京東分布式服務跟蹤系統(tǒng)-CallGraph
一、CallGraph的產(chǎn)生背景
隨著京東業(yè)務的高速增長,京東研發(fā)體系陸續(xù)實施了SOA化和微服務戰(zhàn)略,以應對日益復雜的業(yè)務和急劇增加的應用種類。這些分布式應用彼此依賴,共同協(xié)作來完成所有京東的業(yè)務場景,其動態(tài)變化的復雜性和數(shù)量已超出想象,對其進行監(jiān)控并試圖掌控全局已非人力所及,迫切需要一種軟件工具來幫助相關人員理解系統(tǒng)行為,從而為諸如流程優(yōu)化、架構優(yōu)化、程序優(yōu)化、以及擴容、限流、降級等運維行為提供科學的客觀依據(jù)。
CallGraph根據(jù)Google為其基于日志的分布式跟蹤系統(tǒng)Dapper發(fā)表的論文,由京東商城基礎平臺部自主研發(fā),目前已經(jīng)上線。業(yè)界亦有類似系統(tǒng),比如淘寶鷹眼、新浪WatchMan等等,但是CallGraph除了提供與這些系統(tǒng)類似的功能外,還有其自身的特色,下文將詳細講解。
二、CallGraph的核心概念
“調(diào)用鏈”是CallGraph最重要的概念,一條調(diào)用鏈包含了從源頭請求(比如前端網(wǎng)頁請求、無線客戶端請求等)到***底層系統(tǒng)(比如數(shù)據(jù)庫、分布式緩存等)的所有中間環(huán)節(jié),如下圖所示。
用鏈")
每次調(diào)用,都會在源頭請求中產(chǎn)生一個全局唯一的ID(稱為“TraceId”),通過網(wǎng)絡依次將TraceId傳到下一個環(huán)節(jié),該過程被稱為“透明數(shù)據(jù)傳輸”(簡稱“透傳”),圖中的每一個環(huán)節(jié)都會生成包含TraceId在內(nèi)的日志信息,通過TraceId將散落在調(diào)用鏈中不同系統(tǒng)上的“孤立”日志聯(lián)系在一起,然后通過日志分析,重組還原出更多有價值的信息。
三、CallGraph的特性及使用場景
CallGraph本質(zhì)上是一種監(jiān)控系統(tǒng),但它提供了一般監(jiān)控系統(tǒng)所沒有的特性,每種特性都有其典型使用場景,為相關人員提供了強大的問題排查手段和決策依據(jù),現(xiàn)總結如下:

四、CallGraph的設計目標
針對CallGraph這樣的監(jiān)控系統(tǒng),特制定了如下設計目標:
1. 低侵入性
作為非業(yè)務系統(tǒng),應當盡可能少侵入或者不侵入其他業(yè)務系統(tǒng),保持對使用方的透明性,這樣可以大大減少開發(fā)人員的負擔和接入門檻。
2. 低性能影響
CallGraph通過對各中間件jar包進行改造,完成日志數(shù)據(jù)的產(chǎn)生和收集,我們稱這種改造為“埋點”。由于埋點都發(fā)生在業(yè)務核心流程上,所以應該盡***努力降低對業(yè)務系統(tǒng)造成的性能影響。
3. 靈活的應用策略
為了消除業(yè)務方因使用CallGraph會對其自身產(chǎn)生影響的擔憂,應該提供靈活的配置策略,以讓業(yè)務方?jīng)Q定是否開啟跟蹤,以及收集數(shù)據(jù)的范圍和粒度,并提供技術手段保障配置必須生效。
4. 時效性(time-efficient)
從數(shù)據(jù)的產(chǎn)生和收集,到數(shù)據(jù)計算/處理,再到展現(xiàn),都要求盡可能快速。
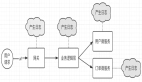
五、CallGraph的實現(xiàn)架構
架構")
1. CallGraph核心包
Callgraph-核心包被各中間件jar包引用,核心包里完成了具體的埋點邏輯,各中間件在合適的地方調(diào)用核心包提供的API來完成埋點;核心包產(chǎn)生的日志被存放在內(nèi)存磁盤上,由日志收集Agent發(fā)送到JMQ里。
(1)JMQ
JMQ是京東的分布式消息隊列,利用其強勁的性能,充當日志數(shù)據(jù)管道,Storm將不斷地消費里面的日志數(shù)據(jù)。
(2)Storm
利用Storm進行流式計算,對日志數(shù)據(jù)并行進行整理和各種計算,并將結果分別存放到實時數(shù)據(jù)存儲和離線數(shù)據(jù)存儲中。
(3)存儲
包括實時數(shù)據(jù)和離線數(shù)據(jù)兩部分存儲。實時數(shù)據(jù)部分包括了Jimdb、Hbase和ES,Jimdb是京東自己的分布式緩存系統(tǒng),里存放了調(diào)用量、TP等實時指標數(shù)據(jù);利用Hbase的SchemaLess特性,存放了固化后的鏈路數(shù)據(jù),因為不同的鏈路包含的中間環(huán)節(jié)數(shù)量不一樣,無法用像Mysql這樣的強Schema特性的存儲,利用TraceId就可以從Hbase里查詢到某一次調(diào)用的所有中間環(huán)節(jié)的信息。離線數(shù)據(jù)部分包括HDFS和Spark,用于海量歷史數(shù)據(jù)分析,并且還會把一些結果存放到Mysql中。
(4)CallGraph-UI
這是CallGraph提供給用戶的交互界面,在這里面用戶可以查看屬于自己的所有系統(tǒng)以及各系統(tǒng)內(nèi)的應用的調(diào)用鏈路的詳細情況,包括應用間的相互依賴關系圖,某種服務方法的來源分析、入口分析、路徑分析,以及某次具體的調(diào)用鏈路的詳情等等,還可以對應用進行諸如“采樣率”等配置的設置。
(5)UCC
UCC是京東自己的分布式配置系統(tǒng),CallGraph用它來存放所有的配置信息,并且同步到應用服務器本地的配置文件中。核心包將定期檢查這些配置文件,以使配置生效。當UCC故障后,也可以通過直接操縱本地配置文件,使配置生效。
(6)管理元數(shù)據(jù)
存放CallGraph的管理元數(shù)據(jù),比如鏈路簽名與應用的映射關系、鏈路簽名與服務方法的映射關系等等;
2. CallGraph的技術實現(xiàn)
(1)埋點和調(diào)用上下文透傳
該部分屬于架構圖中的CallGraph-核心包的重點部分,也是難點部分。CallGraph-核心包完成埋點邏輯,如下圖所示:

前端應用和各中間件jar包引入CallGraph核心包,前端應用利用Web容器的Filter機制調(diào)用核心包的startTrace開啟跟蹤,收到響應后調(diào)用endTrace結束此次跟蹤,各中間件在合適的地方調(diào)用核心包提供的clientSend、serverRecv、serverSend和clientRecv等原語API,其中,橙色的完成“創(chuàng)建上下文”,綠色的完成“生成日志”。
對于進程間的上下文透傳,調(diào)用上下文放在本地ThreadLocal,對業(yè)務透明,調(diào)用上下文在中間件的網(wǎng)絡請求中傳遞,并在對端收到后進行重組還原出調(diào)用上下文,過程如下圖所示:

對于異步調(diào)用,將涉及到線程間上下文透傳,通過java字節(jié)碼增強的方式在CallGraph核心包載入期織入增強邏輯,以透明的方式完成線程間上下文的透傳。這里又可分為兩種類型,一種是直接創(chuàng)建新線程的方式,如下圖所示,
用")
這種方式通過對JDK線程對象(Thread)進行增強完成,子線程將把父線程的上下文作為自己的上下文(圖中的“子上下文”);對于使用Java線程池來提交異步任務來說,就不存在“父子”線程關系了,這時通過對各種JDK線程池的增強,實現(xiàn)了上下文透傳,如下圖所示:

上述過程對開發(fā)人員完全透明,對運維人員來說也很方便,做到了“低侵入性”。
六、日志格式設計
CallGraph的日志格式需要滿足不同中間件的特定要求,同時還要保證版本的兼容性。總體上說,CallGraph的日志格式分成固定部分和可變部分,其中固定部分由如下組成:
- TraceId,RpcId,開始時間,調(diào)用類型,對端IP
- 調(diào)用耗時
- 調(diào)用結果
- 與中間件相關的數(shù)據(jù):比如rpc調(diào)用的接口、方法,mq的topic名稱等
- 通信負載量
- 請求字節(jié)數(shù)/響應字節(jié)數(shù)
可變部分最重要的就是“自定義數(shù)據(jù)”,用戶可以使用CallGraph-核心包API增加自己的特殊字段,以用于特殊目的。通過抽象設計,不同場景的日志格式都有專門的encoder類,在輸出日志時配套使用。
1. 高性能的鏈路日志輸出
為了徹底避免和業(yè)務競爭I/O資源,CallGraph專門在應用服務器上開辟專門的內(nèi)存區(qū)域,并虛擬成磁盤設備,核心包產(chǎn)生的日志存放在這樣的內(nèi)存磁盤上,完全不占用磁盤I/O,并且速度極快。同時開發(fā)專門的日志模塊,日志輸出采取批量、異步方式寫入內(nèi)存磁盤,并在日志量過大時采取“丟棄日志”的方式***程度地降低對業(yè)務的影響,如下圖所示:

2. TP日志和鏈路日志分離
為了***程度減少對業(yè)務性能的影響,在實踐中,多數(shù)情況下會開啟“采樣率”機制,比如1000次調(diào)用,只收集1次調(diào)用的信息,這樣可以極大地降低日志產(chǎn)生量。但是對于TP指標來說,必須記錄每次調(diào)用的TP值,否則提供的TP50、TP99、TP999指標將不準確,從而變得無意義。從本質(zhì)上說,鏈路信息和TP性能指標是兩種不同屬性的數(shù)據(jù),因此在核心包里分別對這兩種數(shù)據(jù)進行獨立處理,彼此互不影響,采用各自的日志收集及輸出策略,TP指標的處理如下圖所示:

3. 實時配置
當雙11或者618大促時,各業(yè)務系統(tǒng)為了確保業(yè)務正常,基本上都會對非業(yè)務系統(tǒng)采取降級的手段。CallGraph為滿足業(yè)務方的這種需求,提供了豐富的配置和降級手段。CallGraph提供了基于應用、應用分組、應用服務器IP等多維度的配置方式,每個維度上都提供了“是否開啟鏈路跟蹤”、“鏈路采樣率”、“是否開啟TP跟蹤”、“TP顆粒度”等配置項,來供業(yè)務方根據(jù)情況來使用。
業(yè)務方通過CallGraph-UI管理端自助設置業(yè)務的各配置項。全部配置信息存放在UCC(京東的分布式配置系統(tǒng))上,同時也會同步到應用服務器的本地配置文件中。CallGraph-核心包有專門的Daemon線程定期訪問本地的這些配置文件,以使配置生效;當UCC出現(xiàn)故障,不能被正常訪問時,也可以直接操縱這些本地配置文件,確保配置立即生效。
4. storm流式計算
所有日志,不管是鏈路日志還是TP日志,***都必須經(jīng)過storm進行計算產(chǎn)生結果數(shù)據(jù),并分別存儲到實時數(shù)據(jù)存儲和離線數(shù)據(jù)存儲中,如下圖所示:

離線分析Bolt由一系列Bolt組成,它們分析鏈路日志信息,負責產(chǎn)生符合離線數(shù)據(jù)模型的結果數(shù)據(jù),后續(xù)將由大數(shù)據(jù)技術比如spark/flume等進行計算,得到大時間尺度下的固定后的鏈路的一些特征指標,比如調(diào)用次數(shù)、平均耗時、錯誤率等等。
實時分析Bolt分析TP日志信息,負責生成實時指標數(shù)據(jù),并存儲在Jimdb中,供CallGraph-UI調(diào)用展示。
5. 實時數(shù)據(jù)分析-秒級監(jiān)控
這是CallGraph區(qū)別與其他類似系統(tǒng)的一大功能。其他類似系統(tǒng)只提供鏈路日志分析,而鏈路日志的分析需要積累海量數(shù)據(jù),然后借助大數(shù)據(jù)相關技術進行分析,其實時性較低。針對業(yè)務方對實時分析的需求,CallGraph采用分布式緩存系統(tǒng)Jimdb來存放實時數(shù)據(jù),針對來源分析、入口分析、鏈路分析等可以提供1小時內(nèi)的實時分析結果(Jimdb中的數(shù)據(jù)設置過期時間,自動過期),其中涉及到調(diào)用量、調(diào)用量占比、TP性能指標等的展示,該功能被內(nèi)部稱為“秒級監(jiān)控”。“秒級監(jiān)控”需要對TP日志進行分析,原理如下圖所示:
控”需要對TP日志進行分析的原理")
LogRealTimeBolt將從LogTPSpout中得到TP原始日志,進行整理、分析和計算,并將結果暫時緩存在“本地緩存”中,當達到累積計數(shù)條件后,再批量地匯總到Jimdb存儲中,這樣做的好處是先在本地進行合并計算,另外也減少了Jimdb的I/O次數(shù)。
七、CallGraph的未來之路
CallGraph在京東的歷史還很短,將來還有很長的路要走。為了進一步滿足業(yè)務方對CallGraph的需求,未來CallGraph將陸續(xù)完善和提供如下功能:
- 進一步優(yōu)化實時數(shù)據(jù)的處理機制,使得時延更低,達到真正的“實時”;目前該功能由于需要經(jīng)過日志收集、JMQ以及storm等過程,所以存在十幾秒到幾十秒鐘的時延,屬于“準實時”的范疇;
- 完善實時的錯誤發(fā)現(xiàn)及報警機制,進一步提高發(fā)現(xiàn)問題的及時性;
- 接入更多的中間件,進一步豐富調(diào)用鏈內(nèi)容,使調(diào)用鏈更長更完整;
- 提供完整的API接口,將調(diào)用鏈數(shù)據(jù)共享給兄弟團隊,方便他們構建自己的調(diào)用鏈分析系統(tǒng);
- 借助深度學習算法,進一步挖掘調(diào)用鏈歷史數(shù)據(jù)的價值,力爭在更多維度上提供出有價值的分析數(shù)據(jù)。
【本文來自51CTO專欄作者張開濤的微信公眾號(開濤的博客),公眾號id: kaitao-1234567】