前端與SQL
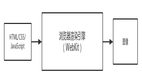
本篇將介紹前端本地存儲(chǔ)里的Web SQL和IndexedDB,通過(guò)一個(gè)案例介紹SQL的一些概念。
1. 地圖報(bào)表的案例
現(xiàn)在要做一個(gè)地圖報(bào)表,如下圖所示:
將所有的訂單數(shù)據(jù)做一個(gè)圖表展示,左邊的地圖展示每個(gè)city的成單情況,右邊的圖形,展示最近7天的成單情況。由于后端的數(shù)據(jù)需要前端做一些解析,如向谷歌請(qǐng)求每個(gè)city的經(jīng)緯度,所以后端給前端原始的訂單數(shù)據(jù),前端進(jìn)行格式化和歸類(lèi)展示。另外把原始數(shù)據(jù)直接放前端,前端處理起來(lái)可以比較靈活,想怎么展示就怎么展示,不用每次展示方式變的時(shí)候都需要找后端新加接口。
但是數(shù)據(jù)放在前端管理,相應(yīng)地就會(huì)引入一個(gè)問(wèn)題——如何高效地存儲(chǔ)和使用這些數(shù)據(jù)。最起碼處理起來(lái)不要讓頁(yè)面卡了。
2. cookie和localStorage
—cookie的數(shù)據(jù)量比較小,瀏覽器限制最大只能為4k,而—localStorage和sessionStorage適合于小數(shù)據(jù)量的存儲(chǔ),firefox和Chrome限制最大存儲(chǔ)為5Mb,如下火狐的config:
?? 
localStorage是存放在一個(gè)本地文件里面,在筆者的Mac上是放在:
/Users/yincheng/Library/Application Support/Google/Chrome/Default/Local Storage/ http_www.test.com.localstorage
用文本編輯器打開(kāi)這個(gè)二進(jìn)制文件,可以看到本地存儲(chǔ)的內(nèi)容:
?? ??
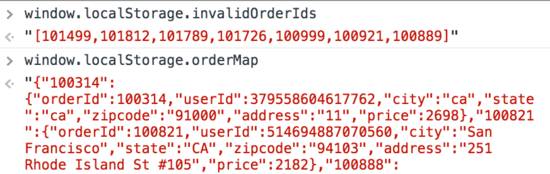
可以參照控制臺(tái)的輸出:
?? 
如果一個(gè)網(wǎng)站要用掉5Mb硬盤(pán)空間,那么打開(kāi)過(guò)一百個(gè)網(wǎng)頁(yè)就得花500Mb的空間,所以本地存儲(chǔ)localStorage的空間限制得比較小。
另外,可以看到localStorage是以字符串的方式存儲(chǔ)的,存之前要先JSON.stringify變成字符串,取的時(shí)候需要用JSON.parse恢復(fù)成相應(yīng)的格式。localStorage適合于比較簡(jiǎn)單的數(shù)據(jù)存放和管理。
3. 管理復(fù)雜數(shù)據(jù)
后端給我這樣的JSON數(shù)據(jù):
我用這些數(shù)據(jù)去請(qǐng)求它們的經(jīng)緯度。
這些數(shù)據(jù)的量比較大,有成百上千甚至幾萬(wàn)條數(shù)據(jù),—數(shù)據(jù)需要復(fù)雜的查詢(xún),需要支持:
- 訂單按日期分類(lèi)和排序
- 訂單按照city分類(lèi)
—如果自己管理JSON數(shù)據(jù)就會(huì)比較麻煩,所以這里嘗試使用Web SQL來(lái)管理這些數(shù)據(jù)。
4. Web SQL
(1)什么是SQL
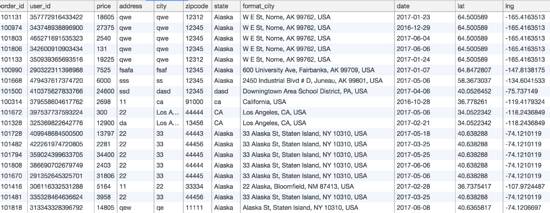
SQL作用在關(guān)系型數(shù)據(jù)庫(kù)上面,什么是關(guān)系型數(shù)據(jù)庫(kù)?關(guān)系型數(shù)據(jù)庫(kù)是由一張張的二維表組成的,如下圖所示:
?? 
