從頭開始:用Python實現(xiàn)帶隨機梯度下降的Logistic回歸
logistic 回歸是一種著名的二元分類問題的線性分類算法。它容易實現(xiàn)、易于理解,并在各類問題上有不錯的效果,即使該方法的原假設與數(shù)據有違背時。
在本教程中,你將了解如何在 Python 中實現(xiàn)隨機梯度下降的 logistic 回歸算法。學完本教程后,你將了解:
- 如何使用 logistic 回歸模型進行預測。
- 如何使用隨機梯度下降(stochastic gradient descent)來估計系數(shù)(coefficient)。
- 如何將 logistic 回歸應用到真實的預測問題。
讓我們開始吧!
一、描述
本節(jié)將簡要介紹 logistic 回歸算法、隨機梯度下降以及本教程使用的 Pima 印第安人糖尿病數(shù)據集。
logistic 回歸算法
logistic 回歸算法以該方法的核心函數(shù)命名,即 logistic 函數(shù)。logistic 回歸的表達式為方程,非常像線性回歸。輸入值(X)通過線性地組合權重或系數(shù)值來預測輸出值(y)。
與線性回歸的主要區(qū)別在于,模型的輸出值是二值(0 或 1),而不是連續(xù)的數(shù)值。
- yhat = e^(b0 + b1 * x1) / (1 + e^(b0 + b1 * x1))
公式可簡化為:
- yhat = 1.0 / (1.0 + e^(-(b0 + b1 * x1)))
這里 e 是自然對數(shù)的底(歐拉數(shù)),yhat 是預測值,b0 是偏差或截距項,b1 是單一輸入變量(x1)的參數(shù)。
yhat 預測值為 0 到 1 之間的實數(shù),它需要舍入到整數(shù)值并映射到預測類值。
輸入數(shù)據中的每一列都有一個相關系數(shù) b(一個常數(shù)實數(shù)值),這個系數(shù)是從訓練集中學習的。存儲在存儲器或文件中的最終模型的實際上是等式中的系數(shù)(β值或 b)。
logistic 回歸算法的系數(shù)必須從訓練集中估計。
二、隨機梯度下降
梯度下降是通過順著成本函數(shù)(cost function)的梯度來最小化函數(shù)的過程。
這涉及到成本函數(shù)的形式及導數(shù),使得從任意給定點能推算梯度并在該方向上移動,例如,沿坡向下(downhill)直到最小值。
在機器學習中,我們可以使用一種技術來評估和更新每次迭代后的系數(shù),這種技術稱為隨機梯度下降,它可以使模型的訓練誤差(training error)最小化。
此優(yōu)化算法每次將每個訓練樣本傳入模型。模型對訓練樣本進行預測,計算誤差并更新模型以便減少下一預測的誤差。
該過程可以找到使訓練誤差最小的一組系數(shù)。每次迭代,機器學習中的系數(shù)(b)通過以下等式更新:
- bb = b + learning_rate * (y - yhat) * yhat * (1 - yhat) * x
其中 b 是被優(yōu)化的系數(shù)或權重,learning_rate 是必須設置的學習速率(例如 0.01),(y - y hat)是訓練數(shù)據基于權重計算的模型預測誤差,y hat 是通過系數(shù)計算的預測值,x 是輸入值。
三、Pima 印第安人糖尿病數(shù)據集
Pima Indians 數(shù)據集包含了根據基本醫(yī)療細節(jié)預測 Pima 印第安人 5 年內糖尿病的發(fā)病情況。
它是一個二元分類問題,其中預測是 0(無糖尿病)或 1(糖尿病)。
它包含 768 行和 9 列。所有值都是數(shù)字型數(shù)值,含有浮點值(float)。下面的例子展示了數(shù)據前幾行的結構。
- 6,148,72,35,0,33.6,0.627,50,1
- 1,85,66,29,0,26.6,0.351,31,0
- 8,183,64,0,0,23.3,0.672,32,1
- 1,89,66,23,94,28.1,0.167,21,0
- 0,137,40,35,168,43.1,2.288,33,1
- ...
