Uber如何用循環神經網絡(RNN)預測極端事件?
在Uber系統內,事件預測使我們能夠根據預期用戶需求來提高我們的服務質量。最終目標是準確地預測出在預定的時間內Uber將會在何處,何時以及收到多少次的乘車請求。
一般來說,極端事件——諸如假期、音樂會、惡劣天氣和體育賽事等高峰旅行時間,只會提高工作規劃預測的重要性。在極端事件期間計算需求時間序列預測(demand time series forecasting)是異常檢測(anomaly detection),***資源分配(optimal resource allocation)和預算的關鍵組成部分。
但不可忽略的一個事實是,雖然極端事件預測在Uber操作中占有舉足輕重的作用,但數據稀疏性使得準確的預測具有很大的挑戰性。比如元旦之夜(NYE),這是Uber最繁忙的日子之一。可是我們只有少數幾次元旦之夜的數據可以借鑒參考,而且每個實例可能有不同的用戶群組。除了歷史數據,極端事件預測還取決于許多外部因素,包括天氣、人口增長和諸如駕駛員激勵措施這樣的市場營銷的變化。
在現實生活中,在標準R預測包中發現的經典時間序列模型,通常和機器學習方法組合在一起,從而用于特殊事件的預測,然而,這些方法對于Uber來說,既不靈活也不可擴展。
在本文中,我們介紹一種將歷史數據和外部因素相結合的Uber預測模型,以便更精確地預測極端事件,突出其新架構,以及如何與先前的模型進行比較。
創建Uber的新的極端事件預測模型
隨著時間的推移,我們意識到為了擴大發展規模,我們需要升級我們的預測模型,從而準確預測Uber市場的極端事件。
我們最終決定基于長短期記憶網絡(LSTM)架構進行時間序列建模,LSTM架構是一種具有端到端建模特征,易于整合外部變量和自動特征提取能力的技術。通過在多個維度上提供大量數據,LSTM方法可以建造模擬復雜的非線性特征交互模型。
在選擇好架構之后,我們評估了訓練模型所需的數據儲存,如下所示:
在城市中隨時間推移而變化的規模性旅行次數是用于訓練我們模型的歷史數據儲存的一部分。 請注意除夕夜期間數據的一個下跌,然后急劇上漲,表示人們在除夕夜期間乘用Uber回家。
其實,極端事件的預測是一件很困難的事情,主要原因是它們的不頻繁性。為了克服這個數據缺陷,我們決定訓練一個單一的、靈活的神經網絡來一次性地對許多城市的數據進行建模,從而大大提高了我們的準確性。
用神經網絡構建新的架構
我們的目標是設計一個通用的、端到端的時間序列預測模型,它要具有可擴展性,準確性并且適用于異構時間序列。為了實現這一點,我們使用了數千個時間序列來訓練一個多模塊神經網絡。
