Keras+OpenAI強化學習實踐:行為-評判模型
像之前的教程一樣,我們首先快速了解一下已取得的驚人成果:在一個連續(xù)的輸出空間場景下,從完全不明白「勝利」的含義開始,現在我們可以探索環(huán)境并「完成」試驗。
將自身置身于模擬環(huán)境中。這就相當于要求你在沒有游戲說明書和特定目標的場景下玩一場游戲,且不可中斷,直到你贏得整個游戲(這有些近乎殘忍)。不僅如此:一系列動作可能產生的結果狀態(tài)是無窮無盡的(即連續(xù)觀測空間)!然而,DQN 通過調控并緩慢更新各動作內部參數的值可以快速解決這個看似不可能的任務。
更復雜的環(huán)境
從以前的 MountainCar 環(huán)境向 Pendulum 環(huán)境的升級與 CartPole 到 MountainCar 的升級極其相似:我們正在從一個離散的環(huán)境擴展到連續(xù)的環(huán)境。Pendulum 環(huán)境具有無限的輸入空間,這意味著你在任何給定時間可以進行不限次數的動作。為何 DQN 不再適用此類環(huán)境了?DQN 的實現不是完全獨立于環(huán)境動作的結構嗎?
不同于 MountainCar-v0,Pendulum-v0 通過給我們提供了無窮大的輸入空間而構成了更大的挑戰(zhàn)。
雖然它與動作無關,但 DQN 的基本原理是擁有有限的輸出空間。畢竟,我們要考慮該如何構建代碼:預測會在每個時間步長(給定當前環(huán)境狀態(tài))下為每個可能的動作分配一個分數,并簡單地采用得分最高的動作。我們之前已經簡化了強化學習的問題,以便高效地為每個動作分配分數。但是,如果我們輸入空間無限大,這還有可能嗎?我們需要一個無限大的表格來記錄所有的 Q 值!

無限大的數據表聽起來很不靠譜!
我們該如何著手解決這個看似不可能的任務呢?畢竟,我們現在要做比以前更加瘋狂的事:不僅僅只是贏下一場沒有攻略的游戲,現在我們還要應對一個被無數條指令控制的游戲!讓我們來看看為什么 DQN 只接收有限數量的動作輸入。
我們從模型的搭建方式來分析。我們必須能夠在每個時間步迭代更新特定的動作位置的改變方式。這正是為什么我們讓模型預測 Q 值,而不是直接預測下一步的動作。如果選擇了后者,我們不知道如何更新模型以更好地預測,以及從對未來的預測中獲利。
因此,本質問題源于一個事實——類似于模型已經輸出與所有可能發(fā)生的行動相關的獎勵的列表運算結果。如果我們把這個模型拆解開會怎樣?如果我們有兩個獨立的模型:一個輸出期望的動作(在連續(xù)空間中),另一個以它的輸出作為輸入,以產生 DQN 的 Q 值?這貌似解決了我們的問題,而且這正是行為-評判模型(actor-critic model)的基本原理!
行為-評判模型原理

不同于 DQN 算法,行為-評判模型(如名字所示)有兩個獨立的網絡:一個基于當前的環(huán)境狀態(tài)預測出即將被采用的動作,另一個用于計算狀態(tài)和動作下的價值。
正如上節(jié)所述,整個行為—評判(AC)方法可行的前提是有兩個交互模型。多個神經網絡之間相互關聯的主題在強化學習和監(jiān)督學習(即 GAN、AC、A3C、DDQN(升級版 DQN)等)中越發(fā)凸顯。初次了解這些架構可能有些困難,但這絕對值得去做:你將能夠理解和編程實現一些現代領域研究前沿的算法!
回到主題,AC 模型有兩個恰如其分的名字:行為和評判。前者接受當前的環(huán)境狀態(tài),并決定從哪個狀態(tài)獲得最佳動作。它以非常類似于人類自身的行為方式來實現 DQN 算法。評判模塊通過從 DQN 中接受環(huán)境狀態(tài)和動作并返回一個表征動作狀態(tài)的分數來完成評判功能。
把這想象成是一個孩子(「行為模塊」)與其父母(「評判模塊」)的游樂場。孩子正在環(huán)顧四周,探索周邊環(huán)境中的所有可能選擇,例如滑動幻燈片,蕩秋千,在草地上玩耍。父母會照看孩子并基于其所為,對孩子給出批評或補充。父母的決定依賴于環(huán)境的事實無可否認:畢竟,如果孩子試圖在真實的秋千上玩耍,相比于試圖在幻燈片上這樣做,孩子更值得表揚!
