一文讀懂Hadoop、HBase、Hive、Spark分布式系統架構
機器學習、數據挖掘等各種大數據處理都離不開各種開源分布式系統,hadoop用戶分布式存儲和map-reduce計算,spark用于分布式機器學習,hive是分布式數據庫,hbase是分布式kv系統,看似互不相關的他們卻都是基于相同的hdfs存儲和yarn資源管理,本文通過全套部署方法來讓大家深入系統內部以充分理解分布式系統架構和他們之間的關系
本文結構
首先,我們來分別部署一套hadoop、hbase、hive、spark,在講解部署方法過程中會特殊說明一些重要配置,以及一些架構圖以幫我們理解,目的是為后面講解系統架構和關系打基礎。
之后,我們會通過運行一些程序來分析一下這些系統的功能
最后,我們會總結這些系統之間的關系
分布式hadoop部署
首先,在 http://hadoop.apache.org/releases.html 找到最新穩定版tar包,我選擇的是
http://apache.fayea.com/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
下載到 /data/apache 并解壓
在真正部署之前,我們先了解一下 hadoop 的架構
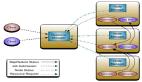
hadoop分為幾大部分:yarn負責資源和任務管理、hdfs負責分布式存儲、map-reduce負責分布式計算
先來了解一下yarn的架構:
yarn的兩個部分:資源管理、任務調度。
資源管理需要一個全局的ResourceManager(RM)和分布在每臺機器上的NodeManager協同工作,RM負責資源的仲裁,NodeManager負責每個節點的資源監控、狀態匯報和Container的管理
任務調度也需要ResourceManager負責任務的接受和調度,在任務調度中,在Container中啟動的ApplicationMaster(AM)負責這個任務的管理,當任務需要資源時,會向RM申請,分配到的Container用來起任務,然后AM和這些Container做通信,AM和具體執行的任務都是在Container中執行的
yarn區別于第一代hadoop的部署(namenode、jobtracker、tasktracker)
然后再看一下hdfs的架構:hdfs部分由NameNode、SecondaryNameNode和DataNode組成。DataNode是真正的在每個存儲節點上管理數據的模塊,NameNode是對全局數據的名字信息做管理的模塊,SecondaryNameNode是它的從節點,以防掛掉。
最后再說map-reduce:Map-reduce依賴于yarn和hdfs,另外還有一個JobHistoryServer用來看任務運行歷史
hadoop雖然有多個模塊分別部署,但是所需要的程序都在同一個tar包中,所以不同模塊用到的配置文件都在一起,讓我們來看幾個最重要的配置文件:
各種默認配置:core-default.xml, hdfs-default.xml, yarn-default.xml, mapred-default.xml
各種web頁面配置:core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml
從這些配置文件也可以看出hadoop的幾大部分是分開配置的。
除上面這些之外還有一些重要的配置:hadoop-env.sh、mapred-env.sh、yarn-env.sh,他們用來配置程序運行時的java虛擬機參數以及一些二進制、配置、日志等的目錄配置
下面我們真正的來修改必須修改的配置文件。
修改etc/hadoop/core-site.xml,把配置改成:
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://127.0.0.1:8000</value>
- </property>
- <property>
- <name>io.file.buffer.size</name>
- <value>131072</value>
- </property>
- </configuration>
這里面配置的是hdfs的文件系統地址:本機的9001端口
修改etc/hadoop/hdfs-site.xml,把配置改成:
- <configuration>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/data/apache/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/data/apache/dfs/data</value>
- </property>
- <property>
- <name>dfs.datanode.fsdataset.volume.choosing.policy</name>
- <value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
- </property>
- <property>
- <name>dfs.namenode.http-address</name>
- <value>127.0.0.1:50070</value>
- </property>
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>127.0.0.1:8001</value>
- </property>
- </configuration>
這里面配置的是hdfs文件存儲在本地的哪里以及secondary namenode的地址
修改etc/hadoop/yarn-site.xml,把配置改成:
- <configuration>
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>127.0.0.1</value>
- </property>
- <property>
