













關于現代CPU,程序員應當更新的知識
有人在Twitter上談到了自己對CPU的認識:
我記憶中的CPU模型還停留在上世紀80年代:一個能做算術、邏輯、移位和位操作,可以加載,并把信息存儲在記憶體中的盒子。我隱約意識到了各種新發展,例如矢量指令(SIMD),新CPU還擁有了虛擬化支持(雖然不知道這在實際使用中意味著什么)。
我錯過了哪些很酷的發展呢?有什么是今天的CPU可以做到而去年還做不到的呢?那兩年,五年或者十年之前的CPU又如何呢?我最感興趣的事是,哪些程序員需要自己動手才能充分利用的功能(或者不得不重新設計編程環境)。我想,這不該包括超線程/SMT,但我并不確定。我也對暫時CPU做不到但是未來可以做得到的事感興趣。
本文內容除非另有說明,都是指在x86和Linux環境下。歷史總在重演,很多x86上的新事物,對于超級計算機、大型機和工作站來說已經是老生常談了。
現狀
雜記
現代CPU擁有更寬的寄存器,可尋址更多內存。在上世紀80年代,你可能已經使用過8位CPU,但現在肯定已在使用64位CPU。除了能提供更多地址空間,64位模式(對于32位和64位操作通過x867浮點避免偽隨機地獲得80位精度)提供了更多寄存器和更一致的浮點結果。自80年代初已經被引入x86的其他非常有可能用到的功能還包括:分頁/虛擬內存,pipelining和浮點運算。
本文將避免討論那些寫驅動程序、BIOS代碼、做安全審查,才會用到的不尋常的底層功能,如APIC/x2APIC,SMM或NX位等。
內存/緩存 (Memory / Caches)
在所有話題中,最可能真正影日常編程工作的是內存訪問。我的***臺電腦是286在,那臺機器上,一次內存訪問可能只需要幾個時鐘周期。幾年前,我使用奔騰4,內存訪問需要花費超過400時鐘周期。處理器比內存的發展速度快得多,對于內存較慢問題的解決方法是增加緩存,如果訪問模式可被預測,常用數據訪問速度更快,還有預取——預加載數據到緩存。
幾個周期與400多個相比,聽起來很糟——慢了100倍。但一個對64位(8字節)值塊讀取并操作的循環,CPU聰明到能在我需要之前就預取正確的數據,在3Ghz處理器上,以約22GB/s的速度處理,我們只丟了8%的性能而不是100倍。
通過使用小于CPU緩存的可預測內存訪問模式和數據塊操作,在現代CPU緩存架構中能發揮***優勢。如果你想盡可能高效,這份文件是個很好的起點。消化了這100頁PDF文件后,接下來,你會想熟悉系統的微架構和內存子系統,以及學習使用類似likwid這樣的工具來分析和測驗應用程序。
TLBs
芯片里也有小緩存來處理各種事務,除非需要全力實現微優化,你并不需要知道解碼指令緩存和其他有趣的小緩存。***的例外是TLB——虛擬內存查找緩存(通過x86上4級頁表結構完成)。頁表在L1數據緩存,每個查詢有4次,或16個周期來進行一次完整的虛擬地址查詢。對于所有需要被用戶模式內存訪問的操作來說,這是不能接受的,從而有了小而快的虛擬地址查找的緩存。
因為***級TLB緩存必須要快,被嚴重地限制了尺寸。如果使用4K頁面,確定了在不發生TLB丟失的情況下能找到的內存數量。x86還支持2MB和1GB頁面;有些應用程序會通過使用較大頁面受益匪淺。如果你有一個長時間運行,且使用大量內存的應用程序,很值得研究這項技術的細節。
亂序執行/序列化 (Out of Order Execution / Serialization)