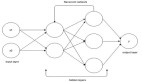
我們測量和追蹤了原始的外部數據,從而構建了如下圖所示的神經網絡:
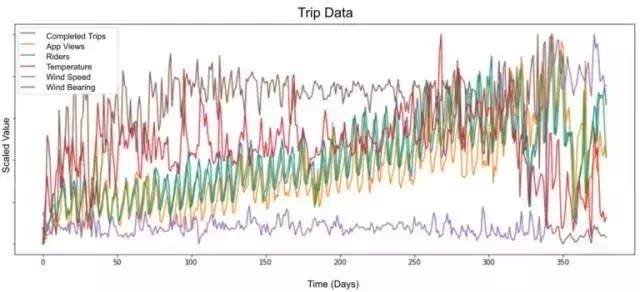
我們的模型是使用外部變量,包括天氣(例如降水、風速和溫度預報)和城市級信息(例如在特定地理區域內的任何給定時間進行的旅行,已注冊 Uber用戶,本地假期或事件)的組合進行訓練的。
這個原始數據用于我們的訓練模型中,來進行包括日志轉換,縮放和數據轉換這樣簡單的預處理。
用滑動窗口進行訓練
神經網絡中的訓練數據集需要滑動窗口X(輸入)和Y(輸出)來限定常規值(例如輸入大小)以及預測范圍。使用這兩個窗口之后,我們便可以通過最小化損失函數(loss function),如均方差(Mean Squared Error)來訓練神經網絡。
X和Y窗口都是以單個增量滑動的,從而生成訓練數據,如下所示:
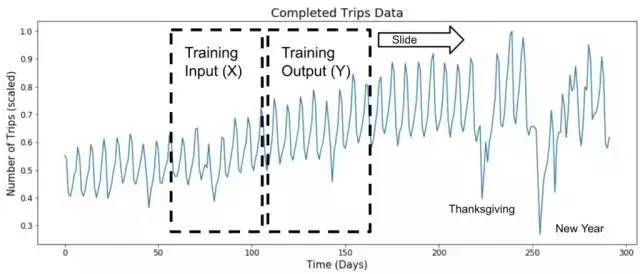
X和Y滑動窗口是由批次,時間,特征(對于X而言)和預測特征(對于Y而言)組成的。
接下來,我們就解釋如何使用我們的訓練數據來設計自定義的LSTM模型。
調整我們的LSTM模型
在測試期間,我們確認,與基線模型(其中包括單變量預測和機器學習元素的組合)相比,vanilla LSTM操作并沒有表現出優異的性能。vanilla模型在未被訓練的領域內不能適應時間序列,這導致在使用單個神經網絡時表現并不是很好。
使用每一個時間序列要處理***指標的方式來訓練一個模型是不切實際的:根本沒有足夠的資源可用,更不用說時間的有限性了。此外,訓練單一的vanilla LSTM不會產生競爭性的結果,因為模型不能區分不同的時間序列。雖然時間序列特征和輸入可以手動加載到vanilla LSTM模型中,但這種方法是冗長乏味且容易出錯的。
為了提高我們的準確度,我們在模型中引入了一個自動特征提取模塊,如下所示:
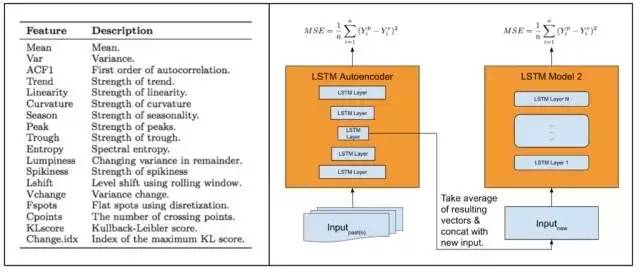
我們的模型由手動派生的時間序列特征(左)和我們提出的具有自動特征提取模型(右)的LSTM架構組成。
我們決定構建一個通過自動特征提取模塊提供單一模型、異質性預測的神經網絡架構。正如上圖所示,模型首先通過自動、基于集成的特征提取來初始化網絡;在提取特征向量后,再使用標準集成技術對其進行平均。然后將***一個向量與輸入連接從而產生最終預測。