那什么是SQL呢?SQL是一種操作關(guān)系型DB的語(yǔ)言,支持創(chuàng)建表,插入表,修改和刪除等等,還提供非常強(qiáng)大的查詢(xún)功能。
常見(jiàn)的關(guān)系型數(shù)據(jù)庫(kù)廠商有MySQL、SQLite、SQL Server、Oracle,由于MySQL是免費(fèi)的,所以企業(yè)一般用MySQL的居多。
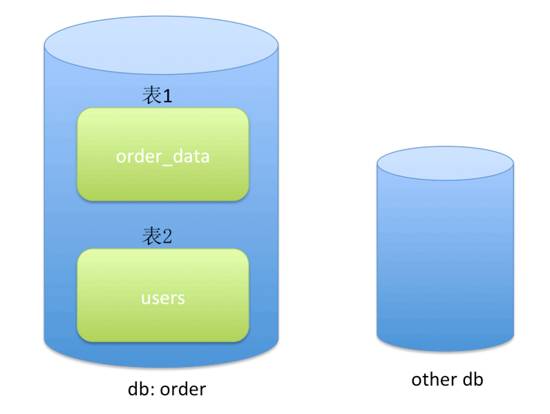
Web SQL是前端的數(shù)據(jù)庫(kù),它也是本地存儲(chǔ)的一種,使用SQLite實(shí)現(xiàn),SQLite是一種輕量級(jí)數(shù)據(jù)庫(kù),它占的空間小,支持創(chuàng)建表,插入、修改、刪除表格數(shù)據(jù),但是不支持修改表結(jié)構(gòu),如刪掉一縱列,修改表頭字段名等。但是可以把整張表刪了。同一個(gè)域可以創(chuàng)建多個(gè)DB,每個(gè)DB有若干張表,如下圖示意:
?? 
(2)創(chuàng)建一個(gè)DB
如下代碼所示:
?? 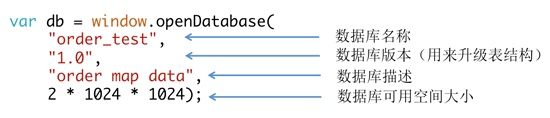
使用openDatabase,傳4個(gè)參數(shù),指定數(shù)據(jù)庫(kù)大小,如果指定太大,瀏覽器會(huì)提示用戶(hù)是否允許使用這么多空間,如Safari的提示:
?? 
如果不允許,瀏覽器將會(huì)拋異常:
QuotaExceededError (DOM Exception 22): The quota has been exceeded.
這樣就創(chuàng)建了一個(gè)數(shù)據(jù)庫(kù)叫order_test,返回了一個(gè)db對(duì)象,使用這個(gè)db對(duì)象創(chuàng)建一張表
(3)創(chuàng)建表
如下代碼所示:
傳一個(gè)回調(diào)給db.transaction,它會(huì)傳一個(gè)SQLTransaction的實(shí)例,它表示一個(gè)事務(wù),然后調(diào)executeSql函數(shù),傳四個(gè)參數(shù),第一個(gè)參數(shù)為要執(zhí)行的SQL語(yǔ)句,第二個(gè)參數(shù)為選項(xiàng),第三個(gè)為成功回調(diào)函數(shù),第四個(gè)為失敗回調(diào)函數(shù),這里我們拋一個(gè)異常,打印失敗的描述。我們執(zhí)行的SQL語(yǔ)句為:
create table if not exists order_data(order_id primary key, format_city, lat, lng, price, create_time)
意思是創(chuàng)建一張order_data表,它的字段有6個(gè),第一個(gè)order_id為主鍵,主鍵用來(lái)標(biāo)志這一列,并且不允許有重復(fù)的值。
現(xiàn)在往這張表插入數(shù)據(jù)。
(4)插入數(shù)據(jù)
準(zhǔn)備好原始數(shù)據(jù)和對(duì)數(shù)據(jù)做一些處理,如下所示:
然后執(zhí)行插入:
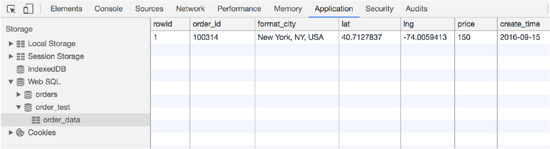
就可以在瀏覽器控制臺(tái)看到剛剛創(chuàng)建的數(shù)據(jù)庫(kù)、表,如下圖所示:
?? 