最近二十年,x86芯片已經能思考執行的次序(以避免因為一個停滯資源而被阻塞)。這有時會導致很奇怪的表現。x86非常嚴格的要求單一CPU,或者外部可見的狀態,像寄存器和記憶體,如果每件事都在按照順序執行都必須及時更新。
這些限制使得事情看起來像按順序執行,在大多數情況下,你可以忽略OoO(亂序)執行的存在,除非要竭力提高性能。主要的例外是,你不僅要確保事情在外部看起來像是按順序執行,實際上在內部也要真的按順序。
一個你可能關心的例子是,如果試圖用rdtsc測量一系列指令的執行時間,rdtsc將讀出隱藏的內部計數器并將結果置于edx和eax這些外部可見的寄存器。
假設我們這樣做:
- foo
- rdtsc
- bar
- mov %eax, [%ebx]
- baz
其中,foo,bar和baz不去碰eax,edx或[%ebx]。跟著rdtsc的mov會把eax值寫入內存某個位置,因為eax外部可見,CPU將保證rdtsc執行后mov才會執行,讓一切看起來按順序發生。
然而,因為rdtsc,foo或bar之間沒有明顯的依賴關系 ,rdtsc可能在foo之前,在foo和bar之間 ,或在bar之后。甚至只要baz不以任何方式影響移mov,令也可能存在baz在rdtsc之前執行的情況。有些情況下這么做沒問題,但如果rdtsc被用來衡量foo的執行時間就不妙了。
為了精確地安排rdtsc和其他指令的順序,我們需要串行化所有執行。如何準確的做到?請參考英特爾的這份文檔。
內存/并發 (Memory / Concurrency)
上面提到的排序限制意味著相同位置的加載和存儲彼此間不能被重新排序,除此以外,x86加載和存儲有一些其他限制。特別是,對于單一CPU,不管是否是在相同的位置,存儲不會與之前的負載一起被記錄。
然而,負載可以與更早的存儲一起被記錄。例如:
- mov 1, [%esp]
- mov [%ebx], %eax
執行起來就像:
- mov [%ebx], %eax
- mov 1, [%esp]
但反之則不然——如果你寫了后者,它永遠不能像你前面寫那樣被執行。
你可能通過插入串行化指令迫使前一個實例像寫起來一樣來執行。但是這需要CPU序列化所有指令這會非常緩慢,因為它迫使CPU要等到所有指令完成串行化后才能執行任何操作。如果你只關心加載/存儲順序,另外還有一個 mfence指令只用于序列化加載和存儲。
本文不打算討論memory fence,lfence和sfence,但你可以在這里閱讀更多關于它們的內容 。
單核加載和存儲大多是有序的,對于多核,上述限制同樣適用;如果core0在觀察core1,就可以看到所有的單核規則適用于core1的加載和存儲。然而如果core0和core1相互作用,不能保證它們的相互作用也是有序的。
例如,core0和core1通過設置為0的eax和edx開始,core0執行:
- mov 1, [_foo]
- mov [_foo], %eax
- mov [_bar], %edx
而core1執行
- mov 1, [_bar]
- mov [_bar], %eax
- mov [_foo], %edx
對于這兩個核來說, eax必須是1,因為***指令和第二指令相互依賴。然而,eax有可能在兩個核里都是0,因為core0的第三行可能在core1沒看到任何東西時執行,反之亦然。