- <name>yarn.resourcemanager.webapp.address</name>
- <value>127.0.0.1:8088</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
- <property>
- <name>yarn.log-aggregation-enable</name>
- <value>true</value>
- </property>
- <property>
- <name>yarn.log-aggregation.retain-seconds</name>
- <value>864000</value>
- </property>
- <property>
- <name>yarn.log-aggregation.retain-check-interval-seconds</name>
- <value>86400</value>
- </property>
- <property>
- <name>yarn.nodemanager.remote-app-log-dir</name>
- <value>/YarnApp/Logs</value>
- </property>
- <property>
- <name>yarn.log.server.url</name>
- <value>http://127.0.0.1:19888/jobhistory/logs/</value>
- </property>
- <property>
- <name>yarn.nodemanager.local-dirs</name>
- <value>/data/apache/tmp/</value>
- </property>
- <property>
- <name>yarn.scheduler.maximum-allocation-mb</name>
- <value>5000</value>
- </property>
- <property>
- <name>yarn.scheduler.minimum-allocation-mb</name>
- <value>1024</value>
- </property>
- <property>
- <name>yarn.nodemanager.vmem-pmem-ratio</name>
- <value>4.1</value>
- </property>
- <property>
- <name>yarn.nodemanager.vmem-check-enabled</name>
- <value>false</value>
- </property>
- </configuration>
這里面配置的是yarn的日志地址以及一些參數配置
通過cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml創建etc/hadoop/mapred-site.xml,內容改為如下:
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- <description>Execution framework set to Hadoop YARN.</description>
- </property>
- <property>
- <name>yarn.app.mapreduce.am.staging-dir</name>
- <value>/tmp/hadoop-yarn/staging</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>127.0.0.1:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>127.0.0.1:19888</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.done-dir</name>
- <value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.intermediate-done-dir</name>
- <value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.joblist.cache.size</name>
- <value>1000</value>
- </property>
- <property>
- <name>mapreduce.tasktracker.map.tasks.maximum</name>
- <value>8</value>
- </property>
- <property>
- <name>mapreduce.tasktracker.reduce.tasks.maximum</name>
- <value>8</value>
- </property>
- <property>
- <name>mapreduce.jobtracker.maxtasks.perjob</name>
- <value>5</value>
- <description>The maximum number of tasks for a single job.
- A value of -1 indicates that there is no maximum.
- </description>
- </property>
- </configuration>
這里面配置的是mapred的任務歷史相關配置
如果你的hadoop部署在多臺機器,那么需要修改etc/hadoop/slaves,把其他slave機器ip加到里面,如果只部署在這一臺,那么就留一個localhost即可
下面我們啟動hadoop,啟動之前我們配置好必要的環境變量:
- export JAVA_HOME="你的java安裝地址"
先啟動hdfs,在此之前要格式化分布式文件系統,執行:
- ./bin/hdfs namenode -format myclustername
如果格式化正常可以看到/data/apache/dfs下生成了name目錄
然后啟動namenode,執行:
- ./sbin/hadoop-daemon.sh --script hdfs start namenode
如果正常啟動,可以看到啟動了相應的進程,并且logs目錄下生成了相應的日志
然后啟動datanode,執行:
- ./sbin/hadoop-daemon.sh --script hdfs start datanode
如果考慮啟動secondary namenode,可以用同樣的方法啟動
下面我們啟動yarn,先啟動resourcemanager,執行:
- ./sbin/yarn-daemon.sh start resourcemanager
如果正常啟動,可以看到啟動了相應的進程,并且logs目錄下生成了相應的日志
然后啟動nodemanager,執行:
- ./sbin/yarn-daemon.sh start nodemanager
如果正常啟動,可以看到啟動了相應的進程,并且logs目錄下生成了相應的日志
然后啟動MapReduce JobHistory Server,執行:
- ./sbin/mr-jobhistory-daemon.sh start historyserver
如果正常啟動,可以看到啟動了相應的進程,并且logs目錄下生成了相應的日志
下面我們看下web界面
打開 http://127.0.0.1:8088/cluster 看下yarn管理的集群資源情況(因為在yarn-site.xml中我們配置了yarn.resourcemanager.webapp.address是127.0.0.1:8088)
打開 http://127.0.0.1:19888/jobhistory 看下map-reduce任務的執行歷史情況(因為在mapred-site.xml中我們配置了mapreduce.jobhistory.webapp.address是127.0.0.1:19888)
打開 http://127.0.0.1:50070/dfshealth.html 看下namenode的存儲系統情況(因為在hdfs-site.xml中我們配置了dfs.namenode.http-address是127.0.0.1:50070)
到此為止我們對hadoop的部署完成。下面試驗一下hadoop的功能
先驗證一下hdfs分布式文件系統,執行以下命令看是否有輸出:
- [root@MYAY hadoop]# ./bin/hadoop fs -mkdir /input
- [root@MYAY hadoop]# cat data
- 1
- 2
- 3
- 4
- [root@MYAY hadoop]# ./bin/hadoop fs -put input /input
- [root@MYAY hadoop]# ./bin/hadoop fs -ls /input
- Found 1 items
- -rw-r--r-- 3 root supergroup 8 2016-08-07 15:04 /input/data
這時通過 http://127.0.0.1:50070/dfshealth.html 可以看到存儲系統的一些變化
下面我們以input為輸入啟動一個mapreduce任務
- [root@MYAY hadoop]# ./bin/hadoop jar ./share/hadoop/tools/lib/hadoop-streaming-2.7.2.jar -input /input -output /output -mapper cat -reducer wc
之后看是否產生了/output的輸出:
- [root@MYAY hadoop]# ./bin/hadoop fs -ls /output
- Found 2 items
- -rw-r--r-- 3 root supergroup 0 2016-08-07 15:11 /output/_SUCCESS
- -rw-r--r-- 3 root supergroup 25 2016-08-07 15:11 /output/part-00000
- [root@MYAY hadoop]# ./bin/hadoop fs -cat /output/part-00000
- 4 4 12
這時通過 http://127.0.0.1:19888/jobhistory 可以看到mapreduce任務歷史:
也可以通過 http://127.0.0.1:8088/cluster 看到任務歷史
為什么兩處都有歷史呢?他們的區別是什么呢?
我們看到cluster顯示的其實是每一個application的歷史信息,他是yarn(ResourceManager)的管理頁面,也就是不管是mapreduce還是其他類似mapreduce這樣的任務,都會在這里顯示,mapreduce任務的Application Type是MAPREDUCE,其他任務的類型就是其他了,但是jobhistory是專門顯示mapreduce任務的
hbase的部署
首先從 http://www.apache.org/dyn/closer.cgi/hbase/ 下載穩定版安裝包,我下的是https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/stable/hbase-1.2.2-bin.tar.gz
解壓后修改conf/hbase-site.xml,改成:
- <configuration>
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- </property>
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://127.0.0.1:8001/hbase</value>
- </property>
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>127.0.0.1</value>