簡介:鏈式法則(可選)
你需要理解的主要理論在很大程度上支撐著現代機器學習:鏈式法則。毫不夸張的說鏈式法則可能是掌握理解實用機器學習的最關鍵的(即使有些簡單)的想法之一。事實上,如果只是直觀地了解鏈式法則的概念,你并不需要很深厚的數學背景。我會非常快速地講解鏈式法則,但如果你已了解,請隨意跳到下一部分,下一部分我們將看到開發(fā) AC 模型的實際概述,以及鏈條法則如何適用于該規(guī)劃。
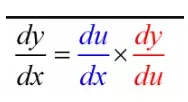
一個看似可能來自你第一節(jié)微積分課堂上的簡單概念,構成了實用機器學習的現代基礎,因為它在反向推算和類似算法中有著令人難以置信的加速運算效果。
這個等式看起來非常直觀:畢竟只是「重寫了分子/分母」。這個「直觀的解釋」有一個主要問題:等式中的推導完全是倒退的!關鍵是要記住,數學中引入直觀的符號是為了幫助我們理解概念。因此,由于鏈式法則的計算方式非常類似于簡化分數的運算過程,人們才引入這種「分數」符號。那么試圖通過符號來解釋概念的人正在跳過關鍵的一步:為什么這些符號可以通用?如同這里,為什么要像這樣進行求導?
則")
可以借助經典的彈簧實例可視化運動中的鏈條規(guī)則。
基本概念實際上并不比這個符號更難理解。想象一下,我們把一捆繩子一根根地系在一起,類似于把一堆彈簧串聯起來。假設你固定了這個彈簧系統的一端,你的目標是以 10 英尺/秒的速度搖晃另一端,那么你可以用這個速度搖動你的末端,并把它傳播到另一端。或者你可以連接一些中間系統,以較低的速率搖動中間連接,例如,5 英尺/秒。也就是說,在 5 英尺/秒的情況下,你只需要以 2 英尺/秒的速度搖動末端,因為你從開始到終點做的任何運動都會被傳遞到終點位置。這是因為物理連接迫使一端的運動被傳遞到末端。注意:和其它類比一樣,這里有一些不當之處,但這主要是為了可視化。
類似地,如果我們有兩個系統,其中一個系統的輸出是另一個系統的輸入,微調「反饋網絡」的參數將會影響其輸出,該輸出會被傳播下去并乘以任何進一步的變化值并貫穿整個網絡。
AC 模型概述
因此,我們必須制定一個 ActorCritic 類,它包含一些之前實現過的 DQN,但是其訓練過程更復雜。因為我們需要一些更高級的功能,我們必須使用包含了基礎庫 Keras 的開源框架:Tensorflow。注意:你也可以在 Theano 中實現這一點,但是我以前沒有使用過它,所以沒有包含其代碼。如果你選擇這么做,請隨時向 Theano 提交此代碼的擴展。
模型實現包含四個主要部分,其直接并行如何實現 DQN 代理:
- 模型參數/配置
- 訓練代碼
- 預測代碼
1. AC 參數
第一步,導入需要的庫
- import gym
- import numpy as np
- from keras.models import Sequential, Model
- from keras.layers import Dense, Dropout, Input
- from keras.layers.merge import Add, Multiply
- from keras.optimizers import Adam
- import keras.backend as K
- import tensorflow as tf
- import random
- from collections import deque
參數與 DQN 中的參數非常類似。畢竟,這個行為-評判模型除了兩個獨立的模塊之外,還要做與 DQN 相同的任務。我們還繼續(xù)使用我們在 DQN 報告中討論的「目標網絡攻擊」,以確保網絡成功收斂。唯一的新參數是「tau」,并且涉及在這種情況下如何進行目標網絡學習的細微變化:
- class ActorCritic:
- def __init__(self, env, sess):
- self.env = env
- self.sess = sess
- self.learning_rate = 0.001
- self.epsilon = 1.0
- self.epsilon_decay = .995
- self.gamma = .95
- self.tau = .125
- self.memory = deque(maxlen=2000)
在以下的訓練部分中,詳細解釋了 tau 參數的準確用法,它的作用其實就是推動預測模型向目標模型逐步轉換。現在,我們找到了主要的關注點:定義模型。正如我們所描述的,我們有兩個獨立的模型,每個模型都與它自己的目標網絡相關聯。
我們從定義行為模型開始。行為模型的目的是根據當前環(huán)境狀態(tài),得出應當采取的最佳動作。再次,這個模型需要處理我們提供的數字數據,這意味著沒有空間也沒有必要在網絡中添加任何比我們迄今為止使用的密集/完全連接層更復雜的層。因此,行為模型只是一系列全連接層,將環(huán)境觀察的狀態(tài)映射到環(huán)境空間上的一個點:
- def create_actor_model(self):
- state_input = Input(shape=self.env.observation_space.shape)
- h1 = Dense(24, activation='relu')(state_input)
- h2 = Dense(48, activation='relu')(h1)
- h3 = Dense(24, activation='relu')(h2)
- output = Dense(self.env.action_space.shape[0],
- activation='relu')(h3)
- model = Model(input=state_input, outputoutput=output)
- adam = Adam(lr=0.001)
- model.compile(loss="mse", optimizer=adam)
- return state_input, model
主要的區(qū)別是我們返回了一個對輸入層的引用。本節(jié)結尾對此原因的解釋十分清楚,但簡而言之,這解釋了我們?yōu)槭裁磳π袨槟P偷挠柧氝^程采取不同的處理。
行為模型中的棘手部分是決定如何訓練它,這就是鏈式法則發(fā)揮作用的地方。但在討論之前,讓我們考慮一下為什么它與標準評論/ DQN 網絡的訓練不同。畢竟,我們不是簡單地去適應在 DQN(根據當前狀態(tài)擬合模型)的情況下,基于當前的和打折的未來獎勵得出接下來采用的最佳動作是哪一個?問題在于:如果我們能夠按照要求去做,那么這個問題將會解決。問題在于我們如何確定「最佳動作」是什么,因為 Q 值現在是在評判網絡中單獨計算出來的。
所以,為了解決這個問題,我們選擇了一種替代方法。不同于找到「最佳選擇」和擬合,我們實際上選擇了爬山算法(梯度上升)。對于不熟悉這個算法的人來說,登山是一個形象的比喻:從你當地的 POV,找到斜率最大的傾斜方向,并沿著該方向逐步移動。換句話說,爬山正試圖通過原始的沖動并沿著局部斜率最大的方向來達到全局最大值。可以想象在某些情況下,該方法大錯特錯,但通常情況下,它具備很好的實用性。