memory barriers序列化一個核心內的存儲器訪問。Linus對于使用memory barriers而不是使用locking有這樣一段話 :
不用locking的真正代價最終不可避免。通過使用memory barriers自以為聰明的做事幾乎總是錯誤的前奏。在所有可以發生在十多種不同架構并且有著不同的內存排序的情況下,缺失一個小小的barrier真的很難讓你理清楚…事實上,任何時候任何人編了一個新的鎖定機制,他們總是會把它弄錯。
而事實證明,在現代的x86處理器上,使用locking來實現并發通常比使用memory barriers代價低,所以讓我們來看看鎖。
如果設置_foo為0,并有兩個線程執行incl (_foo)10000次——一個單指令同一位置遞增20000次,但理論上結果可能2。搞清楚這一點是個很好的練習。
我們可以用一段簡單的代碼試驗:
- #include <stdlib.h>
- #include <thread>
- #define NUM_ITERS 10000
- #define NUM_THREADS 2
- int counter = 0;
- int *p_counter = &counter;
- void asm_inc() {
- int *p_counter = &counter;
- for (int i = 0; i < NUM_ITERS; ++i) {
- __asm__("incl (%0) \n\t" : : "r" (p_counter));
- }
- }
- int main () {
- std::thread t[NUM_THREADS];
- for (int i = 0; i < NUM_THREADS; ++i) {
- t[i] = std::thread(asm_inc);
- }
- for (int i = 0; i < NUM_THREADS; ++i) {
- t[i].join();
- }
- printf("Counter value: %i\n", counter);
- return 0;
- }
用clang++ -std=c++11 –pthread在我的兩臺機器上編譯得到的分布結果如下:
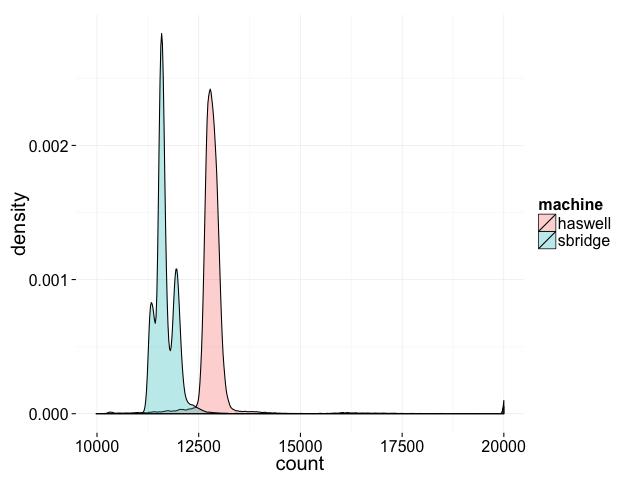
不僅得到的結果在運行時變化,結果的分布在不同的機器上也是不同。我們永遠沒到理論上最小的2,或就此而言,任何低于10000的結果,但有可能得到10000和20000之間的最終結果。
盡管incl是個單獨的指令,但不能保證原子性。在內部,incl是后面跟一個add后再跟一個存儲的負載。在cpu0里的一個增加有可能偷偷的溜進cpu1里面的負載和存儲之間執行,反之亦然。
英特爾對此的解決方案是少量的指令可以加lock前綴,以保證它們的原子性。如果我們把上面代碼的incl改成lock incl,輸出始終是20000。
為了使序列有原子性,我們可以使用xchg或cmpxchg, 它們始終被鎖定為比較和交換的基元。本文不會詳細描它是如何工作的,但如果你好奇可以看這篇David Dalrymple的文章。
為了使存儲器的交流原子性,lock相對于彼此在global是有序的,而且加載和存儲對于鎖不會被重新排序相。對于內存排序嚴格的模型,請參考x86 TSO文檔。
在C或C++中:
- local_cpu_lock = 1;
- // .. 做些重要的事 ..