- </property>
- </configuration>
其中hbase.rootdir配置的是hdfs地址,ip:port要和hadoop/core-site.xml中的fs.defaultFS保持一致
其中hbase.zookeeper.quorum是zookeeper的地址,可以配多個,我們試驗用就先配一個
啟動hbase,執行:
- ./bin/start-hbase.sh
這時有可能會讓你輸入本地機器的密碼
啟動成功后可以看到幾個進程起來,包括zookeeper的HQuorumPeer和hbase的HMaster、HRegionServer
下面我們試驗一下hbase的使用,執行:
- hbase(main):001:0> status
- 1 active master, 0 backup masters, 1 servers, 0 dead, 3.0000 average load
創建一張表
- hbase(main):004:0> create 'table1','field1'
- 0 row(s) in 1.3430 seconds
- => Hbase::Table - table1
獲取一張表
- hbase(main):005:0> t1 = get_table('table1')
- 0 row(s) in 0.0010 seconds
- => Hbase::Table - table1
添加一行
- hbase(main):008:0> t1.put 'row1', 'field1:qualifier1', 'value1'
- 0 row(s) in 0.4160 seconds
讀取全部
- hbase(main):009:0> t1.scan
- ROW COLUMN+CELL
- row1 column=field1:qualifier1, timestamp=1470621285068, value=value1
- 1 row(s) in 0.1000 seconds
我們同時也看到hdfs中多出了hbase存儲的目錄:
- [root@MYAY hbase]# ./hadoop/bin/hadoop fs -ls /hbase
- Found 7 items
- drwxr-xr-x - root supergroup 0 2016-08-08 09:05 /hbase/.tmp
- drwxr-xr-x - root supergroup 0 2016-08-08 09:58 /hbase/MasterProcWALs
- drwxr-xr-x - root supergroup 0 2016-08-08 09:05 /hbase/WALs
- drwxr-xr-x - root supergroup 0 2016-08-08 09:05 /hbase/data
- -rw-r--r-- 3 root supergroup 42 2016-08-08 09:05 /hbase/hbase.id
- -rw-r--r-- 3 root supergroup 7 2016-08-08 09:05 /hbase/hbase.version
- drwxr-xr-x - root supergroup 0 2016-08-08 09:24 /hbase/oldWALs
這說明hbase是以hdfs為存儲介質的,因此它具有分布式存儲擁有的所有優點
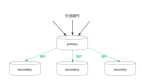
hbase的架構如下:
其中HMaster負責管理HRegionServer以實現負載均衡,負責管理和分配HRegion(數據分片),還負責管理命名空間和table元數據,以及權限控制
HRegionServer負責管理本地的HRegion、管理數據以及和hdfs交互。
Zookeeper負責集群的協調(如HMaster主從的failover)以及集群狀態信息的存儲
客戶端傳輸數據直接和HRegionServer通信
hive的部署
從 http://mirrors.hust.edu.cn/apache/hive 下載安裝包,我下的是http://mirrors.hust.edu.cn/apache/hive/stable-2/apache-hive-2.1.0-bin.tar.gz
解壓后,我們先準備hdfs,執行:
- [root@MYAY hadoop]# ./hadoop/bin/hadoop fs -mkdir /tmp
- [root@MYAY hadoop]# ./hadoop/bin/hadoop fs -mkdir /user
- [root@MYAY hadoop]# ./hadoop/bin/hadoop fs -mkdir /user/hive
- [root@MYAY hadoop]# ./hadoop/bin/hadoop fs -mkdir /user/hive/warehourse
- [root@MYAY hadoop]# ./hadoop/bin/hadoop fs -chmod g+w /tmp
- [root@MYAY hadoop]# ./hadoop/bin/hadoop fs -chmod g+w /user/hive/warehourse
使用hive必須提前設置好HADOOP_HOME環境變量,這樣它可以自動找到我們的hdfs作為存儲,不妨我們把各種HOME和各種PATH都配置好,如:
- HADOOP_HOME=/data/apache/hadoop
- export HADOOP_HOME
- HBASE_HOME=/data/apache/hbase
- export HBASE_HOME
- HIVE_HOME=/data/apache/hive
- export HIVE_HOME
- PATH=$PATH:$HOME/bin
- PATH=$PATH:$HBASE_HOME/bin
- PATH=$PATH:$HIVE_HOME/bin
- PATH=$PATH:$HADOOP_HOME/bin