通過預測多數(shù)類(零規(guī)則算法 Zero Rule Algorithm),這個問題的基線性能為 65.098%的分類準確率(accuracy)。你可以在 UCI 機器學習數(shù)據庫中了解有關此數(shù)據集的更多信息:https://archive.ics.uci.edu/ml/datasets/Pima+Indians+Diabetes
下載數(shù)據集,并將其保存到你當前的工作目錄,文件名為 pima-indians-diabetes.csv。
四、教程
本教程分為 3 部分。
- 進行預測
- 估計系數(shù)
- 糖尿病數(shù)據集預測
學完這三部分,你將具有應用 logistic 回歸與隨機梯度下降的基礎,并可以開始處理你自己的預測建模問題。
1. 進行預測
***步是開發(fā)一個可以進行預測的函數(shù)。
在隨機梯度下降中估計系數(shù)值以及模型最終確定后在測試集上進行預測都需要這個預測函數(shù)。
下面是一個名為 predict() 的函數(shù),給定一組系數(shù),它預測每一行的輸出值。
***個系數(shù)始終為截距項 (intercept),也稱為偏差或 b0,因為它是獨立的,不是輸入值的系數(shù)。
- # Make a prediction with coefficients
- def predict(row, coefficients):
- yhat = coefficients[0]
- for i in range(len(row)-1):
- yhat += coefficients[i + 1] * row[i]
- return 1.0 / (1.0 + exp(-yhat))
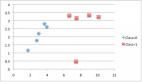
我們可以設計一個小數(shù)據集來測試我們的 predict() 函數(shù)。
- X1 X2 Y
- 2.7810836 2.550537003 0
- 1.465489372 2.362125076 0
- 3.396561688 4.400293529 0
- 1.38807019 1.850220317 0
- 3.06407232 3.005305973 0
- 7.627531214 2.759262235 1
- 5.332441248 2.088626775 1
- 6.922596716 1.77106367 1
- 8.675418651 -0.242068655 1
- 7.673756466 3.508563011 1
下面是數(shù)據集的散點圖,不同顏色代表不同類別。
據集的散點圖")
我們還可以使用先前準備的系數(shù)對該數(shù)據集進行預測。
把這些放在一起,我們可以測試下面的 predict() 函數(shù)。
- # Make a prediction
- from math import exp
- # Make a prediction with coefficients
- def predict(row, coefficients):
- yhat = coefficients[0]
- for i in range(len(row)-1):
- yhat += coefficients[i + 1] * row[i]
- return 1.0 / (1.0 + exp(-yhat))
- # test predictions
- dataset = [[2.7810836,2.550537003,0],
- [1.465489372,2.362125076,0],
- [3.396561688,4.400293529,0],
- [1.38807019,1.850220317,0],
- [3.06407232,3.005305973,0],
- [7.627531214,2.759262235,1],
- [5.332441248,2.088626775,1],
- [6.922596716,1.77106367,1],
- [8.675418651,-0.242068655,1],
- [7.673756466,3.508563011,1]]
- coef = [-0.406605464, 0.852573316, -1.104746259]
- for row in dataset:
- yhat = predict(row, coef)
- print("Expected=%.3f, Predicted=%.3f [%d]" % (row[-1], yhat, round(yhat)))
有兩個輸入值(X1 和 X2)和三個系數(shù)(b0,b1 和 b2)。該模型的預測方程是:
- y = 1.0 / (1.0 + e^(-(b0 + b1 * X1 + b2 * X2)))
或者,代入我們主觀選擇的具體系數(shù)值,方程為:
- y = 1.0 / (1.0 + e^(-(-0.406605464 + 0.852573316 * X1 + -1.104746259 * X2)))
運行此函數(shù),我們得到的預測值相當接近預期的輸出值(y),并且四舍五入時能預測出正確的類別。
- Expected=0.000, Predicted=0.299 [0]
- Expected=0.000, Predicted=0.146 [0]
- Expected=0.000, Predicted=0.085 [0]
- Expected=0.000, Predicted=0.220 [0]
- Expected=0.000, Predicted=0.247 [0]
- Expected=1.000, Predicted=0.955 [1]
- Expected=1.000, Predicted=0.862 [1]
- Expected=1.000, Predicted=0.972 [1]
- Expected=1.000, Predicted=0.999 [1]
- Expected=1.000, Predicted=0.905 [1]
現(xiàn)在我們已經準備好實現(xiàn)隨機梯度下降算法來優(yōu)化系數(shù)值了。
2. 估計系數(shù)
我們可以使用隨機梯度下降來估計訓練集的系數(shù)值。
隨機梯度下降需要兩個參數(shù):
