Travis CI:最小的分布式系統(tǒng)(下)
大約1年之前,我們發(fā)現(xiàn)當(dāng)時的架構(gòu)有些不合理了。尤其是Hub,它上面承擔(dān)了太多的任務(wù)。Hub要接收新的處理請求,處理并推動構(gòu)建日志,它要同步用戶信息到Github,它要通知用戶構(gòu)建是否成功。它跟一大群外部API打交道,全部都是在一個進(jìn)程中處理。
Hub需要繼續(xù)演化,但它卻不太可能自由擴(kuò)展。Hub只能以單進(jìn)程的方式運(yùn)行,也因此成為我們最有可能發(fā)生的單點(diǎn)錯誤。
Github API是一個有趣的例子。我們是Github API的重度用戶,依靠這些API我們的構(gòu)建任務(wù)才能執(zhí)行。無論是獲取構(gòu)建配置信息,更新構(gòu)建狀態(tài),還是同步用戶數(shù)據(jù),都離不開這些API。
回顧歷史,當(dāng)這些API中的某一個不可用,hub就會停止當(dāng)天正在處理的任務(wù),而轉(zhuǎn)移到下一個任務(wù)上。所以,當(dāng)Github API不可用時,我們的很多構(gòu)建都會失敗。
我們對這些API賦予了很多信任,當(dāng)然現(xiàn)在也一樣,但是說到底,這些是我們不能掌控的資源。這些資源不是我們自己來維護(hù),而是由另外的一個團(tuán)隊,在另外的網(wǎng)絡(luò)系統(tǒng)中,有他們自身的弱點(diǎn)。
我們過去沒有這樣想。過去我們總是把這些資源當(dāng)做我們可以信賴的朋友,以為他們隨時都會響應(yīng)我們的請求。
我們錯了。
一年之前,這些API無聲無息的對某個功能做了修改。這個一個雖然沒有文檔說明,但是我們非常依賴的功能。這個功能就是這么消無聲息的被修改了,于是導(dǎo)致了我們這邊的問題。
結(jié)果,我們的系統(tǒng)完全亂套了。原因很簡單,我們把Github API當(dāng)做了自己的朋友,我們耐心的等待這些API回應(yīng)我們的請求。每一次新的提交,我們都等了很長的時間,每次都有幾分鐘。
我們的超時設(shè)置太寬松了。因為這個原因,當(dāng)對Github API的請求最終超時時,我們的系統(tǒng)也已經(jīng)發(fā)生錯誤。那天晚上我們花了很長的時間處理這個問題。
即便是小問題,當(dāng)某個時刻湊到一塊了,也能夠破壞一個系統(tǒng)。
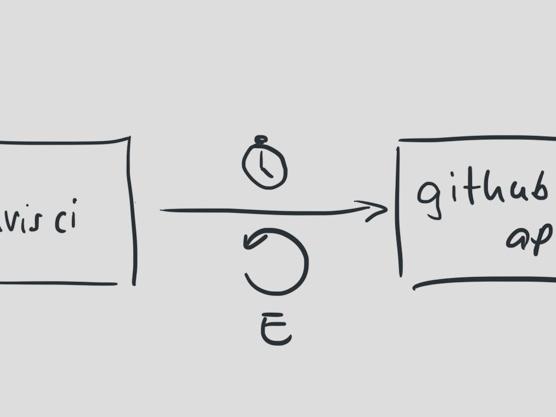
我們開始隔離這些API請求,設(shè)置更短的超時時間。為了保證我們不會因為Github方面的中斷而導(dǎo)致構(gòu)建失敗,我們同樣加了重試機(jī)制。為了保證我們能夠更好的處理外部的異常,我們的每一次重試都會依次延長過期時間。
你應(yīng)該接受那些在你控制之外的外部API隨時可能失敗的現(xiàn)實。如果你不能將這些失敗完全隔離,你就有必要考慮如果去處理他們。
如何去處理每一個單點(diǎn)錯誤場景是基于商業(yè)上的考慮。我們可以承受一個構(gòu)建出異常嗎?當(dāng)然,這不是世界末日。如果因為外部系統(tǒng)的問題,我們能夠讓數(shù)百個構(gòu)建出現(xiàn)異常嘛?我們不能,因為無論什么原因,這些構(gòu)建異常夠影響到了我們的客戶。
Travis CI最初是一個好心的家伙。它總是很樂觀地認(rèn)為每一件事情總會正確的工作。