- local_cpu_lock = 0;
編譯器不知道local_cpu_lock = 0不能被放在重要的中間部分。Compiler barriers與CPU memory barriers不同。由于x86內存模型是比較嚴格,一些編譯器的屏障在硬件層面是選擇不作為,并告訴編譯器不要重新排序。如果使用的語言比microcode,匯編,C或C++抽象層級高,編譯器很可能沒有任何類型的注釋。
#p#
內存/移植 (Memory / Porting)
如果要把代碼移植到其他架構,需要注意的是,x86也許有著今天你能遇到的任何架構里***的內存模式。如果不仔細思考,它移植到有較弱擔保的架構(PPC,ARM,或Alpha),幾乎肯定得到報錯。
- CPU1 CPU2
- ---- ----
- if (x == 1) z = y;
- y = 5; mb();
- x = 1;
…如果我讀了Alpha架構內存排序保證正確,那么至少在理論上,你真的可以得到Z = 5
mb是memory barrier(內存屏障)。本文不會細講,但如果你想知道為什么有人會建立這樣一個允許這種瘋狂行為發生的規范,想一想成產成本上升打垮DEC之前,其芯片快到可以在相同的基準下通過仿真運行卻比x86更快。對于為什么大多數RISC-Y架構做出了當時的決定請參見關于Alpha架構背后動機的論文。
順便說一句,這是我很懷疑Mill架構的主要原因。暫且不論關于是否能達到他們號稱的性能,僅僅在技術上出色并不是一個合理的商業模式。
內存/非臨時存儲/寫結合存儲器 (Memory / Non-Temporal Stores / Write-Combine Memory)
上節所述的限制適用于可緩存(即“回寫(write-back)”或WB)存儲器。在此之前,只有不可緩存(UC)內存。
一個關于UC內存有趣的事情是,所有加載和存儲都被設計希望能在總線上加載或存儲。對于沒有緩存或者幾乎沒有板載緩存的處理器,這么做完全合理。
內存/NUMA
非一致內存訪問(NUMA),即對于不同處理器來說,內存訪問延遲和帶寬各有不同。因為NUMA或ccNUMA如此普遍,以至于是被默認為采用的。
這里要求的是共享內存的線程應該在同一個socket上,內存映射I/O重線程應該確保它與最接近的I/O設備的socket對話。
曾幾何時,只有內存。然后CPU相對于內存速度太快以致于人們想增加一個緩存。緩存與后備存儲器(內存)不一致是一個壞消息,因此緩存必須保持它堅持著什么的信息,所以它才知道是否以及何時它需要向后備存儲寫東西。
這不算太糟糕,而一旦你獲得了兩個有自己緩存的核心,情況就變復雜了。為了保持作為無緩存的情況下相同的編程模型,緩存必須相互之間以及與后備存儲器是一致的。由于現有的加載/存儲指令在其API中沒有什么允許他們說“對不起!這個加載因為別的cpu在使用你想用的地址而失敗了” ,最簡單的方式是讓每個CPU每次要加載或存儲東西的時候發一個信息到總線上。我們已經有了這個兩個CPU都可以連接的內存總線,所以只要要求另一個CPU在其數據緩存有修改時做出回復(并失去相應的緩存行)。
在大多數情況下,每個CPU只涉及其他CPU不關心的數據,所以有一些浪費的總線流量。但不算糟糕,因為一旦CPU拿出一條消息說“你好!我要占有這個地址并修改數據”,可以假定在其他的CPU要求前完全擁有該地址,雖然不是總會發生。
對于4核CPU,依然可以工作,雖然字節浪費相比有點多。但其中每個CPU對其他每一個CPU的響應失敗比例遠遠超出4個CPU總和,既因為總線被飽和,也因為緩存將得到飽和(緩存的物理尺寸/成本是以同時的讀和寫數量 O(n^2) ,并且速度與大小負相關)。
這個問題“簡單”的解決方法是有一個單獨的集中目錄記錄所有的信息,而不是做N路的對等廣播。反正因為現在我們正在一個芯片上包2-16個內核,每個芯片(socket)對每個核的緩存狀態有個單一目錄跟蹤是很自然的事。
