Linux內(nèi)存管理那些事兒
自馮諾伊曼已來(lái),計(jì)算機(jī)都是采用程序存儲(chǔ)架構(gòu)。
什么是程序存儲(chǔ)架構(gòu)?簡(jiǎn)單來(lái)說(shuō)就是把用來(lái)運(yùn)行的程序也當(dāng)做數(shù)據(jù)一樣存儲(chǔ)在計(jì)算機(jī)中。現(xiàn)在聽(tīng)起來(lái)這么簡(jiǎn)單的一個(gè)思想,***提出卻是了不起的貢獻(xiàn):里面包含了哥德?tīng)柧碌募香U摵蛨D靈美妙的圖靈機(jī)設(shè)想。最早的計(jì)算機(jī)器僅內(nèi)含固定用途的程序。現(xiàn)代的某些計(jì)算機(jī)依然維持這樣的設(shè)計(jì)方式,通常是為了簡(jiǎn)化或教育目的。例如一個(gè)計(jì)算器僅有固定的數(shù)學(xué)計(jì)算程序,它不能拿來(lái)當(dāng)作文字處理軟件,更不能拿來(lái)玩游戲。若想要改變此機(jī)器的程序,你必須更改線路、更改結(jié)構(gòu)甚至重新設(shè)計(jì)此機(jī)器。當(dāng)然最早的計(jì)算機(jī)并沒(méi)有設(shè)計(jì)的那么可編程化。當(dāng)時(shí)所謂的“重寫程序”很可能指的是紙筆設(shè)計(jì)程序步驟,接著制訂工程細(xì)節(jié),再施工將機(jī)器的電路配線或結(jié)構(gòu)改變。而程序存儲(chǔ)型電腦的概念改變了這一切。借由創(chuàng)造一組指令集結(jié)構(gòu),并將所謂的運(yùn)算轉(zhuǎn)化成一串程序指令的運(yùn)行細(xì)節(jié),讓此機(jī)器更有彈性。借著將指令當(dāng)成一種特別類型的靜態(tài)數(shù)據(jù),一臺(tái)存儲(chǔ)程序型電腦可輕易改變其程序,并在程控下改變其運(yùn)算內(nèi)容。
講這一段,就是要明確,在計(jì)算機(jī)中,準(zhǔn)確的說(shuō)是CPU中,程序和數(shù)據(jù)都是存儲(chǔ)在計(jì)算機(jī)的內(nèi)存或者硬盤中的,要使用時(shí),都是要經(jīng)過(guò)尋址來(lái)找出來(lái)加載到CPU中的。內(nèi)存只是更快的硬盤,以下將會(huì)使用內(nèi)存紙袋存儲(chǔ),忽略內(nèi)存到硬盤的換入換出。
內(nèi)存地址本質(zhì)上對(duì)應(yīng)物理硬件上的地址引腳。使用內(nèi)存地址訪問(wèn)物理存儲(chǔ)天經(jīng)地義,內(nèi)存地址和物理地址一一對(duì)應(yīng),也是天經(jīng)地義。內(nèi)存地址就是物理地址,這就是“實(shí)模式”。
那是什么時(shí)候內(nèi)存地址有了“邏輯地址”,“線性地址”,“虛擬地址”,“物理地址”等,這些稱呼?
這一切都要從80286說(shuō)起,Intel微處理器從這個(gè)版本開(kāi)始引入了“保護(hù)模式”,也是就是內(nèi)存地址的分段表示。顧名思義,這是為了內(nèi)存保護(hù)的目的(還有就是分離用戶空間和內(nèi)核空間)。這樣內(nèi)存地址不再是物理地址了,而僅僅是一個(gè)偏移量了,原來(lái)的內(nèi)存地址變成了邏輯地址,而這個(gè)偏移量則是“線性地址”或“虛擬地址”。要獲得物理就需要在自己所在的段中去找(下面提到的段描述中有一個(gè)基地址)!為此,Intel引入了段描述符以及保護(hù)目的的鑒權(quán)屬性,結(jié)合“程序存儲(chǔ)”的概念,至少存在兩種段描述符:代碼段描述符和數(shù)據(jù)段描述符。如何找到內(nèi)存地址所在的段描述符呢?Intel又引入段選擇子,以及鑒權(quán)屬性。這樣使用段選擇子就是可以找到段描述符,再使用原來(lái)的內(nèi)存地址作為偏移量來(lái)找到真正的物理地址了。但是從實(shí)模式到保護(hù)模式,只有一個(gè)地址序號(hào),哪里去找段選擇子和段描述符呢?Intel引入了一些段寄存器來(lái)存儲(chǔ)段選擇子,當(dāng)然至少是代碼段寄存器和數(shù)據(jù)段寄存器。而內(nèi)核在啟動(dòng)時(shí)會(huì)建立全局段描述符表,這樣一切都解決了。為了加快段描述符表的訪問(wèn)(否則又是瓶頸),Intel又引入了不可編程的段描述符寄存器,隨著段寄出器加載而加載。這就是鼎鼎大名的影子寄存器。
現(xiàn)在看來(lái),這次失敗的設(shè)計(jì)還是挺成功的。
Linux就直接繞過(guò)了分段機(jī)制。分段機(jī)制引入段選擇子和段描述符把地址空間轉(zhuǎn)換成偏移量,Linux通過(guò)為所有程序設(shè)置相同的段選擇子和段描述符,把偏移量又轉(zhuǎn)換成地址空間,一切又回到了原點(diǎn)。
看看分頁(yè)是多么簡(jiǎn)單和優(yōu)雅。以32位地址空間為例,分為三段(10,10,12),分別是作為頁(yè)目錄,頁(yè)表和頁(yè)框的索引,即可訪問(wèn)32G的物理內(nèi)存。只需要存儲(chǔ)頁(yè)目錄一個(gè)寄存器(cr3)即可。
在整個(gè)尋址的過(guò)程中,TLB緩存是至關(guān)主要的。TLB緩存內(nèi)存線性地址到物理地址的直接映射,你說(shuō)重要不重要?