- export PATH
拷貝創建hive-site.xml、hive-log4j2.properties、hive-exec-log4j2.properties,執行
- [root@MYAY hive]# cp conf/hive-default.xml.template conf/hive-site.xml
- [root@MYAY hive]# cp conf/hive-log4j2.properties.template conf/hive-log4j2.properties
- [root@MYAY hive]# cp conf/hive-exec-log4j2.properties.template conf/hive-exec-log4j2.properties
修改hive-site.xml,把其中的${system:java.io.tmpdir}都修改成/data/apache/tmp,你也可以自己設置成自己的tmp目錄,把${system:user.name}都換成用戶名
- :%s/${system:java.io.tmpdir}/\/data\/apache\/tmp/g
- :%s/${system:user.name}/myself/g
初始化元數據數據庫(默認保存在本地的derby數據庫,也可以配置成mysql),注意,不要先執行hive命令,否則這一步會出錯,具體見 http://stackoverflow.com/questions/35655306/hive-installation-issues-hive-metastore-database-is-not-initialized ,下面執行:
- [root@MYAY hive]# schematool -dbType derby -initSchema
成功之后我們可以以客戶端形式直接啟動hive,如:
- [root@MYAY hive]# hive
- hive> show databases;
- OK
- default
- Time taken: 1.886 seconds, Fetched: 1 row(s)
- hive>
試著創建個數據庫是否可以:
- hive> create database mydatabase;
- OK
- Time taken: 0.721 seconds
- hive> show databases;
- OK
- default
- mydatabase
- Time taken: 0.051 seconds, Fetched: 2 row(s)
- hive>
這樣我們還是單機的hive,不能在其他機器登陸,所以我們要以server形式啟動:
- nohup hiveserver2 &> hive.log &
默認會監聽10000端口,這時可以通過jdbc客戶端連接這個服務訪問hive
hive的具體使用在這里不贅述
spark部署
首先在 http://spark.apache.org/downloads.html 下載指定hadoop版本的安裝包,我下載的是http://d3kbcqa49mib13.cloudfront.net/spark-2.0.0-bin-hadoop2.7.tgz
spark有多種部署方式,首先支持單機直接跑,如執行樣例程序:
- ./bin/spark-submit examples/src/main/python/pi.py 10
它可以直接運行得出結果
下面我們說下spark集群部署方法:
解壓安裝包后直接執行:
- [root@MYAY spark-2.0.0-bin-hadoop2.7]# sbin/start-master.sh
這時可以打開 http://127.0.0.1:8080/ 看到web界面如下:
根據上面的url:spark://MYAY:7077,我們再啟動slave:
- [root@MYAY spark-2.0.0-bin-hadoop2.7]# ./sbin/start-slave.sh spark://MYAY:7077
刷新web界面如下:
出現了一個worker,我們可以根據需要啟動多個worker
下面我們把上面執行過的任務部署到spark集群上執行:
- ./bin/spark-submit --master spark://MYAY:7077 examples/src/main/python/pi.py 10
web界面如下:
spark程序也可以部署到yarn集群上執行,也就是我們部署hadoop時啟動的yarn
我們需要提前配置好HADOOP_CONF_DIR,如下:
- HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop/
- export HADOOP_CONF_DIR
下面我們把任務部署到yarn集群上去:
- ./bin/spark-submit --master yarn --deploy-mode cluster examples/src/main/python/pi.py 10
看 http://127.0.0.1:8088/cluster 效果如下:
總結一下
hdfs是所有hadoop生態的底層存儲架構,它主要完成了分布式存儲系統的邏輯,凡是需要存儲的都基于其上構建
yarn是負責集群資源管理的部分,這個資源包括計算資源和存儲資源,因此它也支撐了hdfs和各種計算模塊
map-reduce組件主要完成了map-reduce任務的調度邏輯,它依賴于hdfs作為輸入輸出及中間過程的存儲,因此在hdfs之上,它也依賴yarn為它分配資源,因此也在yarn之上
hbase基于hdfs存儲,通過獨立的服務管理起來,因此僅在hdfs之上
hive基于hdfs存儲,通過獨立的服務管理起來,因此僅在hdfs之上
spark基于hdfs存儲,即可以依賴yarn做資源分配計算資源也可以通過獨立的服務管理,因此在hdfs之上也在yarn之上,從結構上看它和mapreduce一層比較像
總之,每一個系統負責了自己擅長的一部分,同時相互依托,形成了整個hadoop生態。