。
selnium是一款很強(qiáng)大的瀏覽器自動(dòng)化測(cè)試框架,直接運(yùn)行在瀏覽器端,模擬用戶操作,目前selenium支持包括IE,Firefox,Chrome等主流瀏覽器及PhantomJS之類的無頭瀏覽器,selenium+phantomjs也是現(xiàn)在很火的一個(gè)爬蟲框架。
代碼不長(zhǎng),做的有些簡(jiǎn)陋,以后可以加個(gè)GUI。。。。
步驟一:
進(jìn)入酷狗主頁(yè),F(xiàn)12查看元素,,通過selenium.webdriver的send_keys()方法給send_input類傳參,即用作用戶的輸入,然后通webdriver.click()方法點(diǎn)擊搜索按鈕,得到搜索結(jié)果列表。這里會(huì)有一個(gè)js重定向,通過webdriver.current_ur就可以了,,切記一點(diǎn)!傳入的參數(shù)需要經(jīng)過unicode編碼(.decode(‘gb18030′))效果一樣),否則如果有中文會(huì)亂碼。。(來自被深深困擾的我)
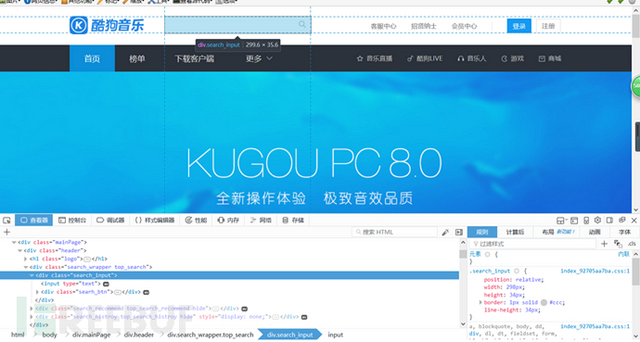
步驟二:
查看元素里每首歌的路徑,發(fā)現(xiàn)每首歌的路徑只有<li>不同,于是通過對(duì)li的迭代來獲取每一首歌的xpath,并輸出歌曲名字的元素,然后依舊通過webdriver的click()方法點(diǎn)擊歌曲鏈接,得到歌曲播放頁(yè)面,這里沒有什么難點(diǎn),都是常規(guī)操作。需要注意的是,這里的歌曲鏈接也包含一個(gè)js的重定向,但不一樣的是瀏覽器會(huì)打開一個(gè)新的頁(yè)面(至少火狐會(huì)),可以在click()方法后通過webdriver.switch_to_window()方法跳轉(zhuǎn)到新打開的頁(yè)面
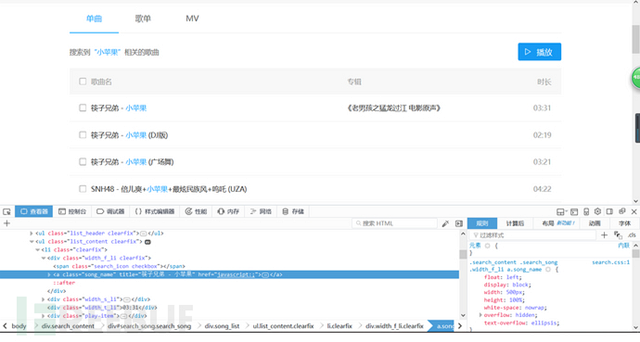
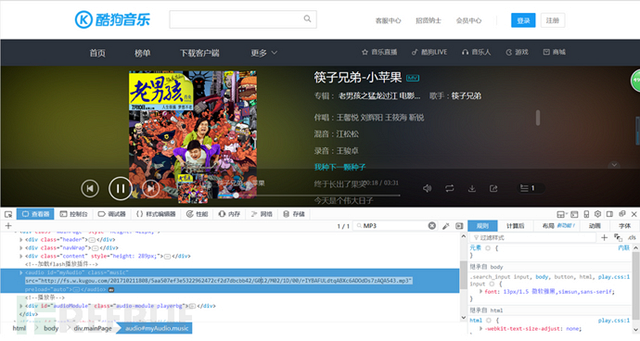
步驟三:
進(jìn)入播放頁(yè)面后通過xpath找到播放源文件鏈接(強(qiáng)推firepath,xpath神器啊)但發(fā)現(xiàn)這里依然有一個(gè)js渲染,來生成播放源鏈接,直接提取<src>標(biāo)簽會(huì)顯示為空,于是繼續(xù)webdriver,調(diào)用的瀏覽器會(huì)自動(dòng)解析js腳本,解析完成后提取<src>得到歌曲鏈接,使用urllib的urlretrueve()下載即可
代碼如下:
- #coding=utf-8
- from selenium.webdriver.remote.webelement import WebElement
- from selenium import webdriver
- from selenium.webdriver import ActionChains
- from selenium.common.exceptions import NoSuchElementException
- from selenium.common.exceptions import StaleElementReferenceException
- from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
- from selenium.webdriver.common.by import By
- import time
- import urllib
- #歌曲名
- mname = ''
- #JS重定向
- def wait(driver):
- elem = driver.find_element_by_tag_name('html')
- count = 0
- while True:
- count += 1
- if count > 20:
- print('chao shi le')
- return
- time.sleep(.5)
- try:
- elem == driver.find_element_by_tag_name('html')
- except StaleElementReferenceException:
- return
- #獲取url
- def geturl():
- input_string = raw_input('>>>please input the search key:')
- driver = webdriver.Chrome()
- url = 'http://www.kugou.com/'
- driver.get(url)
- a=driver.find_element_by_xpath('html/body/div[1]/div[1]/div[1]/div[1]/input') #輸入搜索內(nèi)容
