Spark:一個(gè)高效的分布式計(jì)算系統(tǒng)
概述
什么是Spark
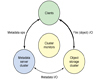
◆ Spark是UC Berkeley AMP lab所開(kāi)源的類Hadoop MapReduce的通用的并行計(jì)算框架,Spark基于map reduce算法實(shí)現(xiàn)的分布式計(jì)算,擁有Hadoop MapReduce所具有的優(yōu)點(diǎn);但不同于MapReduce的是Job中間輸出和結(jié)果可以保存在內(nèi)存中,從而不再需要讀寫HDFS,因此Spark能更好地適用于數(shù)據(jù)挖掘與機(jī)器學(xué)習(xí)等需要迭代的map reduce的算法。其架構(gòu)如下圖所示:
Spark與Hadoop的對(duì)比
◆ Spark的中間數(shù)據(jù)放到內(nèi)存中,對(duì)于迭代運(yùn)算效率更高。
- Spark更適合于迭代運(yùn)算比較多的ML和DM運(yùn)算。因?yàn)樵赟park里面,有RDD的抽象概念。
◆ Spark比Hadoop更通用。
- Spark提供的數(shù)據(jù)集操作類型有很多種,不像Hadoop只提供了Map和Reduce兩種操作。比如map, filter, flatMap, sample, groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionBy等多種操作類型,Spark把這些操作稱為Transformations。同時(shí)還提供Count, collect, reduce, lookup, save等多種actions操作。
- 這些多種多樣的數(shù)據(jù)集操作類型,給給開(kāi)發(fā)上層應(yīng)用的用戶提供了方便。各個(gè)處理節(jié)點(diǎn)之間的通信模型不再像Hadoop那樣就是唯一的Data Shuffle一種模式。用戶可以命名,物化,控制中間結(jié)果的存儲(chǔ)、分區(qū)等。可以說(shuō)編程模型比Hadoop更靈活。
- 不過(guò)由于RDD的特性,Spark不適用那種異步細(xì)粒度更新?tīng)顟B(tài)的應(yīng)用,例如web服務(wù)的存儲(chǔ)或者是增量的web爬蟲(chóng)和索引。就是對(duì)于那種增量修改的應(yīng)用模型不適合。
◆ 容錯(cuò)性。
- 在分布式數(shù)據(jù)集計(jì)算時(shí)通過(guò)checkpoint來(lái)實(shí)現(xiàn)容錯(cuò),而checkpoint有兩種方式,一個(gè)是checkpoint data,一個(gè)是logging the updates。用戶可以控制采用哪種方式來(lái)實(shí)現(xiàn)容錯(cuò)。
◆ 可用性。
- Spark通過(guò)提供豐富的Scala, Java,Python API及交互式Shell來(lái)提高可用性。
Spark與Hadoop的結(jié)合
◆ Spark可以直接對(duì)HDFS進(jìn)行數(shù)據(jù)的讀寫,同樣支持Spark on YARN。Spark可以與MapReduce運(yùn)行于同集群中,共享存儲(chǔ)資源與計(jì)算,數(shù)據(jù)倉(cāng)庫(kù)Shark實(shí)現(xiàn)上借用Hive,幾乎與Hive完全兼容。
Spark的適用場(chǎng)景
◆ Spark是基于內(nèi)存的迭代計(jì)算框架,適用于需要多次操作特定數(shù)據(jù)集的應(yīng)用場(chǎng)合。需要反復(fù)操作的次數(shù)越多,所需讀取的數(shù)據(jù)量越大,受益越大,數(shù)據(jù)量小但是計(jì)算密集度較大的場(chǎng)合,受益就相對(duì)較小