如果把剛剛的那條數(shù)據(jù)再插入一遍會(huì)怎么樣呢?如刷新一下頁(yè)面,它又重新執(zhí)行。
(5)主鍵唯一約束
插入一個(gè)重復(fù)主鍵,這里為id,executeSql的失敗函數(shù)將會(huì)執(zhí)行,如下所示:
?? 
所以一般id是自動(dòng)生成的,mysql可以指定某個(gè)整數(shù)字段為auto_increment,而web sql對(duì)整數(shù)字段不指定也是auto_increment,需要在創(chuàng)建的時(shí)候指定當(dāng)前字段為integer,如下語(yǔ)句:
作用是創(chuàng)建一張student表,它的id是自動(dòng)自增的,執(zhí)行insert插入時(shí)會(huì)自動(dòng)生成一個(gè)id:
這樣插入幾次,得到如下表:
?? 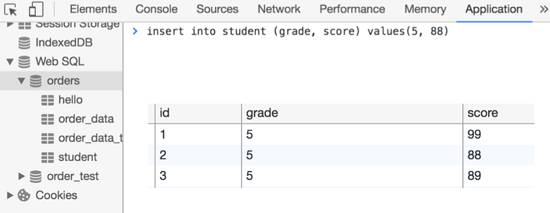
可以看到id由1開(kāi)始自動(dòng)增長(zhǎng)。經(jīng)常利用這種自增功能生成用戶(hù)的id、訂單的id等等。
上面指定了id為整型,就不能插入一個(gè)字符串的數(shù)據(jù),否則會(huì)報(bào)錯(cuò)。而如果沒(méi)指定,可以插入數(shù)字也可以插入字符串,當(dāng)然同一字段最好類(lèi)型要一致。如mysql、SQL Server等數(shù)據(jù)庫(kù)都是強(qiáng)類(lèi)型的。
這里有一個(gè)細(xì)節(jié)需要注意,后端的mysql的id一般采用64位的長(zhǎng)整型,這個(gè)數(shù)最大值為一個(gè)19位數(shù):
9223372036854775807
而JS的最大整數(shù)為一個(gè)16位數(shù),大于這個(gè)數(shù)的值將會(huì)是不可靠的,如下圖所示:
?? 
因此如果發(fā)生這種情況的話,需要讓后端把ID當(dāng)作字符串的方式傳給你。這個(gè)我在《 為什么0.1 + 0.2不等于0.3? 》這篇文章里面做過(guò)討論。
(6)全部的數(shù)據(jù)
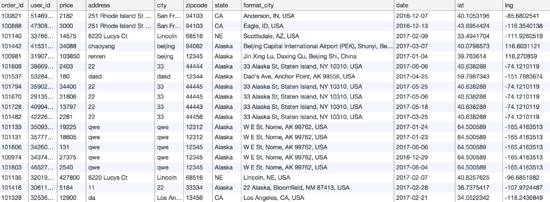
把所有的數(shù)據(jù)都插入之后,得到如下表:
?? 
然后我們開(kāi)始做查詢(xún)。
(7)Select查詢(xún)
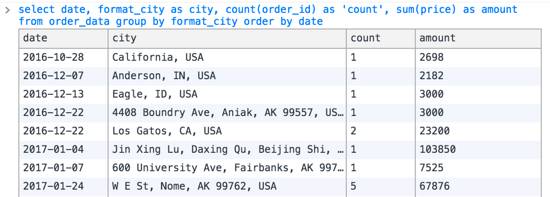
—a)查出每個(gè)城市的單數(shù)和,按日期升序。便于地圖按city展示,可以執(zhí)行以下SQL:
結(jié)果如下圖所示:
?? 