因此,我們想使用該算法來更新我們的行為模型:我們想確定(行為模型中的)參數的什么變化會導致 Q 值最大幅度的增加(由評判模型預測得出)。由于行為模型的輸出是動作,評判模型通過環(huán)境狀態(tài)+動作對來評估,我們在此可以看到鏈式法則如何發(fā)揮作用。我們想看看如何改變行為模型的參數才會改變最終的 Q 值,使用行為網絡的輸出作為我們的「中間鏈接」(下面的代碼全部在「__init __(self)」方法中):
- self.actor_state_input, self.actor_model = \
- self.create_actor_model()
- _, selfself.target_actor_model = self.create_actor_model()
- self.actor_critic_grad = tf.placeholder(tf.float32,
- [None, self.env.action_space.shape[0]])
- actor_model_weights = self.actor_model.trainable_weights
- self.actor_grads = tf.gradients(self.actor_model.output,
- actor_model_weights, -self.actor_critic_grad)
- grads = zip(self.actor_grads, actor_model_weights)
- self.optimize = tf.train.AdamOptimizer(
- self.learning_rate).apply_gradients(grads)
我們看到在這里我們持有模型權重和輸出(動作)之間的梯度。我們還通過負的 self.actor_critic_grad(因為我們想在這種情況下使用梯度上升)來放縮它,梯度由占位符持有。對于那些不熟悉 Tensorflow 或首次接觸的讀者,你只需要知道運行 Tensorflow 會話時,占位符將扮演「輸入數據」的角色。我不會詳細介紹它的工作原理,因為 tensorflow.org 教程的材料相當全面。
再來看看評判網絡,基本上我們面臨著相反的問題。即,網絡定義稍微復雜一些,但是訓練比較簡單。評判網絡旨在將環(huán)境狀態(tài)和動作作為輸入,并計算出相應的估值。我們通過合并一系列全連接層以及得出最終的 Q 值預測之前的中間層來實現這一點:
- def create_critic_model(self):
- state_input = Input(shape=self.env.observation_space.shape)
- state_h1 = Dense(24, activation='relu')(state_input)
- state_h2 = Dense(48)(state_h1)
- action_input = Input(shape=self.env.action_space.shape)
- action_h1 = Dense(48)(action_input)
- merged = Add()([state_h2, action_h1])
- merged_h1 = Dense(24, activation='relu')(merged)
- output = Dense(1, activation='relu')(merged_h1)
- model = Model(input=[state_input,action_input],
- outputoutput=output)
- adam = Adam(lr=0.001)
- model.compile(loss="mse", optimizer=adam)
- return state_input, action_input, model
需要注意的是如何處理輸入和返回的不對稱性。對于第一點,我們在環(huán)境狀態(tài)輸入中有一個額外的 FC(全連接)層。我這樣做是因為這是推薦 AC 網絡使用的結構,但它可能與處理兩個輸入的 FC 層效果差不多(或稍差)。至于后面一點(我們正在返回的值),我們需要保留輸入狀態(tài)和動作的引用,因為我們需要使用它們更新行為網絡:
- self.critic_state_input, self.critic_action_input, \
- selfself.critic_model = self.create_critic_model()
- _, _, selfself.target_critic_model = self.create_critic_model()
- self.critic_grads = tf.gradients(self.critic_model.output,
- self.critic_action_input)
- # Initialize for later gradient calculations
- self.sess.run(tf.initialize_all_variables())
我們在這里設置要計算的缺失梯度:關于動作權重的輸出 Q。這是訓練代碼中直接調用的,我們現在來深入探討。
2. AC 模型訓練
該代碼的最后一個主要與 DQN 不同的部分是實際的訓練代碼。然而,我們使用了從記憶(LSTM 結構)中吸取教訓和學習的基本結構。由于我們有兩種訓練方法,我們將代碼分成不同的訓練函數,并將它們稱為:
- def train(self):
- batch_size = 32
- if len(self.memory) < batch_size:
- return
- rewards = []
- samples = random.sample(self.memory, batch_size)
- self._train_critic(samples)
- self._train_actor(samples)
現在我們定義兩種訓練方法。不過,與 DQN 非常相似:我們只是簡單地找到未來打折的獎勵和訓練方法。唯一的區(qū)別是,我們正在對狀態(tài)/動作對進行訓練,并使用 target_critic_model 來預測未來的獎勵,而不是僅使用行為來預測:
- def _train_critic(self, samples):
- for sample in samples:
- cur_state, action, reward, new_state, done = sample
- if not done:
- target_action =
- self.target_actor_model.predict(new_state)
- future_reward = self.target_critic_model.predict(
- [new_state, target_action])[0][0]
- reward += self.gamma * future_reward
