淺談大數據之Hadoop部署前的思考
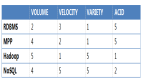
Hadoop的應用前提是”數據是有價值的!”,當然,這一點已經得到了幾乎所有人的認可,并且在實際環境中,也都是這樣在做的,我們都希望從系統日志,網絡數據,社交信息等海量數據中發掘出有價值的信息,比如,用戶的行為,習慣等,而這些是做下一步市場營銷的有效決策依據。在Hadoop出現后,對于數據的發掘更是體現的***,尤其是從知名的互聯網公司開始,都已經在使用或部署Hadoop環境。

面對如此誘惑,很多傳統的企業用戶都想參考互聯網企業的做法,非常快速的部署Hadoop,從而快速整合和發掘既有數據的價值。但現實情況卻正應了”理想很豐滿,現實太骨感“那句網絡流行語,想快速部署Hadoop,卻沒那么容易。為什么會出現這樣的問題呢,我想到的原因大概有幾點:
1. Hadoop提供給我們的只是一個框架,而不是一套完整的解決方案。
就像購買一套房子,建筑商交付的永遠那都是一個基礎結構,整體裝修部分還是要靠戶主自己按照自己的風格和喜好進行設計和實施,而且,每個戶主對于裝修部分都會有自己的定義。Hadoop的部署恰是如此,每個企業中的Hadoop環境都可以說是唯一的,需要企業用戶對自己的數據環境有一個非常好的梳理和認知。我需要分析哪些數據?需要得到什么樣的信息?這些信息我用來做什么?只有想明白這些問題后,Hadoop部署才會體現出它的價值。而這些,不僅僅是技術層面的問題,還要有管理層的認知甚至是業務層面的配合。
2. 人力上的問題。
Hadoop屬于開源架構,而開源有它先天不足或無法解決的問題,例如,由于場景的的唯一性導致的開源架構下的開發和維護問題。Hadoop同樣會面對這樣的問題,而且,市場上當前Hadoop方面的人才相對比較少,這些對于企業而言,都會增加不少部署和應用上的難度。大量的開發工作需要大量的開發人員,個體的稀缺性又加重了開發方面的成本和難度。
3. 只有適合分布式架構解決的問題才可以由Hadoop解決。
Hadoop不是”仙丹”,不能解決一切數據分析問題。面向結構化的數據查詢和分析,傳統數據庫結構還有它特有的優勢。Hadoop是一個分布式架構,而分布式架構決定了其”只有適合分布式架構解決的問題才可以由Hadoop解決”。例如,一個孕婦,需要10月懷胎才會有一個baby,而不是通過10個孕婦在1個月內擁有一個baby。說到底,只有問題可以被拆分成若干子問題,且子問題是獨立的,也就是可以適用用“key-value”的迭代方式進行處理,最終可以推導出我們需要的結果。這樣的問題才是Haodop可以去解決的問題。
4. Hadoop不適合處理小文件。
其實大和小只是一個相對的概念,不存在絕對值的對比,之所以說Hadoop不適合處理小文件是由HDFS中的namenode局限性決定的,每個文件都會在namenode中保存相應的元數據信息,為了提升效率,這些信息在使用的過程中都是被保存在內存中的,如果小文件很多,則會消耗大量的namenode節點的內存,而對于單節點來講,內存的擴展是有其上限的。反之,如果是相對較大,例如上GB或更大的文件,相對消耗的內存則會比較少。同時,在數據處理的過程中,系統開銷的占比會小很多。這些架構上的特點和限制,決定了Hadoop更適合于處理“大”數據。當然在技術實現上來看,殺雞用牛刀也是可以的,就看值不值得而已。
原文鏈接:http://www.36dsj.com/archives/10382