- 學習速率(Learning Rate):用于限制每次迭代時每個系數(shù)的校正量。
- 迭代次數(shù)(Epochs):更新系數(shù)前遍歷訓練集數(shù)據的次數(shù)。
函數(shù)中有 3 層循環(huán):
- 每次迭代(epoch)的循環(huán)。
- 每次迭代的訓練集數(shù)據的每一行的循環(huán)。
- 每次迭代的每一行數(shù)據的每個系數(shù)的每次更新的循環(huán)。
就這樣,在每一次迭代中,我們更新訓練集中每一行數(shù)據的每個系數(shù)。系數(shù)的更新基于模型的訓練誤差值。這個誤差通過期望輸出值(真實的因變量)與估計系數(shù)確定的預測值之間的差來計算。
每一個輸入屬性(自變量)對應一個系數(shù),這些系數(shù)在迭代中不斷更新,例如:
- b1(t+1) = b1(t) + learning_rate * (y(t) - yhat(t)) * yhat(t) * (1 - yhat(t)) * x1(t)
列表開頭的特殊系數(shù)(也稱為截距)以類似方式更新,除了與輸入值無關:
- b0(t+1) = b0(t) + learning_rate * (y(t) - yhat(t)) * yhat(t) * (1 - yhat(t))
現(xiàn)在我們可以把這所有一切放在一起。下面是一個名為 coefficients_sgd() 的函數(shù),它使用隨機梯度下降計算訓練集的系數(shù)值。
- # Estimate logistic regression coefficients using stochastic gradient descent
- def coefficients_sgd(train, l_rate, n_epoch):
- coef = [0.0 for i in range(len(train[0]))]
- for epoch in range(n_epoch):
- sum_error = 0
- for row in train:
- yhat = predict(row, coef)
- error = row[-1] - yhat
- sum_error += error**2
- coef[0] = coef[0] + l_rate * error * yhat * (1.0 - yhat)
- for i in range(len(row)-1):
- coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 - yhat) * row[i]
- print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error))
- return coef
此外,每次迭代我們記錄誤差平方和 SSE(一個正值),以便我們在每個外循環(huán)開始時可以 print 出結果。
我們可以用上面的小數(shù)據集測試這個函數(shù)。
- from math import exp
- # Make a prediction with coefficients
- def predict(row, coefficients):
- yhat = coefficients[0]
- for i in range(len(row)-1):
- yhat += coefficients[i + 1] * row[i]
- return 1.0 / (1.0 + exp(-yhat))
- # Estimate logistic regression coefficients using stochastic gradient descent
- def coefficients_sgd(train, l_rate, n_epoch):
- coef = [0.0 for i in range(len(train[0]))]
- for epoch in range(n_epoch):
- sum_error = 0
- for row in train:
- yhat = predict(row, coef)
- error = row[-1] - yhat
- sum_error += error**2
- coef[0] = coef[0] + l_rate * error * yhat * (1.0 - yhat)
- for i in range(len(row)-1):
- coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 - yhat) * row[i]
- print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error))
- return coef
- # Calculate coefficients
- dataset = [[2.7810836,2.550537003,0],
- [1.465489372,2.362125076,0],
- [3.396561688,4.400293529,0],
- [1.38807019,1.850220317,0],
- [3.06407232,3.005305973,0],
- [7.627531214,2.759262235,1],
- [5.332441248,2.088626775,1],
- [6.922596716,1.77106367,1],
- [8.675418651,-0.242068655,1],
- [7.673756466,3.508563011,1]]
- l_rate = 0.3
- n_epoch = 100
- coef = coefficients_sgd(dataset, l_rate, n_epoch)
- print(coef)
我們使用更大的學習速率 0.3,并循環(huán) 100 次迭代來訓練模型,或將系數(shù)更新 100 次。
運行該示例代碼,每次迭代時會 print 出該次迭代的誤差平方和以及該迭代確定的***系數(shù)。
- >epoch=95, lrate=0.300, error=0.023
- >epoch=96, lrate=0.300, error=0.023
- >epoch=97, lrate=0.300, error=0.023