不僅解決了每個芯片的問題,而且需要通過某種方式讓芯片相互交談。不幸的是,當我們擴展這些系統即使對于小型系統總線速度也快到真的很難驅動一個信號遠到連接一堆芯片和都在一條總線上的記憶體。最簡單的解決辦法就是讓每個插座都擁有一個存儲器區域,所以每一個socket并不需要被連接到的存儲器每一個部分。因為它很明確哪個目錄擁有特定的一段內存,這也避免了目錄需要一個更高級別的目錄的復雜性。
這樣做的缺點是,如果占用一個socket并且想要一些被別的socket擁有的memory,會有顯著的性能損失。為簡單起見,大多數“小”(<128核)系統使用環形總線,因此性能損失的不僅僅是通過一系列跳轉達到memory付出的直接延遲/帶寬處罰,他也用光了有限的資源(環狀總線)和減慢了其他socekt的訪問速度。
理論上來講,OS會透明處理,但往往低效 。
Context Switches/系統調用(Syscalls)
在這里,syscall是指Linux的系統調用,而不是x86的SYSCALL或者SYSENTER指令。
所有現代處理器具有一個副作用是,Context Switches代價昂貴,這會導致系統調用代價高昂。Livio Soares和Michael Stumm的論文對此做了詳細討論。我在下文將用一些他們的數據。下圖為Xalan上的酷睿i7每一個時鐘可以多少指令(IPC):
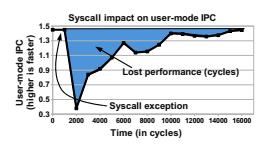
系統調用的14000周期后,代碼仍不是全速運行。
下面是幾個不同的系統調用的足跡表,無論是直接成本(指令和周期),還是間接成本(緩存和TLB驅逐的數量)。
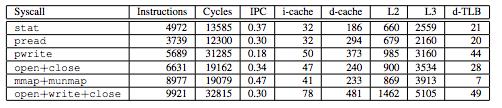
有些系統調用引起了40多次的TLB回收!對于具有64項D-TLB的芯片,幾乎掃蕩光了TLB。緩存回收不是毫無代價。
系統調用的高成本是人們對于高性能的代碼轉而進行使用腳本化的系統調用(例如epoll, 或者recvmmsg)究其原因,人們需要高性能I/O經常使用用戶空間的I/O stack。Context Switches的成本就是為什么高性能的代碼往往是一個核心一個線程(甚至是固定線程上一個單線程),而不是每個邏輯任務一個線程的原因。
這種高代價也是VDSO在后面驅動,把一些簡單的不需要任何升級特權的系統調用放進簡單的用戶空間庫調用。
SIMD
基本上所有現代的x86 CPU都支持SSE,128位寬的向量寄存器和指令。因為要完成多次相同的操作很常見,英特爾增加了指令,可以讓你像為2個64位塊一樣對128位數據塊操作,或者4個32位的塊,8個16位塊等。ARM用不同的名字(NEON)支持同樣的事情,而且支持的指令也很相似。
通過使用SIMD指令獲得了2倍,4倍加速這是很常見的,如果你已經有了一個計算繁重的工作這絕對值得期待。
編譯器足夠到可以分辨常見的可以實現矢量化模式的簡單的代碼,就像下面代碼,會自動使用現代編譯器的向量指令:
- for (int i = 0; i < n; ++i) {
- sum += a[i];
- }
但是,如果你不手寫匯編語言,編譯器經常會產生非優化的代碼 ,特別是對SIMD代碼,所以如果你很關心盡可能的得到***性能,你就要看看反匯編并檢查你編譯器的優化錯誤。
電源管理
有現代CPU都有很多花哨的電源管理功能用來在不同的場景優化電源使用。這些的結果是“跑去閑置”,因為盡可能快的完成工作,然后讓CPU回去睡覺是最節能的方式。
盡管有很多做法已經被證明進行特定的微優化可以對電源消耗有利,但把這些微優化應用在實際的工作負載中通常會比預期的收益小 。
GPU/GPGPU
相比其他部分我不是很夠資格來談論這些。幸運的是,Cliff Burdick自告奮勇地寫了下面這節:
2005年之前,圖形處理單元(GPU)被限制在一個只允許非常有限硬件控制量的API。由于庫變得更加靈活,程序員開始使用處理器處理更常用的任務,如線性代數例程。GPU的并行架構可以通過發射數百并發線程在大量的矩陣塊中工作。然而,代碼必須使用傳統的圖形API,并仍被限制于可以控制多少硬件。Nvidia和ATI注意到了這點并發布了可以使顯卡界外的人更熟悉的API來獲得更多的硬件訪問的框架。該庫得到了普及,今天的GPU同CPU一起被廣泛用于高性能計算(HPC)。
相比于處理器,GPU硬件主要有幾個差別,概述如下:
處理器
在頂層,一個GPU處理器包含一個或多個數據流多重處理器(SMs)。現代GPU的每個流的多重理器通常包含超過100個浮點單元,或在GPU的世界通常被稱為核。每個核心通常主頻在800MHz左右,雖然像CPU一樣,具有更高的時鐘頻率但較少內核的處理器也存在。GPU的處理器缺乏自己同行CPU的許多特色,包括更大的緩存和分支預測。在核的不同層,SMs,和整體處理器之間,通訊變得越來越慢。出于這個原因,在GPU上表現良好的問題通常是高度平行的,但有一些數據能夠在小數目的線程間共用。我們將在下面的內存部分解釋為什么。
內存(Memory)
現代GPU內存被分為3類:全局內存,共享內存和寄存器。全局存儲器是GDDR通常GPU盒子上廣告宣稱約為2-12GB大小,并具有通過300-400GB /秒的速度。全局存儲器在處理器上的所有SMS所有線程都能被訪問,并且也是內存卡上最慢的類型。共享內存,正如其名所指,是同一個SM中的所有線程之間共享內存。它通常至少是全局儲蓄器兩倍的速度,但對不同SM的線程之間是不被允許進行訪問的。寄存器很像在CPU上的寄存器,他們是GPU上訪問數據最快的方式,但它們只在每個本地線程,數據對于其他正在運行的不同線程是不可見的。共享內存和全局內存對他們如何能夠被訪問都有很嚴格的規定,對不遵守這些規則的行為有嚴重性能下降的處罰。為了達到上述吞吐量,內存訪問必須在同線程組間線程之間完整的合并。類似于CPU讀入一個單一的緩存行,如果對齊合適的話,GPU對于單一的訪問可以有緩存行可以服務一個組里的所有線程。然而,最壞的狀況是一組里所有線程訪問不同的緩存行,每個線程都要求一個獨立的記憶體讀。這通常意味著緩存行中的數據不被線程使用,并且存儲器的可用吞吐量下降。類似的規則同樣適用于共享內存,有一些例外,我們將不在這里涵蓋。
線程模型 (Threading Model)
GPU線程在一個單指令多線程(SIMT)方式下運行,并且每個線程以組的形式在硬件中以預定義大小(通常32)運行。這***一部分有很多的影響;該組中的每個線程必須同一時間在同一指令下工作。如果任何一組中的線程的需要從他人那里獲得代碼的發散路徑(例如一個if語句)的代碼,所有不參與該分支的線程會到該分支結束才能開始。作為一個簡單的例子:
- if (threadId < 5) {
- // Do something
- }
- // Do More
在上面的代碼中,這個分支會導致我們的32個線程中的27組暫停執行,直到分支結束。你可以想象,如果多組線程運行這段代碼,整體性能會因大部分的內核處于閑置狀態將受到很大打擊。只有當線程整組被鎖定才能使硬件允許交換另外一組的核來運行。
接口(Interfaces)
現代GPU必須有一個CPU同CPU和GPU內存之間進行數據復制的發送和接收,并啟動GPU并且編碼。在***吞吐量的情況下,一個有著16個通道的PCIe 3.0總線可達到約13-14GB / s的速度。這可能聽起來很高,但相對于存在GPU本身的內存速度,他們慢了一個數量級。事實上,圖形處理器變得更強大以致于PCIe總線日益成為一個瓶頸。為了看到任何GPU超過CPU的性能優勢,GPU的必須裝有大量的工作,以使GPU需要運行的工作的時間遠遠的高于數據發送與接收的時間。
較新的GPU具備一些功能可以動態的在GPU代碼里分配工作而不需要再回到CPU推出的GPU代碼中動態的工作,而無需返回到CPU,單目前他的應用相當有局限性。