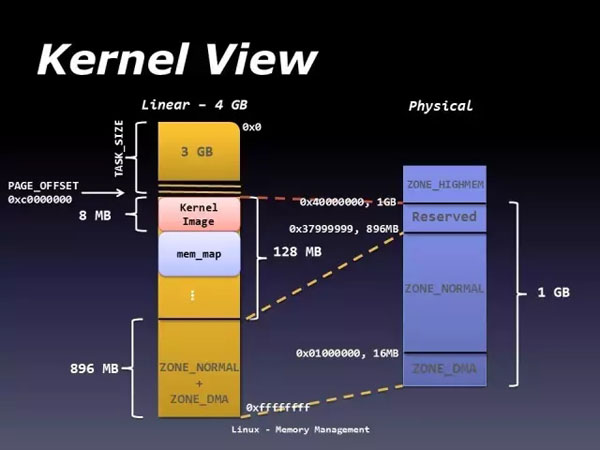
TLB緩存還間接了影響了地址空間架構(gòu)。我們知道Linux環(huán)境下32位系統(tǒng)進(jìn)程地址空間是4G,這4G地址空間用戶態(tài)占3G,內(nèi)核態(tài)占1G。并且用戶態(tài)各個(gè)進(jìn)程的地址空間是獨(dú)立的,也就是每個(gè)進(jìn)程都可以訪問(wèn)0到3G的進(jìn)程地址空間。而內(nèi)核態(tài)的進(jìn)程地址空間是所有進(jìn)程共享的,即所有進(jìn)程共用1個(gè)的地址空間。(更準(zhǔn)確的說(shuō)法是把內(nèi)核地址空間映射到所有進(jìn)程的地址空間)。內(nèi)核為什么這么設(shè)計(jì)呢?為什么要?jiǎng)澐钟脩艨臻g和內(nèi)核空間呢?答案就在TLB 緩存:因?yàn)樵趦?nèi)核空間進(jìn)入/退出時(shí),刷新整個(gè)TLB的代價(jià)太高了。
- In the i386 arch, for example, we choose to map the kernel into every process's VM space so that we don't have to pay the full TLB invalidation costs for kernel entry/exit. This means the available virtual memory space (4GiB on i386) has to be divided between user and kernel space.