◆ 由于RDD的特性,Spark不適用那種異步細(xì)粒度更新?tīng)顟B(tài)的應(yīng)用,例如web服務(wù)的存儲(chǔ)或者是增量的web爬蟲(chóng)和索引。就是對(duì)于那種增量修改的應(yīng)用模型不適合。
◆ 總的來(lái)說(shuō)Spark的適用面比較廣泛且比較通用。
運(yùn)行模式
◆ 本地模式
◆ Standalone模式
◆ Mesoes模式
◆ yarn模式
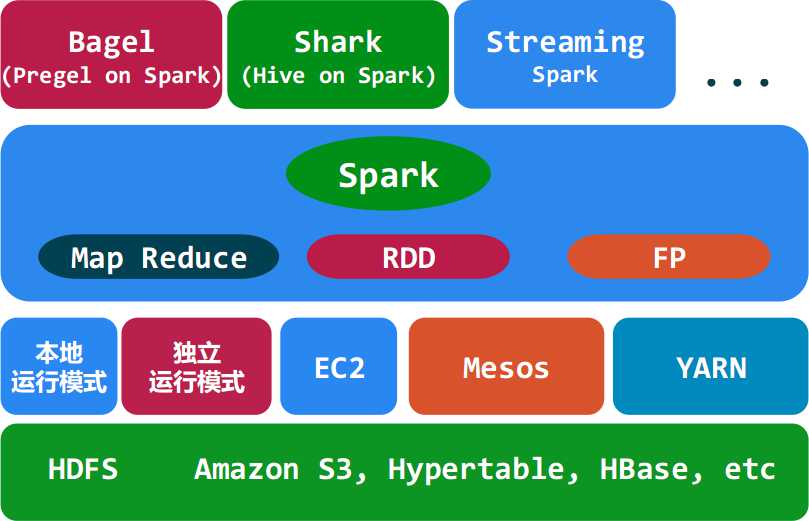
Spark生態(tài)系統(tǒng)
◆ Shark ( Hive on Spark): Shark基本上就是在Spark的框架基礎(chǔ)上提供和Hive一樣的H iveQL命令接口,為了最大程度的保持和Hive的兼容性,Shark使用了Hive的API來(lái)實(shí)現(xiàn)query Parsing和 Logic Plan generation,最后的PhysicalPlan execution階段用Spark代替Hadoop MapReduce。通過(guò)配置Shark參數(shù),Shark可以自動(dòng)在內(nèi)存中緩存特定的RDD,實(shí)現(xiàn)數(shù)據(jù)重用,進(jìn)而加快特定數(shù)據(jù)集的檢索。同時(shí),Shark通過(guò)UDF用戶自定義函數(shù)實(shí)現(xiàn)特定的數(shù)據(jù)分析學(xué)習(xí)算法,使得SQL數(shù)據(jù)查詢和運(yùn)算分析能結(jié)合在一起,最大化RDD的重復(fù)使用。
◆ Spark streaming: 構(gòu)建在Spark上處理Stream數(shù)據(jù)的框架,基本的原理是將Stream數(shù)據(jù)分成小的時(shí)間片斷(幾秒),以類似batch批量處理的方式來(lái)處理這小部分?jǐn)?shù)據(jù)。Spark Streaming構(gòu)建在Spark上,一方面是因?yàn)镾park的低延遲執(zhí)行引擎(100ms+)可以用于實(shí)時(shí)計(jì)算,另一方面相比基于Record的其它處理框架(如Storm),RDD數(shù)據(jù)集更容易做高效的容錯(cuò)處理。此外小批量處理的方式使得它可以同時(shí)兼容批量和實(shí)時(shí)數(shù)據(jù)處理的邏輯和算法。方便了一些需要?dú)v史數(shù)據(jù)和實(shí)時(shí)數(shù)據(jù)聯(lián)合分析的特定應(yīng)用場(chǎng)合。
◆ Bagel: Pregel on Spark,可以用Spark進(jìn)行圖計(jì)算,這是個(gè)非常有用的小項(xiàng)目。Bagel自帶了一個(gè)例子,實(shí)現(xiàn)了Google的PageRank算法。
#p#
在業(yè)界的使用
◆ Spark項(xiàng)目在2009年啟動(dòng),2010年開(kāi)源, 現(xiàn)在使用的有:Berkeley, Princeton, Klout, Foursquare, Conviva, Quantifind, Yahoo! Research & others, 淘寶等,豆瓣也在使用Spark的python克隆版Dpark。
Spark核心概念
Resilient Distributed Dataset (RDD)彈性分布數(shù)據(jù)集