- self.critic_model.fit([cur_state, action],
- reward, verbose=0)
對于行為模型,我們幸運地解決了所有難題!我們已經設置了梯度如何在網絡中運作,現在只需傳入當前的動作和狀態(tài)并調用該函數:
- def _train_actor(self, samples):
- for sample in samples:
- cur_state, action, reward, new_state, _ = sample
- predicted_action = self.actor_model.predict(cur_state)
- grads = self.sess.run(self.critic_grads, feed_dict={
- self.critic_state_input: cur_state,
- self.critic_action_input: predicted_action
- })[0]
- self.sess.run(self.optimize, feed_dict={
- self.actor_state_input: cur_state,
- self.actor_critic_grad: grads
- })
如上所述,我們利用了目標模型。所以我們必須在每個時間步更新其權重。但是,更新過程太慢了。具體說,我們將目標模型的估值保持在一個分數 self.tau 上,并將其更新為余數(1-self.tau)分數的相應模型權重。行為/評判模型均如此處理,但下面只給出行為模型的代碼(你可以在文章底部的完整代碼中看到評判模型代碼):
- def _update_actor_target(self):
- actor_model_weights = self.actor_model.get_weights()
- actor_target_weights =self.target_critic_model.get_weights()
- for i in range(len(actor_target_weights)):
- actor_target_weights[i] = actor_model_weights[i]
- self.target_critic_model.set_weights(actor_target_weights
3. AC 模型預測
這與我們在 DQN 中的做法一樣,所以沒有什么好說的:
- def act(self, cur_state):
- self.epsilon *= self.epsilon_decay
- if np.random.random() < self.epsilon:
- return self.env.action_space.sample()
- return self.actor_model.predict(cur_state)
4. 預測代碼
預測代碼也與之前的強化學習算法相同。也就是說,我們只需反復試驗,并對代理進行預測、記憶和訓練:
- def main():
- sess = tf.Session()
- K.set_session(sess)
- env = gym.make("Pendulum-v0")
- actor_critic = ActorCritic(env, sess)
- num_trials = 10000
- trial_len = 500
- cur_state = env.reset()
- action = env.action_space.sample()
- while True:
- env.render()
- cur_statecur_state = cur_state.reshape((1,
- env.observation_space.shape[0]))
- action = actor_critic.act(cur_state)
- actionaction = action.reshape((1, env.action_space.shape[0]))
- new_state, reward, done, _ = env.step(action)
- new_statenew_state = new_state.reshape((1,
- env.observation_space.shape[0]))
- actor_critic.remember(cur_state, action, reward,
- new_state, done)
- actor_critic.train()
- cur_state = new_state
完整代碼
這是使用 AC(Actor-Critic)對「Pendulum-v0」環(huán)境進行訓練的完整代碼!
- """
- solving pendulum using actor-critic model
- """
- import gym
- import numpy as np
- from keras.models import Sequential, Model
- from keras.layers import Dense, Dropout, Input
- from keras.layers.merge import Add, Multiply
- from keras.optimizers import Adam
- import keras.backend as K
- import tensorflow as tf
- import random
- from collections import deque
- # determines how to assign values to each state, i.e. takes the state
- # and action (two-input model) and determines the corresponding value
- class ActorCritic:
- def __init__(self, env, sess):
- self.env = env
- self.sess = sess
- self.learning_rate = 0.001
- self.epsilon = 1.0
- self.epsilon_decay = .995
- self.gamma = .95
- self.tau = .125
- # ===================================================================== #
- # Actor Model #
- # Chain rule: find the gradient of chaging the actor network params in #
- # getting closest to the final value network predictions, i.e. de/dA #