和TLB緩存相關(guān)還有一個(gè)重要的概念是hugepage。hugepage支持建立在大多數(shù)現(xiàn)代處理器架構(gòu)提供的多頁(yè)大小支持之上。例如,x86 CPU通常支持4K和2M(1G,如果架構(gòu)支持)頁(yè)面大小,ia64 架構(gòu)支持多頁(yè)大小4K,8K,64K,256K,1M,4M,16M,256M以及ppc64支持4K和16M。隨著越來(lái)越大的物理存儲(chǔ)器(幾GB)更容易獲得,TLB的優(yōu)化更為關(guān)鍵。
TLB 駐留在CPU的1級(jí)cache里,是芯片訪問(wèn)最快的緩存,一般只能容納100多條頁(yè)表項(xiàng),如果采用hugepage,則可以極大減少 TLB cache miss 導(dǎo)致的開(kāi)銷:TLB***,立即就獲取到物理地址,如果不***,需要查 rc3->進(jìn)程頁(yè)目錄表pgd->進(jìn)程頁(yè)中間表pmd->進(jìn)程頁(yè)框->物理內(nèi)存,如果這中間pmd或者頁(yè)框被虛擬內(nèi)存系統(tǒng)替換到交互區(qū),則還需要交互區(qū)load回內(nèi)存。。總之,TLB cache miss是性能大殺手,而采用hugepage可以有效降低TLB cache miss。
一旦大量的頁(yè)面被預(yù)分配給內(nèi)核作為hugepage的頁(yè)面池,這些頁(yè)面將在內(nèi)核中保留,不能用于其他目的。內(nèi)核使用名字為“hugetlbfs” 的文件系統(tǒng)管理這些頁(yè)面池。當(dāng)支持多個(gè)hugepage大小時(shí),/proc/sys/vm/nr_hugepages指示預(yù)先分配的大量頁(yè)面的默認(rèn)大小的當(dāng)前數(shù)量。因此,可以使用以下命令來(lái)動(dòng)態(tài)分配/取消分配默認(rèn)大小的持續(xù)hugepage:
echo 20 > /proc/sys/vm/nr_hugepages
該命令將嘗試將hugepage頁(yè)面池中的默認(rèn)大小的hugepage的數(shù)量調(diào)整為20 ,根據(jù)需要分配或釋放hugepage。
/proc/meminfo文件提供有關(guān)內(nèi)核hugepage池中持久hugetlb頁(yè)面總數(shù)的信息。它還顯示有關(guān)免費(fèi),預(yù)留和剩余hugepage數(shù)量以及默認(rèn)頁(yè)面大小的信息。“cat /proc/meminfo”的輸出將包括以下行:
- .....
- HugePages_Total: vvv
- HugePages_Free: www
- HugePages_Rsvd: xxx
- HugePages_Surp: yyy
- Hugepagesize: zzz kB
其中: HugePages_Total是hugepage頁(yè)面池的大小。 HugePages_Free是池中尚未分配的hugepage數(shù)。 HugePages_Rsvd是“保留” 的縮寫,是從池中分配的承諾的hugepage的數(shù)量,但尚未分配。保留hugepage保證應(yīng)用程序能夠在故障時(shí)間從hugepage頁(yè)面池中分配一個(gè)hugepage。 HugePages_Surp是“剩余”的縮寫,是 /proc/sys/vm/nr_hugepages中的值之上的hugepage數(shù)。剩余hugepage的***數(shù)量由/proc/sys/vm/nr_overcommit_hugepages控制。
由于內(nèi)核1G地址空間的限制,對(duì)于高端內(nèi)存(物理地址空間大于虛擬地址空間的情況),內(nèi)核無(wú)法同時(shí)映射所有物理內(nèi)存,這意味著當(dāng)使用這些內(nèi)存時(shí),內(nèi)核使用臨時(shí)映射。
說(shuō)到高端內(nèi)存,不禁想起了物理地址擴(kuò)展。處理器所支持的RAM容量受鏈接到地址總線上的地址管腳數(shù)限制。早起Intel處理器從80386到Pentium使用32位物理地址。從理論上講,這樣的系統(tǒng)上可以安裝高達(dá)4GB的RAM,而實(shí)際上,由于用戶進(jìn)程線性地址空間的需要,內(nèi)核不能直接對(duì)1GB以上的RAM進(jìn)行尋址。然而,大型服務(wù)器需要大于4GB的RAM來(lái)同時(shí)運(yùn)行上千的進(jìn)程,實(shí)際上我們現(xiàn)在的很多計(jì)算機(jī)的RAM都可能超過(guò)這個(gè)量級(jí)。Intel通過(guò)在它的處理器上把管腳數(shù)從32增加到36已經(jīng)滿足了這些需求。從Pentium Pro開(kāi)始,Intel所有的處理器現(xiàn)在的尋址能力達(dá)2^36=64GB.不過(guò),只有引入一種新的分頁(yè)機(jī)制把32位線性地址轉(zhuǎn)換為36位物理地址才能使用所增加的物理地址。顯然,PAE并沒(méi)有擴(kuò)大進(jìn)程的線性地址空間,因?yàn)樗荒芴幚砦锢淼刂罚送猓挥袃?nèi)核能夠修改進(jìn)程的頁(yè)表,所以用戶態(tài)下運(yùn)行的進(jìn)程不能使用大于4GB的物理地址空間。另一方面,PAE允許內(nèi)核使用高達(dá)64GB的RAM,從而顯著增加了系統(tǒng)中的進(jìn)程數(shù)量。
【本文是51CTO專欄作者石頭的原創(chuàng)文章,轉(zhuǎn)載請(qǐng)通過(guò)作者微信公眾號(hào)補(bǔ)天遺石(butianys)獲取授權(quán)】