- >epoch=98, lrate=0.300, error=0.023
- >epoch=99, lrate=0.300, error=0.022
- [-0.8596443546618897, 1.5223825112460005, -2.218700210565016]
你可以看到誤差持續(xù)下降,甚至在***一次迭代。我們可以訓練更長的時間(更多次迭代)或增加每次迭代更新系數(shù)的程度(更高的學習率)。
測試這些代碼,看看你有什么新想法。
現(xiàn)在,讓我們將此算法應用于實際數(shù)據集。
3. 糖尿病數(shù)據集預測
在本節(jié)中,我們將使用隨機梯度下降算法對糖尿病數(shù)據集進行 logistic 回歸模型訓練。
該示例假定數(shù)據集的 CSV 副本位于當前工作目錄中,文件名為 pima-indians-diabetes.csv。
首先加載數(shù)據集,將字符串值轉換為數(shù)字,并將每個列標準化為 0 到 1 范圍內的值。這是通過輔助函數(shù) load_csv()和 str_column_to_float()來加載和準備數(shù)據集以及 dataset_minmax()和 normalize_dataset()來標準化的。
我們將使用 k 折交叉驗證(k-fold cross validation)來估計學習到的模型在未知數(shù)據上的預測效果。這意味著我們將構建和評估 k 個模型,并將預測效果的平均值作為模型的評價標準。分類準確率將用于評估每個模型。這些過程由輔助函數(shù) cross_validation_split(),accuracy_metric() 和 evaluate_algorithm() 提供。
我們將使用上面創(chuàng)建的 predict()、coefficients_sgd() 函數(shù)和一個新的 logistic_regression() 函數(shù)來訓練模型。
下面是完整示例:
- # Logistic Regression on Diabetes Dataset
- from random import seed
- from random import randrange
- from csv import reader
- from math import exp
- # Load a CSV file
- def load_csv(filename):
- dataset = list()
- with open(filename, 'r') as file:
- csv_reader = reader(file)
- for row in csv_reader:
- if not row:
- continue
- dataset.append(row)
- return dataset
- # Convert string column to float
- def str_column_to_float(dataset, column):
- for row in dataset:
- row[column] = float(row[column].strip())
- # Find the min and max values for each column
- def dataset_minmax(dataset):
- minmax = list()
- for i in range(len(dataset[0])):
- col_values = [row[i] for row in dataset]
- value_min = min(col_values)
- value_max = max(col_values)
- minmax.append([value_min, value_max])
- return minmax
- # Rescale dataset columns to the range 0-1
- def normalize_dataset(dataset, minmax):
- for row in dataset:
- for i in range(len(row)):
- row[i] = (row[i] - minmax[i][0]) / (minmax[i][1] - minmax[i][0])
- # Split a dataset into k folds
- def cross_validation_split(dataset, n_folds):
- dataset_split = list()
- dataset_copy = list(dataset)
- fold_size = len(dataset) / n_folds
- for i in range(n_folds):
- fold = list()
- while len(fold) < fold_size:
- index = randrange(len(dataset_copy))
- fold.append(dataset_copy.pop(index))
- dataset_split.append(fold)
- return dataset_split
- # Calculate accuracy percentage
- def accuracy_metric(actual, predicted):
- correct = 0
- for i in range(len(actual)):
- if actual[i] == predicted[i]:
- correct += 1
- return correct / float(len(actual)) * 100.0
- # Evaluate an algorithm using a cross validation split
- def evaluate_algorithm(dataset, algorithm, n_folds, *args):
- folds = cross_validation_split(dataset, n_folds)
- scores = list()
- for fold in folds:
- train_set = list(folds)
- train_set.remove(fold)
- train_set = sum(train_set, [])