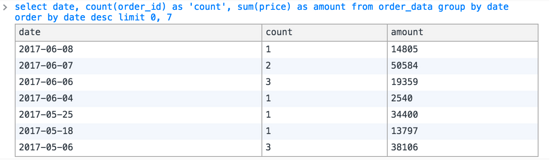
b)然后再—查一下最近7天每一天的單數(shù),用于右邊柱狀圖的展示,執(zhí)行以下SQL:
得到:
?? 
c)查詢(xún)某個(gè)orderId是否存在,因?yàn)閿?shù)據(jù)需要?jiǎng)討B(tài)更新,例如每?jī)蓚€(gè)小時(shí)更新一次,如果有新數(shù)據(jù)需要去查詢(xún)格式化的地址以及經(jīng)緯度。而每次請(qǐng)求都是拉取全部數(shù)據(jù),因此需要找出哪些是新數(shù)據(jù)。可以執(zhí)行:
如果返回空的結(jié)果集,說(shuō)明這個(gè)orderId不存在。
上面是在控制臺(tái)執(zhí)行,在代碼里面怎么獲取結(jié)果呢,如下圖所示:
?? 
某些字段可能會(huì)被重復(fù)查詢(xún),如order_id,format_city,如果對(duì)這些字段做一個(gè)索引,那么可以提高查詢(xún)的效率。
(8)建立索引
由于order_id是主鍵,自動(dòng)會(huì)有索引,其它字段需要手動(dòng)創(chuàng)建一個(gè)索引,如對(duì)format_city添加一個(gè)索引可執(zhí)行:
為什么創(chuàng)建索引可以提高查詢(xún)效率呢?因?yàn)槿绻麤](méi)建索引要找到某個(gè)字段等于某個(gè)值的數(shù)據(jù),需要遍歷所有的數(shù)據(jù)條項(xiàng),查找復(fù)雜度為O(N),而建立索引一般是使用二叉查找樹(shù)或者它的變種,查找復(fù)雜度變成O(logN),mysql是使用的B+樹(shù)。有興趣的可繼續(xù)查找資料。
另外字符串可使用哈希變成數(shù)字,字符串索引要比數(shù)字低效很多。
使用索引的代價(jià)是增加存儲(chǔ)空間,降低插入修改的效率。所以索引不能建太多,如果查詢(xún)的次數(shù)要明顯高于修改那么建立索引是好的,相反如果某個(gè)字段需要被頻繁修改,那可能不太適合建立索引。
5. 關(guān)系型數(shù)據(jù)庫(kù)的優(yōu)缺點(diǎn)
(1)優(yōu)點(diǎn)
—SQL支持非常復(fù)雜的查詢(xún),可以聯(lián)表查詢(xún)、使用正則表達(dá)式查詢(xún)、嵌套查詢(xún),還可以寫(xiě)一個(gè)獨(dú)立的SQL腳本。
上面的案例,—如果不使用SQL,那兩個(gè)查詢(xún)自己寫(xiě)代碼篩選數(shù)據(jù)也可以實(shí)現(xiàn),但是會(huì)比較麻煩,特別是數(shù)據(jù)量比較大的時(shí)候,如果算法寫(xiě)得不好,就容易有性能問(wèn)題。而使用DB數(shù)據(jù)的查詢(xún)性能就交給DB。它還是異步的,不會(huì)有堵塞頁(yè)面的情況。
(2)缺點(diǎn)
一般來(lái)說(shuō),存在以下缺點(diǎn):—
不方便橫向擴(kuò)展,例如給數(shù)據(jù)庫(kù)表添加一個(gè)字段,如果數(shù)據(jù)量達(dá)到億級(jí),那么這個(gè)操作的復(fù)雜性將會(huì)是非常可觀的。—
—海量數(shù)據(jù)用SQL聯(lián)表查詢(xún),性能將會(huì)非常差。
—關(guān)系型數(shù)據(jù)庫(kù)為了保持事務(wù)的一致性特點(diǎn),難以應(yīng)對(duì)高并發(fā)
(3)Web SQL被deprecated
在 w3c的文檔 上,可以看到:
—This document was on the W3C Recommendation track but specification work has stopped. The specification reached an impasse: all interested implementors have used the same SQL backend (Sqlite), but we need multiple independent implementations to proceed along a standardisation path.