GPU結論
由于CPU和GPU之間主要的架構差異,很難想象任何一個完全取代另一個。事實上,GPU很好的補充了CPU的并行工作,使CPU可以在GPU運行時獨立完成其他任務。AMD公司正在試圖通過他們的“非均相體系結構”(HSA)合并這兩種技術,但用現有的CPU代碼,并決定如何將處理器的CPU和GPU部分分割開來將是一個很大的挑戰,不僅僅對于處理器來說,對于編譯器也是。
虛擬化
除非你正在編寫非常低級的代碼直接處理虛擬化,英特爾植入的虛擬化指令通常不是你需要思考的問題。
同那些東西打交道相當混亂,可以從這里的代碼看到。即使對于那里展示的非常簡單的例子,設置起用Intel的VT指令來啟動一個虛擬客戶端也需要大約1000行低階代碼。
虛擬內存
如果你看一下Vish的VT代碼,你會發現有一塊很好的代碼專門用于頁表/虛擬內存。這是另一個除非你正在編寫操作系統或其他低級別的系統代碼你不必擔心的“新”功能。使用虛擬內存比使用分段存儲器更簡單,但本文暫且討論到這里。
SMT/超線程 (Hyper-threading)
超線程對于程序員來說大部分是透明的。一個典型的在單核上啟用SMT的增速是25%左右。對于整體吞吐量來說是好的,但它意味著每個線程可能只能獲得其原有性能的60%。對于您非常關心單線程性能的應用程序,你可能***禁用SMT。雖然這在很大程度上取決于工作量,而且對于任何其他的變化,你應該在你的具體工作負載運行一些基準測試,看看有什么效果***。
所有這些復雜性添加到芯片(和軟件)的一個副作用是性能比曾經預期的要少了很多;對特定硬件基準測試的重要性相對應的有所回升。
人們常常用“計算機語言基準游戲”作為證據來說一種語言比另一種速度更快。我試著自己重現的結果,用我的移動Haswell(相對于在結果中使用的服務器Kentsfield),我得到的結果可以達到高達2倍的不同(相對速度)。即使在同一臺機器上運行同一個基準,Nanthan Kurz 最近向我指出一個例子 gcc -O3 比 gcc –O2 慢25%改變對C ++程序的鏈接順序可導致15%的性能變化 。評測基準的選定是個難題。
分行 (Branches)
傳統觀念認為使用分支是昂貴的,并且應該盡一切(大多數)的可能避免。在Haswell上,分支的錯誤預測代價是14個時鐘周期。分支錯誤預測率取決于工作量。在一些不同的東西上使用 perf stat (bzip2,top,mysqld,regenerating my blog),我得到了在0.5%和4%之間的分支錯誤預測率。如果我們假設一個正確的預測的分支費用是1個周期,這個平均成本在.995 * 1 + .005 * 14 = 1.065 cycles to .96 * 1 + .04 * 14 = 1.52 cycles之間。這不是很糟糕。
從約1995年來這實際上夸大了代價,由于英特爾加入條件移動指令,使您可以在無需一個分支的情況下有條件地移動數據。該指令曾被Linus批判的令人難忘的 ,這給了它一個不好的名聲,但是相比分支,使用cmos更有顯著的加速這是相當普遍的額外分支成本的一個現實中的例子是使用整數溢出檢查。當使用bzip2來壓縮一個特定的文件,那會增加約30%的指令數量(所有的增量從額外分支指令得來),這導致1%的性能損失 。
不可預知的分支是不好的,但大部分的分支是可以預見的。忽略分支的費用直到你的分析器告訴你有一個熱點在如今是非常合理的。CPUs在過去十年中執行優化不好代碼方面變好了很多,而且編譯器在優化代碼方面也變得更好,這使得優化分支變成了不良的使用時間,除非你試圖在一些代碼中擠出絕對***表現。
如果事實證明這就是你所需要做的,你***還是使用檔案導引優化而不是試圖手動去搞這個東西。
如果你真的必須用手動做到這一點,有些編譯器指令你可以用來表示一個特定分支是否有可能被占用與否。現代CPU忽略了分支提示說明,但它們可以幫助編譯器更好得布局代碼。