在測試期間,我們能夠實現基于LSTM架構的14.09%的對稱平均絕對百分比誤差(SMAPE)改進,同時比Uber的實時監控和根本原因探索工具Argos中的經典時間序列模型提升25%。
隨著我們的架構的成功開發、定制和測試,現在正是將該模型投入生產使用的時候了。
使用新的預測模型
一旦計算了神經網絡的權重,它們就可以以任何編程語言形式進行導出和執行。我們當前的途徑是首先使用Tensorflow和Keras進行離線訓練,然后將生成的權重導出為本地Go代碼,如下所示:
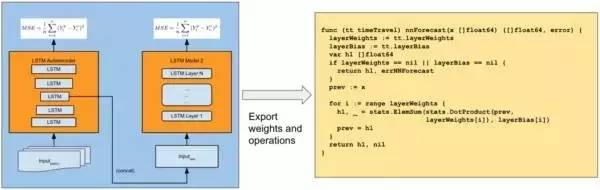
該描述模型首先進行離線訓練,然后導出到目標語言進行本機執行。
為了本文最初所設定的目標,我們建立了一個模型,使用的數據主要來自于美國五年間使用Uber來完成假期旅行的時間段,比如,像在圣誕節和元旦來臨的七天之前、之間和之后所產生的數據。
在一些城市進行預測的期間,我們收集了使用之前的和現在的兩種模型所產生的平均SMAPE,如下所示:
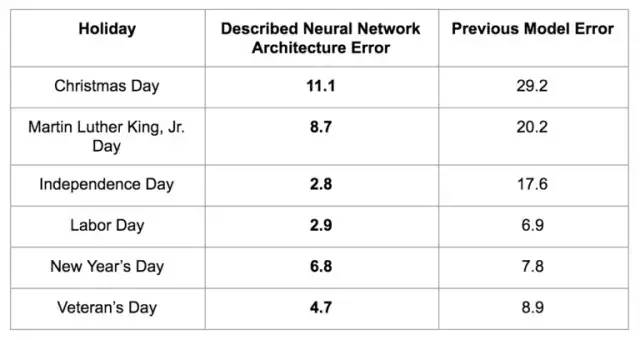
我們的新預測模型的效果顯著優于以前的預測模型。
例如,我們的新模式發現,預測最困難的假期之一是圣誕節,這與需求中的***錯誤和不確定性相對應。
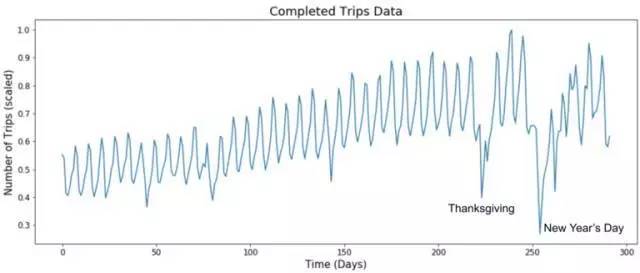
我們描繪了一個城市200天的預期和實際完成旅行的圖表,如下所示:
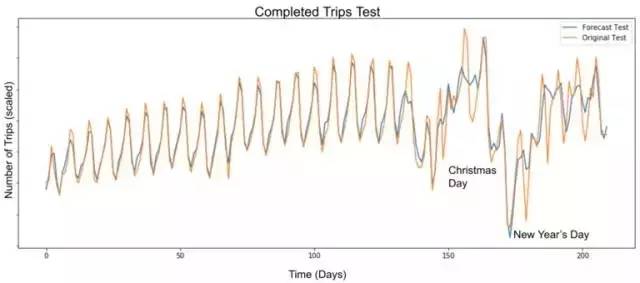
一個城市200多天完成旅行次數的模擬,我們對同一數據的預測凸顯了我們新模型的準確性
我們的測試結果表明,與我們的專有模型相比,現有的模型的預測精度提高了2-18%。
雖然神經網絡對Uber來說益處頗多,但這種方法并不是“萬金油”。根據以往的經驗,我們定義了一個三維思維,以此來決定神經網絡模型是否適用于你的情況:(a)時間序列數,(b)時間序列長度和(c)時間序列之間的相關性。相對于經典時間序列模型而言,這三個維度增加了神經網絡方法進行更準確的預測的可能性。
未來預測
我們打算繼續使用神經網絡,為異構時間序列創建一個通用的預測模型,作為一個獨立的、端到端模型或更大的自動化預測系統中的構建塊。如果你對這種研究比較感興趣的話,那么在2017年8月6日在悉尼的國際機器學習公約(International Machine Learning Convention)期間,可以查看Uber的時間序列研討會(http://roseyu.com/time-series-workshop/)。