- test_set = list()
- for row in fold:
- row_copy = list(row)
- test_set.append(row_copy)
- row_copy[-1] = None
- predicted = algorithm(train_set, test_set, *args)
- actual = [row[-1] for row in fold]
- accuracy = accuracy_metric(actual, predicted)
- scores.append(accuracy)
- return scores
- # Make a prediction with coefficients
- def predict(row, coefficients):
- yhat = coefficients[0]
- for i in range(len(row)-1):
- yhat += coefficients[i + 1] * row[i]
- return 1.0 / (1.0 + exp(-yhat))
- # Estimate logistic regression coefficients using stochastic gradient descent
- def coefficients_sgd(train, l_rate, n_epoch):
- coef = [0.0 for i in range(len(train[0]))]
- for epoch in range(n_epoch):
- for row in train:
- yhat = predict(row, coef)
- error = row[-1] - yhat
- coef[0] = coef[0] + l_rate * error * yhat * (1.0 - yhat)
- for i in range(len(row)-1):
- coef[i + 1] = coef[i + 1] + l_rate * error * yhat * (1.0 - yhat) * row[i]
- return coef
- # Linear Regression Algorithm With Stochastic Gradient Descent
- def logistic_regression(train, test, l_rate, n_epoch):
- predictions = list()
- coef = coefficients_sgd(train, l_rate, n_epoch)
- for row in test:
- yhat = predict(row, coef)
- yhat = round(yhat)
- predictions.append(yhat)
- return(predictions)
- # Test the logistic regression algorithm on the diabetes dataset
- seed(1)
- # load and prepare data
- filename = 'pima-indians-diabetes.csv'
- dataset = load_csv(filename)
- for i in range(len(dataset[0])):
- str_column_to_float(dataset, i)
- # normalize
- minmax = dataset_minmax(dataset)
- normalize_dataset(dataset, minmax)
- # evaluate algorithm
- n_folds = 5
- l_rate = 0.1
- n_epoch = 100
- scores = evaluate_algorithm(dataset, logistic_regression, n_folds, l_rate, n_epoch)
- print('Scores: %s' % scores)
- print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))
令 k 折交叉驗證的 k 值為 5,每次迭代時用于評估的數(shù)量為 768/5 = 153.6 或剛好超過 150 個記錄。通過實驗選擇學習速率 0.1 和訓練迭代次數(shù) 100。
你可以嘗試其它的設置,看看模型的評估分數(shù)是否比我的更好。
運行此示例代碼,print 5 折交叉驗證的每一次的分數(shù),*** print 分類準確率的平均值。
可以看到,此算法的準確率大約為 77%,而如果我們使用零規(guī)則算法預測多數(shù)類,基線值為 65%,本算法的準確率高于基線值。
- Scores: [73.20261437908496, 75.81699346405229, 75.81699346405229, 83.66013071895425, 78.43137254901961]
- Mean Accuracy: 77.386%
五、擴展
以下是本教程的一些擴展,你可以自己來實現(xiàn)這些算法。
- 調整(Tune)示例中的參數(shù)。調整學習速率、迭代次數(shù),甚至調整數(shù)據預處理方法,以改進數(shù)據集的準確率得分。
- 批處理(Batch)隨機梯度下降。改變隨機梯度下降算法,使得模型在歷次迭代中的更新能不斷積累,并且只在迭代結束后的一個批處理中更新系數(shù)。
- 其它分類問題。嘗試用該技術解決其它 UCI 機器學習庫中的二值分類問題。
六、回顧
在本教程中,你了解了如何使用隨機梯度下降算法實現(xiàn) logistic 回歸。
你現(xiàn)在知道:
- 如何對多變量分類問題進行預測。
- 如何使用隨機梯度下降優(yōu)化一組系數(shù)。
- 如何將該技術應用到真正的分類預測建模問題。
原文:
https://machinelearningmastery.com/implement-logistic-regression-stochastic-gradient-descent-scratch-python/
【本文是51CTO專欄機構“機器之心”的原創(chuàng)譯文,微信公眾號“機器之心( id: almosthuman2014)”】