對齊 (Alignment)
經驗告訴我們應該拉長struct,并確數據對齊。但在Haswell的芯片上,幾乎任何你能想到的任何不跨頁的單線程事情的誤配準為零。有些情況下它是有用的,但在一般情況下,這是另一種無關緊要的優化因為CPU已經變得在執行不優良代碼時好了很多。它無好處的增加了內存占用的足跡也是有一點害處。
而且, 不要把事情頁面對齊或以其他方式排列到大的界限,否則會破壞緩存性能 。
自修改代碼 (Self-modifying code)
這是另外一個目前已經不怎么有意義的優化了。使用自修改代碼以減少代碼量或增加性能曾經有意義,但由于現代的緩存傾向于拆分他們的L1指令和數據緩存,在一個芯片的L1緩存之間修改運行的代碼需要昂貴的通信。
未來
下面是一些可能的變化,從最保守的推測到***膽的推測。
事務內存和硬件鎖Elision (Transactional Memory and Hardware Lock Elision)
IBM已經在他們自己的POWER芯片中有這些功能。英特爾嘗試著把這些東西加到Haswell,但因為一個報錯被禁用了。
事務內存支持正如它聽起來這樣:事務的硬件支持。通過三個新的指令xbegin、xend和xabort。
xbegin開始一個新的事務。一個沖突(或xabort)使處理器(包括內存)的架構狀態回滾到在xbegin的狀態之前.如果您使用的是通過庫或語言支持的事務內存,這對你來說應該透明的。如果你正在植入庫支持,你就必須弄清楚如何將有有限的硬件緩沖區大小限制的硬件支持轉換成抽象的事務。
本文打算討論Elision硬件鎖,在本質上,它被植入的機制與用于實現事務內存的機制非常相似,而且它是被設計來加快基于鎖的代碼。如果你想利用HLE,看看這個文檔 。
快速I/O(Fast I/O)
對于存儲和網絡來說,I/O帶寬正在不斷上升,I/O延遲正在下降。問題是,I/O通常是通過系統調用完成。正如我們所看到的,系統調用的相對額外費用一直在往上走。對于存儲和網絡,答案是轉移到用戶模式的I/O堆棧。
黑硅(Dark Silicon)/系統級芯片
晶體管規模化一個有趣的副作用是我們可以把很多晶體管包進一個芯片上,但它們產生如此多的熱量,如果你不希芯片融化,普通晶體管大多數時間不能開關。
這樣做的結果把包括大量時間不使用的專用硬件變得更有意義。一方面,這意味著我們得到各種專用指令,如PCMP和ADX。但這也意味著,我們正把整個曾經不集成在芯片上的設備與芯片集成。包括諸如GPU和(用于移動設備)無線電。
與硬件加速的趨勢相結合,這也意味著企業設計自己的芯片,或者至少自己芯片的部分變得更有意義。通過收購PA Semi公司,蘋果公司已經走出了很遠。首先,加入少量定制的加速器給停滯不前的標準的ARM架構,然后添加自定義加速器給他們自己定制的架構。由于正確的定制硬件和基準和系統設計深思熟慮的結合,iPhone 4比我的旗艦級Android手機反應還稍快,這個旗艦機比iPhone 4新了很多年,并且具有更快的處理器以及更大的內存。
亞馬遜挑選了原Calxeda的團隊的一部分,并雇用了一個足夠大小的硬件設計團隊。Facebook也已經挑選了ARM SoC的專家,并與高通公司在某些事情展開合作。Linus也有紀錄在案的發言,“我們將在各個方面看到更多的專用硬件” 等等。
結論
x86芯片已經擁有了很多新的功能和非常有用的小特性。在大多數情況下,要利用這些優勢你不需要知道它們具體是什么。真正的底層通常由庫或驅動程序隱藏了起來,編譯器將嘗試照顧其余部分。例外是,如果你真的要寫底層代碼,這種情況下世界上已經變得更加混亂,或者如果你想在你的代碼里獲得絕對的***表現,就會更加怪異。
有些事似乎必然在未來發生。但過往的經驗卻又告訴我們,大多數的預測是錯誤的,所以誰又知道呢?















