京東資深架構師張成遠:京東分布式數據庫是如何煉成的?
原創作為國內***梯隊的電商企業,京東擁有億萬用戶,每天要應對數以千百萬計的訪問需求,在其架構和管理方面有何妙招來對數據加以支撐呢?在會上,51TO記者采訪了京東資深架構師張成遠。
張成遠,《Mariadb原理與實現》作者,開源項目speedy作者。目前就職于京東數據庫系統研發團隊,負責京東分布式數據庫系統架構與研發工作,主導了京東分布式數據庫系統在公司的落地及大規模推廣。擅長高性能服務器開發,擅長分布式數據庫/存儲/緩存等大規模分布式系統架構。
分布式數據庫的技術核心
京東每天面對海量的數據處理采用的是分布式數據庫的系統,其核心技術及思路又是怎樣的呢?
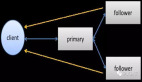
張成遠表示,京東分布式數據庫的關鍵是引入中間件的方式來提供對數據的拆分,解決了業務上單機扛不住數據量的問題。對于業務來說,在單機扛不住的情況下還要自己去關注數據,這樣它的負擔會非常重,所以京東采用了分布式數據庫的方案,讓業務可以比較方便的使用。京東會進入MySQL的協議,提供代理的方式,把整個集群管理好,業務接入時只需要用原生的MySQL客戶端來使用就可以,所以對于業務的使用負擔會非常的輕。同時京東也有非常完善的監控,所以能夠保證業務接入以后系統的穩定和可靠。
數據庫的設計架構
京東對容量非常的重視。在前期設計過程中,需要針對業務進行未來一到兩年甚至兩到三年的容量預估,來進行合理的資源配置。以及考慮到未來擴容的需求,京東可以實現在業務增長的情況下自動化擴容。
京東在發展過程中,早期的一些業務可能放在Oracle里面,也有一些數據量較小的業務是放在MySQL里面。簡單說,因為單機的數據量放不下,如果采用分布式數據庫我們能夠把它的數據進行拆分,相當于可以獲取到一個容量比原來大很多的數據庫。
分布式數據庫可以存放所有的關系型存儲數據,并且還可以支撐京東非常多的核心系統。例如訂單、商品、物流還有財務等等。
數據的可靠性
但是在這個過程中,數據的可靠性又是如何保障的呢?
張成遠表示數據的可靠性有兩點,一是服務本身是高可用的,二是數據本身是高可靠的。
比如說MySQL層面,我們通過主層,分布式數據庫中間件層面,因為我們本身是無狀態的,所以可以部署多份,來解決高可用的問題。關于數據本身高可靠的問題,我們會對數據庫里面的數據定期進行備份,所以哪怕有誤操作或者其他任何問題,都可以完整的恢復回來。
分布式事物的難點
在實現整個分布式數據庫的系統的過程中也不可避免面臨一些困難,比如分布式節點相關,京東團隊又是如何解決的呢?分布式事物相關最難的問題在于事物的原子性很難保證,一個訪問可能涉及多個節點,并且每個節點可能都有問題。尤其是基于MySQL層面做分布式數據庫,因為每個節點事物的ID不一樣,但如果基于存儲的不是MySQL而是其他層面,相對來說會有類似兩階段提交的協議可以參考,從而解決問題。
很多人會關心到分布式數據庫能否保證數據的一致性,張成遠認為這不是一致性的問題,而是關系到的分布式事物的原子性的問題。從本質上說如果事物涉及到多個節點,并且節點異常,為滿足業務的需求會引入相關系統,可以把丟失的東西補回來。還有一種方法,就是在使用上和業務溝通,將相關的事務進行拆解。拆分后,每次的訪問之落在一個分部或者節點上,如此一來可以保證每次的訪問要么成功要么失敗,可以很巧妙的從另一個方式繞過這個問題,用來保證原子性。
采訪***
國內不乏綜合型電商平臺,而京東卻是中國***的自營式電商企業,是中國***個成功赴美上市的大型綜合性電商平臺,同時與騰訊、百度等中國互聯網巨頭共同躋身全球前十大互聯網公司排行榜,京東的成功與其有著優秀的數據庫管理是密不可分的。