- # Calculate de/dA as = de/dC * dC/dA, where e is error, C critic, A act #
- # ===================================================================== #
- self.memory = deque(maxlen=2000)
- self.actor_state_input, selfself.actor_model = self.create_actor_model()
- _, selfself.target_actor_model = self.create_actor_model()
- self.actor_critic_grad = tf.placeholder(tf.float32,
- [None, self.env.action_space.shape[0]]) # where we will feed de/dC (from critic)
- actor_model_weights = self.actor_model.trainable_weights
- self.actor_grads = tf.gradients(self.actor_model.output,
- actor_model_weights, -self.actor_critic_grad) # dC/dA (from actor)
- grads = zip(self.actor_grads, actor_model_weights)
- self.optimize = tf.train.AdamOptimizer(self.learning_rate).apply_gradients(grads)
- # ===================================================================== #
- # Critic Model #
- # ===================================================================== #
- self.critic_state_input, self.critic_action_input, \
- selfself.critic_model = self.create_critic_model()
- _, _, selfself.target_critic_model = self.create_critic_model()
- self.critic_grads = tf.gradients(self.critic_model.output,
- self.critic_action_input) # where we calcaulte de/dC for feeding above
- # Initialize for later gradient calculations
- self.sess.run(tf.initialize_all_variables())
- # ========================================================================= #
- # Model Definitions #
- # ========================================================================= #
- def create_actor_model(self):
- state_input = Input(shape=self.env.observation_space.shape)
- h1 = Dense(24, activation='relu')(state_input)
- h2 = Dense(48, activation='relu')(h1)
- h3 = Dense(24, activation='relu')(h2)
- output = Dense(self.env.action_space.shape[0], activation='relu')(h3)
- model = Model(input=state_input, outputoutput=output)
- adam = Adam(lr=0.001)
- model.compile(loss="mse", optimizer=adam)
- return state_input, model
- def create_critic_model(self):
- state_input = Input(shape=self.env.observation_space.shape)
- state_h1 = Dense(24, activation='relu')(state_input)
- state_h2 = Dense(48)(state_h1)
- action_input = Input(shape=self.env.action_space.shape)
- action_h1 = Dense(48)(action_input)
- merged = Add()([state_h2, action_h1])
- merged_h1 = Dense(24, activation='relu')(merged)
- output = Dense(1, activation='relu')(merged_h1)
- model = Model(input=[state_input,action_input], outputoutput=output)
- adam = Adam(lr=0.001)
- model.compile(loss="mse", optimizer=adam)
- return state_input, action_input, model
- # ========================================================================= #
- # Model Training #
- # ========================================================================= #
- def remember(self, cur_state, action, reward, new_state, done):
- self.memory.append([cur_state, action, reward, new_state, done])
- def _train_actor(self, samples):
- for sample in samples:
- cur_state, action, reward, new_state, _ = sample
- predicted_action = self.actor_model.predict(cur_state)