大意是說(shuō)WebSQL現(xiàn)有的實(shí)現(xiàn)是基于現(xiàn)成的第三方SQLite,但是我們需要獨(dú)立的實(shí)現(xiàn)。火狐也不打算支持。也就是說(shuō)主要原因是web sql太過(guò)于依賴(lài)SQLite,或許W3C可能會(huì)在以后重新制訂一套標(biāo)準(zhǔn)。
雖然已經(jīng)不建議使用了,但是上面還是花了很多篇幅介紹web sql,主要是因?yàn)镾QL是通用的,我的主要目的并不是要向讀者介紹web sql的API,怎么使用web sql,而是給讀者介紹一些SQL的核心概念,如怎么建表,怎么插入數(shù)據(jù),畢竟SQL是通用的,就算再過(guò)個(gè)幾十年它也很難會(huì)過(guò)時(shí)。
接下來(lái)再介紹第二種數(shù)據(jù)庫(kù)非關(guān)系型數(shù)據(jù)庫(kù)
6. 非關(guān)系型數(shù)據(jù)庫(kù)
非關(guān)系型數(shù)據(jù)庫(kù)根據(jù)它的存儲(chǔ)特點(diǎn),常用的有:
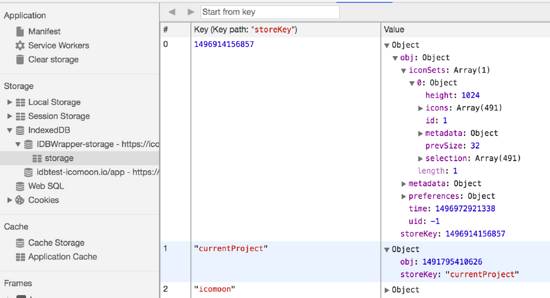
(1)key-value型,如Redis/IndexedDB,value可以為任意數(shù)據(jù)類(lèi)型,如下圖所示:
?? 
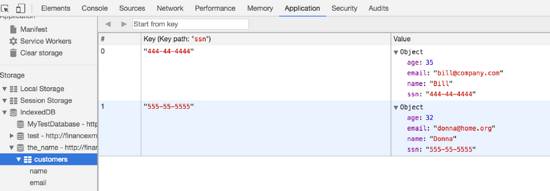
(2)json/document型,—如MongoDB,value按照一定的格式,可對(duì)value的字段做索引,IndexedDB也支持,如下圖所示:
?? 
非關(guān)系型數(shù)據(jù)庫(kù)也叫NoSQL數(shù)據(jù)庫(kù)。
—NoSQL是Not Only SQL的簡(jiǎn)寫(xiě),意思為不僅僅是SQL,但其實(shí)它和SQL沒(méi)什么關(guān)系,只是為了不讓人覺(jué)得它太異類(lèi)。它的特點(diǎn)是存儲(chǔ)比較靈活,但是查找沒(méi)有像關(guān)系型SQL一樣好用。適用于數(shù)據(jù)量很大,只需要單表key查詢(xún),一致性不用很高的場(chǎng)景。
7. IndexedDB
(1)IndexedDB的一些概念
IndexedDB是本地存儲(chǔ)的第三種方式,它是非關(guān)系型數(shù)據(jù)庫(kù)。它的建立數(shù)據(jù)庫(kù)、建表、插入數(shù)據(jù)等操作如下代碼如下,這里不進(jìn)行拆分講解,具體API細(xì)節(jié)讀者可查MDN等相關(guān)文檔。
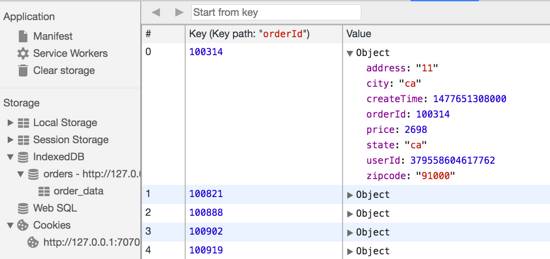
執(zhí)行完之后就有了一張order_data的表,如下所示:
?? 