- a.send_keys(input_string.decode('gb18030'))
- driver.find_element_by_xpath('html/body/div[1]/div[1]/div[1]/div[1]/div/i').click() #點(diǎn)擊搜索
- result_url = driver.current_url
- driver.quit()
- return result_url
- #顯示搜索結(jié)果
- def show_results(url):
- driver = webdriver.Chrome()
- driver.get(url)
- time.sleep(3)
- for i in range(1,1000):
- try:
- print '%d. '%i + driver.find_element_by_xpath(".//*[@id='search_song']/div[2]/ul[2]/li[%d]/div[1]/a"%i).get_attribute('title') #獲取歌曲名
- except NoSuchElementException as msg:
- break
- choice = input(">>>Which one do you want(you can input 'quit' to goback(帶引號(hào))):")
- if choice == 'quit': #從下載界面退回
- result = 'quit'
- else:
- global mname
- mname = driver.find_element_by_xpath(".//*[@id='search_song']/div[2]/ul[2]/li[%d]/div[1]/a"%choice).get_attribute('title')
- a = driver.find_element_by_xpath(".//*[@id='search_song']/div[2]/ul[2]/li[%d]/div[1]/a"%choice)
- actions = ActionChains(driver)
- actions.move_to_element(a)
- actions.click(a)
- actions.perform()
- #wait(driver)
- driver.switch_to_window(driver.window_handles[1]) #跳轉(zhuǎn)到新打開的頁(yè)面
- result = driver.find_element_by_xpath(".//*[@id='myAudio']").get_attribute('src') #獲取播放元文件url
- driver.quit()
- return result
- #下載回調(diào)
- def cbk(a, b, c):
- per = 100.0 * a * b / c
- if per > 100:
- per = 100
- print '%.2f%%' % per
- def main():
- print'***********************歡迎使用GREY音樂下載器********************************'
- print' directed by GreyyHawk'
- print'**************************************************************************'
- time.sleep(1)
- while True:
- url = geturl()
- result = show_results(url)
- if result == 'quit':
- print'\n'
- continue
- else:
- local = 'd://%s.mp3'%mname
- print 'download start'
- time.sleep(1)
- urllib.urlretrieve(result, local, cbk)
- print 'finish downloading %s.mp3'%mname + '\n\n'
- if __name__ == '__main__':
- main()
效果:

總結(jié):
當(dāng)網(wǎng)頁(yè)包含大量js的時(shí)候,selenium就會(huì)非常的方便,但經(jīng)過實(shí)踐發(fā)現(xiàn)好像phantomjs解析js的效率沒有世紀(jì)瀏覽器的高,還會(huì)出錯(cuò),后來?yè)Q成調(diào)用火狐就好了,,不知道為啥,,也許是臉黑吧,,總之selenium真的是一款非常強(qiáng)大的框架,對(duì)爬蟲有興趣的同學(xué)一定要了解一下。