很不幸,那不是事實。每一件事在任何時刻都可能導(dǎo)致混亂,但是我們的代碼卻從來沒考慮過這一點(diǎn)。我們做過很多努力,現(xiàn)在我們?nèi)匀辉谂Γジ淖冞@種情況,去提高我們的代碼處理外部API或者系統(tǒng)內(nèi)部異常的能力。

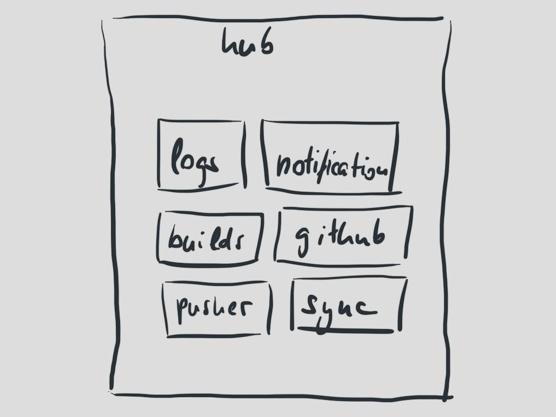
回到我們的系統(tǒng),hub承擔(dān)的任務(wù)很容易導(dǎo)致異常,所以我們將其分割成很多的小應(yīng)用。每個小應(yīng)用都有其自身的目的和承擔(dān)的任務(wù)。
做好任務(wù)隔離,這樣我們就能更輕松的擴(kuò)展系統(tǒng)。大部分任務(wù)都是直接的從上到下運(yùn)行的。
現(xiàn)在我們有了三個進(jìn)程;處理新的提交,處理構(gòu)建通知,和處理構(gòu)建日志。
突然之間,我們有了新的問題。
#p#
雖然我們的應(yīng)用已經(jīng)分割開了,但是他們都依賴一個叫做travis-core的核心。核心包括數(shù)量很多的Travis CI所有部分的商業(yè)邏輯。這可真是一個big ball of mud。

對核心的依賴意味著核心代碼的改動可能影響到所有應(yīng)用。我們的應(yīng)用是按照各自的任務(wù)進(jìn)行劃分,但是我們的代碼不是。
我們現(xiàn)在還在為最早的架構(gòu)設(shè)計而支付學(xué)費(fèi)。如果你增加功能,或是修改代碼,對公用部分的一點(diǎn)點(diǎn)改變都可能帶來問題。
為了保證所有應(yīng)用的代碼都可以正常工作,當(dāng)travis-core做了修改,我們需要部署所有應(yīng)用去驗證。
任務(wù)并不僅僅意味著你必須從代碼的角度將其分隔。任務(wù)本身也同樣需要物理分隔。
復(fù)雜的依賴影響了部署,同樣,它也影響了你交付新代碼、新功能的能力。
我們慢慢的將代碼的依賴變小,真正的從代碼隔離開每個應(yīng)用間的任務(wù)。幸運(yùn)的是,代碼本身已經(jīng)有很好的隔離程度了,所以這個過程顯得容易多了。
有一個應(yīng)用需要特別關(guān)注,因為它是我們做擴(kuò)展最大的挑戰(zhàn)。
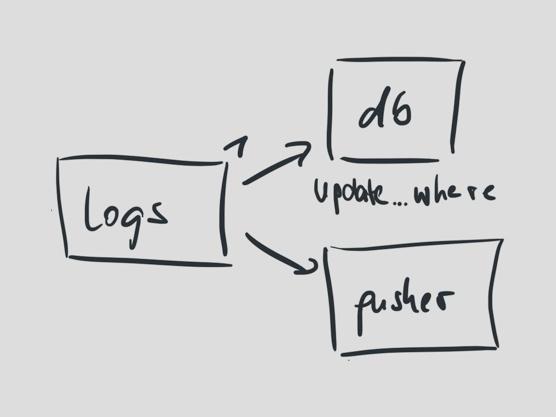
日志的作用有兩個:當(dāng)構(gòu)建日志的數(shù)據(jù)塊通過消息隊列進(jìn)來時,更新數(shù)據(jù)庫對應(yīng)行,然后推送它到Pusher用于實時的用戶界面更新。
日志塊以流的形式在同一個時間從不同的進(jìn)程中進(jìn)來,然后被一個進(jìn)程處理。這個進(jìn)程每秒最高可處理100個消息。
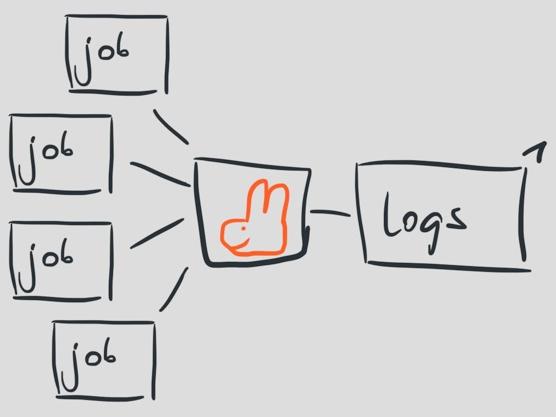
一般情況下這樣處理日志流的方式也相當(dāng)OK,但是這也意味著我們很難處理某些時刻突然增長的日志消息,因此這個唯一的進(jìn)程對于我們系統(tǒng)的擴(kuò)展會成為一個很大的障礙。
問題在于,進(jìn)程是按照這些消息到達(dá)消息隊列的先后順序來進(jìn)行處理的,而Travis CI中的所有事情都依賴于這些消息。
更新數(shù)據(jù)庫里的一條日志流意味更新包含所有日志的一行數(shù)據(jù)。更新用戶界面的日志當(dāng)然意味著在DOM樹上附加一個新的結(jié)點(diǎn)。
為了解決這個棘手的問題,我們需要改很多代碼。
但是首先,我們需要理清楚什么才是一個更好的解決方案,好的解決方案應(yīng)該是能夠讓我們很方便的擴(kuò)展日志處理的部分。