—現(xiàn)在要查詢(xún)某個(gè)orderId的數(shù)據(jù),可執(zhí)行以下代碼:
結(jié)果如下圖所示:
?? 
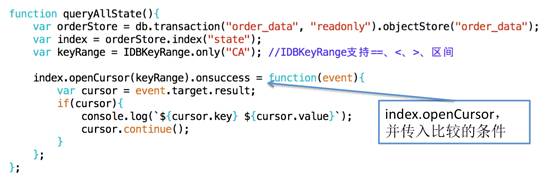
怎么查詢(xún)value字段里面的數(shù)據(jù)呢?如要查詢(xún)state為CA的訂單,那么給state這個(gè)字段添加一個(gè)索引就可以查詢(xún) 了,如下所示:
?? 
這里就可以知道,為什么要叫IndexedDB或者索引數(shù)據(jù)庫(kù)了,因?yàn)樗饕峭ㄟ^(guò)創(chuàng)建索引進(jìn)行查詢(xún)的。
上面只返回了一個(gè)結(jié)果,但是一般需要獲取全部的結(jié)果,就得使用游標(biāo)cursor,如下代碼所示:
?? 
打印結(jié)果如下:
?? 
IndexedDB還支持插入json格式不一樣的數(shù)據(jù),如下代碼:
結(jié)果如下圖所示:
?? 
(2)非關(guān)系型數(shù)據(jù)庫(kù)的橫向擴(kuò)展
上面說(shuō)關(guān)系型數(shù)據(jù)庫(kù)不利于橫向擴(kuò)展,而在一般的非關(guān)系型數(shù)據(jù)庫(kù)里面,每個(gè)數(shù)據(jù)存儲(chǔ)的類(lèi)型都可以不一樣,即每個(gè)key對(duì)應(yīng)的value的json字段格式可以不一致,所以不存在添加字段的問(wèn)題,而相同類(lèi)型的字段可以創(chuàng)建索引,提高查詢(xún)效率。
—NoSQL做不了復(fù)雜查詢(xún),如上面的案例要按照日期/city歸類(lèi)的話,需要自己打開(kāi)一個(gè)游標(biāo)循環(huán)做處理。所以我選擇用Web SQL主要是這個(gè)原因。
(3)兼容性
WebSQL兼容性如下caniuse所示:
?? 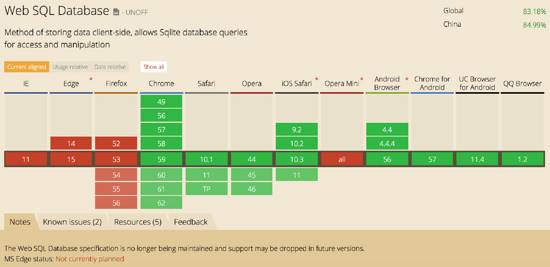
主要是IE和火狐不支持,而IndexedDB的兼容性會(huì)好很多:
?? 
8. 數(shù)據(jù)庫(kù)與Promise
—數(shù)據(jù)庫(kù)的查找,添加等都是異步操作,有時(shí)候你可能需要先發(fā)個(gè)請(qǐng)求獲取數(shù)據(jù),然后插入數(shù)據(jù),重復(fù)N次之后,再查詢(xún)數(shù)據(jù)。例如我需要先一條條地向谷歌服務(wù)器解析地址,再插入數(shù)據(jù)庫(kù),然后再做查詢(xún)。在查詢(xún)數(shù)據(jù)之前需要保證數(shù)據(jù)已經(jīng)都全部寫(xiě)到數(shù)據(jù)庫(kù)里面了,可以用Promise解決,在保證效率的同時(shí)達(dá)到目的。如下代碼所示:
?? 