- grads = self.sess.run(self.critic_grads, feed_dict={
- self.critic_state_input: cur_state,
- self.critic_action_input: predicted_action
- })[0]
- self.sess.run(self.optimize, feed_dict={
- self.actor_state_input: cur_state,
- self.actor_critic_grad: grads
- })
- def _train_critic(self, samples):
- for sample in samples:
- cur_state, action, reward, new_state, done = sample
- if not done:
- target_action = self.target_actor_model.predict(new_state)
- future_reward = self.target_critic_model.predict(
- [new_state, target_action])[0][0]
- reward += self.gamma * future_reward
- self.critic_model.fit([cur_state, action], reward, verbose=0)
- def train(self):
- batch_size = 32
- if len(self.memory) < batch_size:
- return
- rewards = []
- samples = random.sample(self.memory, batch_size)
- self._train_critic(samples)
- self._train_actor(samples)
- # ========================================================================= #
- # Target Model Updating #
- # ========================================================================= #
- def _update_actor_target(self):
- actor_model_weights = self.actor_model.get_weights()
- actor_target_weights = self.target_critic_model.get_weights()
- for i in range(len(actor_target_weights)):
- actor_target_weights[i] = actor_model_weights[i]
- self.target_critic_model.set_weights(actor_target_weights)
- def _update_critic_target(self):
- critic_model_weights = self.critic_model.get_weights()
- critic_target_weights = self.critic_target_model.get_weights()
- for i in range(len(critic_target_weights)):
- critic_target_weights[i] = critic_model_weights[i]
- self.critic_target_model.set_weights(critic_target_weights)
- def update_target(self):
- self._update_actor_target()
- self._update_critic_target()
- # ========================================================================= #
- # Model Predictions #
- # ========================================================================= #
- def act(self, cur_state):
- self.epsilon *= self.epsilon_decay
- if np.random.random() < self.epsilon:
- return self.env.action_space.sample()
- return self.actor_model.predict(cur_state)
- def main():
- sess = tf.Session()
- K.set_session(sess)
- env = gym.make("Pendulum-v0")
- actor_critic = ActorCritic(env, sess)
- num_trials = 10000
- trial_len = 500
- cur_state = env.reset()
- action = env.action_space.sample()
- while True:
- env.render()
- cur_statecur_state = cur_state.reshape((1, env.observation_space.shape[0]))
- action = actor_critic.act(cur_state)
- actionaction = action.reshape((1, env.action_space.shape[0]))
- new_state, reward, done, _ = env.step(action)
- new_statenew_state = new_state.reshape((1, env.observation_space.shape[0]))
- actor_critic.remember(cur_state, action, reward, new_state, done)
- actor_critic.train()
- cur_state = new_state
- if __name__ == "__main__":
- main()
原文地址:
https://medium.com/towards-data-science/reinforcement-learning-w-keras-openai-actor-critic-models-f084612cfd69
【本文是51CTO專欄機構“機器之心”的原創(chuàng)譯文,微信公眾號“機器之心( id: almosthuman2014)”】