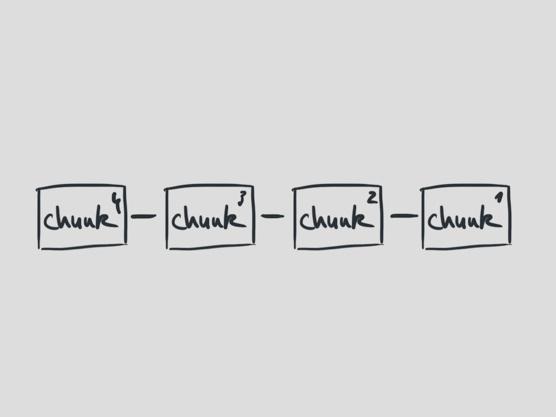
我們決定讓處理的順序作為消息本身的一個屬性,而不是隱含的依賴于它們被放進(jìn)消息隊列的順序。
這個想法是受到Leslie Lamport于1978年發(fā)表的一篇論文《Time, Clocks, and the Ordering of Events in a Distributed System》的啟發(fā)。
在這篇論文中,Lamport描述了在分布式系統(tǒng)中,使用遞增計數(shù)器來保留事件發(fā)生的順序的方法。當(dāng)一個消息被發(fā)送,發(fā)送者會在消息被接收者接收到之前增加計數(shù)器的值。
我們可以簡化那個想法,因為在我們的場景中一個日志塊只能來自一個發(fā)送者。進(jìn)程只要不斷增加計數(shù)器的值,就可以讓之后的日志收集工作變得簡單。
剩下的工作就是根據(jù)計數(shù)器的值來對日志塊進(jìn)行排列了。
困難之處在于,這樣設(shè)計之后等同于允許向數(shù)據(jù)庫寫入小的日志塊,這些小日志塊只有在對應(yīng)任務(wù)結(jié)束后才會寫入到完整的日志中。
但是這會直接影響到用戶界面。我們不得不面對消息以無序的方式到來。這個變化的確影響的范圍大了些,但它反過來簡化了很多部分的代碼。
從表面看,這個改動似乎無關(guān)緊要。但是依賴于你本不需要依賴的順序會帶來更多潛在的復(fù)雜性。
我們現(xiàn)在不用依賴于信息是如何傳送的,因為現(xiàn)在我們可以在任何時間得到他們的順序。
我們修改了不少代碼,因為那些代碼做了一個假設(shè),任何信息都是順序過來的,而這個假設(shè)是完全錯誤的。在分布式系統(tǒng)中,事件可以以任何順序在任何時間到達(dá)。我們只需要確保之后我們可以將這些片段重新組裝回去。
你可以從我們的博客獲取這個問題更詳細(xì)的說明。
到了2013年,我們每天已經(jīng)在運(yùn)行45000次構(gòu)建。我們還是在為早先的設(shè)計付出著代價,但是我們也在慢慢的改進(jìn)設(shè)計。
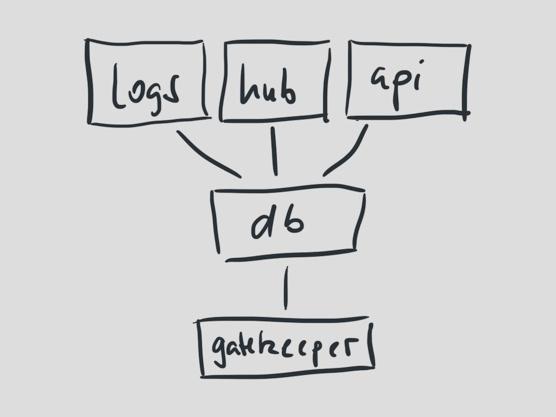
我們現(xiàn)在還有一個麻煩。系統(tǒng)所有的組件還是在共享同一個數(shù)據(jù)庫。如果數(shù)據(jù)庫出現(xiàn)問題,自然的所有組件都會出現(xiàn)問題。這個故障上周我們剛剛遇見一次。
這同樣意味著日志寫入的數(shù)量(目前可以達(dá)到每秒300次)影響到了我們API的性能,當(dāng)用戶瀏覽我們的用戶界面時可能會慢一點(diǎn)。
另外,當(dāng)我們從構(gòu)建任務(wù)的數(shù)量上考慮時,我們的下一個挑戰(zhàn)就是如何去擴(kuò)展我們的數(shù)據(jù)容量。
Travis CI在500臺構(gòu)建服務(wù)器上運(yùn)行,這已經(jīng)不能再算是一個小的分布式系統(tǒng)了。我們現(xiàn)在正著手解決的問題還是從一個相當(dāng)小的維度來考慮的,但即便在那個維度上,你也能夠遇到很多有趣的挑戰(zhàn)。根據(jù)我們的經(jīng)驗,簡單直接的解決方案總是比那些更復(fù)雜的要好。
原文鏈接:http://www.paperplanes.de/2013/10/18/the-smallest-distributed-system.html