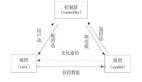
10. 分布式數(shù)據(jù)庫(kù)
—如果網(wǎng)站日訪問(wèn)量太大,一個(gè)數(shù)據(jù)庫(kù)服務(wù)很可能會(huì)扛不住,需要搞幾臺(tái)相同的數(shù)據(jù)庫(kù)服務(wù)器分擔(dān)壓力,但是要保證這幾個(gè)數(shù)據(jù)庫(kù)數(shù)據(jù)一致性。這個(gè)有很多解決方案,最簡(jiǎn)單的如mysql的repliaction:
?? 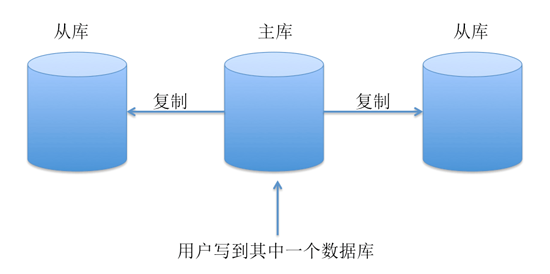
假設(shè)線上有3個(gè)數(shù)據(jù)庫(kù),用戶(hù)的一個(gè)操作寫(xiě)到了其中的一個(gè)數(shù)據(jù)庫(kù)里面,這個(gè)庫(kù)就叫主庫(kù)master,其它兩個(gè)庫(kù)叫從庫(kù)slave,主庫(kù)會(huì)把新數(shù)據(jù)遠(yuǎn)程復(fù)制到另外兩個(gè)從庫(kù)。
11. 數(shù)據(jù)庫(kù)備份
談到數(shù)據(jù)庫(kù)離不開(kāi)另外一個(gè)話題——備份,備份很重要,假設(shè)你的網(wǎng)站某一天被攻擊了,一夜之間幾十萬(wàn)個(gè)用戶(hù)的數(shù)據(jù)沒(méi)了,要是找不回來(lái),或者寫(xiě)了十年的博客全沒(méi)了,就真的得一夜白頭了。例如筆者會(huì)不對(duì)期地對(duì)自己的博客網(wǎng)站做備份:
?? 
用wordpress和db的備份文件,可以在一個(gè)小時(shí)之內(nèi)從0恢復(fù)整個(gè)博客網(wǎng)站。
備份mysql數(shù)據(jù)庫(kù)可以執(zhí)行mysqldump的命令,以root用戶(hù)的身份:
就可以把order這個(gè)數(shù)據(jù)庫(kù)備份起來(lái),恢復(fù)的時(shí)候只需執(zhí)行:
就可以把order這個(gè)數(shù)據(jù)庫(kù)導(dǎo)進(jìn)來(lái)。
綜合以上,本文談到了本地存儲(chǔ)的三種方式:
- localStorage/sessionStorage
- Web SQL
- IndexedDB
并比較了它們的特點(diǎn)。還談了下DB結(jié)合Promise做一些操作和SQL注入等。
最主要是分析了關(guān)系型數(shù)據(jù)庫(kù)和非關(guān)系型數(shù)據(jù)庫(kù)的特點(diǎn),關(guān)系型數(shù)據(jù)庫(kù)是一名老將,而非關(guān)系型隨著大數(shù)據(jù)的產(chǎn)生應(yīng)運(yùn)而生,但它又不局限于在大數(shù)據(jù)上使用。html5也增加了這兩種類(lèi)型的數(shù)據(jù)庫(kù),為做Web Application做好準(zhǔn)備。雖然Web SQL很早前被deprecated,但是只要你不用支持IE和Firefox還是可以用的,它的好處是查詢(xún)比較方便,而IndexedDB存儲(chǔ)比較靈活,查詢(xún)不方便。說(shuō)不定在不久的將來(lái)會(huì)有一種全新的web關(guān)系型數(shù)據(jù)庫(kù)出現(xiàn)。現(xiàn)在很多網(wǎng)站都使用IndexedDB存儲(chǔ)它們的數(shù)據(jù)。
所以可以?xún)烧邍L試學(xué)習(xí)和使用一下,一方面為做那種數(shù)據(jù)驅(qū)動(dòng)類(lèi)型的網(wǎng)頁(yè)提供便利,另一方面可以對(duì)數(shù)據(jù)庫(kù)的概念有所了解,知道后端是如何建表如何查詢(xún)數(shù)據(jù)返回給你的。