◆ RDD是Spark的最基本抽象,是對(duì)分布式內(nèi)存的抽象使用,實(shí)現(xiàn)了以操作本地集合的方式來(lái)操作分布式數(shù)據(jù)集的抽象實(shí)現(xiàn)。RDD是Spark最核心的東西,它表示已被分區(qū),不可變的并能夠被并行操作的數(shù)據(jù)集合,不同的數(shù)據(jù)集格式對(duì)應(yīng)不同的RDD實(shí)現(xiàn)。RDD必須是可序列化的。RDD可以cache到內(nèi)存中,每次對(duì)RDD數(shù)據(jù)集的操作之后的結(jié)果,都可以存放到內(nèi)存中,下一個(gè)操作可以直接從內(nèi)存中輸入,省去了MapReduce大量的磁盤IO操作。這對(duì)于迭代運(yùn)算比較常見(jiàn)的機(jī)器學(xué)習(xí)算法, 交互式數(shù)據(jù)挖掘來(lái)說(shuō),效率提升比較大。
◆ RDD的特點(diǎn):
- 它是在集群節(jié)點(diǎn)上的不可變的、已分區(qū)的集合對(duì)象。
- 通過(guò)并行轉(zhuǎn)換的方式來(lái)創(chuàng)建如(map, filter, join, etc)。
- 失敗自動(dòng)重建。
- 可以控制存儲(chǔ)級(jí)別(內(nèi)存、磁盤等)來(lái)進(jìn)行重用。
- 必須是可序列化的。
- 是靜態(tài)類型的。
◆ RDD的好處
- RDD只能從持久存儲(chǔ)或通過(guò)Transformations操作產(chǎn)生,相比于分布式共享內(nèi)存(DSM)可以更高效實(shí)現(xiàn)容錯(cuò),對(duì)于丟失部分?jǐn)?shù)據(jù)分區(qū)只需根據(jù)它的lineage就可重新計(jì)算出來(lái),而不需要做特定的Checkpoint。
- RDD的不變性,可以實(shí)現(xiàn)類Hadoop MapReduce的推測(cè)式執(zhí)行。
- RDD的數(shù)據(jù)分區(qū)特性,可以通過(guò)數(shù)據(jù)的本地性來(lái)提高性能,這與Hadoop MapReduce是一樣的。
- RDD都是可序列化的,在內(nèi)存不足時(shí)可自動(dòng)降級(jí)為磁盤存儲(chǔ),把RDD存儲(chǔ)于磁盤上,這時(shí)性能會(huì)有大的下降但不會(huì)差于現(xiàn)在的MapReduce。
◆ RDD的存儲(chǔ)與分區(qū)
- 用戶可以選擇不同的存儲(chǔ)級(jí)別存儲(chǔ)RDD以便重用。
- 當(dāng)前RDD默認(rèn)是存儲(chǔ)于內(nèi)存,但當(dāng)內(nèi)存不足時(shí),RDD會(huì)spill到disk。
- RDD在需要進(jìn)行分區(qū)把數(shù)據(jù)分布于集群中時(shí)會(huì)根據(jù)每條記錄Key進(jìn)行分區(qū)(如Hash 分區(qū)),以此保證兩個(gè)數(shù)據(jù)集在Join時(shí)能高效。
◆ RDD的內(nèi)部表示
在RDD的內(nèi)部實(shí)現(xiàn)中每個(gè)RDD都可以使用5個(gè)方面的特性來(lái)表示:
- 分區(qū)列表(數(shù)據(jù)塊列表)
- 計(jì)算每個(gè)分片的函數(shù)(根據(jù)父RDD計(jì)算出此RDD)
- 對(duì)父RDD的依賴列表
- 對(duì)key-value RDD的Partitioner【可選】
- 每個(gè)數(shù)據(jù)分片的預(yù)定義地址列表(如HDFS上的數(shù)據(jù)塊的地址)【可選】
◆ RDD的存儲(chǔ)級(jí)別
RDD根據(jù)useDisk、useMemory、deserialized、replication四個(gè)參數(shù)的組合提供了11種存儲(chǔ)級(jí)別:
- val NONE = new StorageLevel(false, false, false)
- val DISK_ONLY = new StorageLevel(true, false, false)
- val DISK_ONLY_2 = new StorageLevel(true, false, false, 2)
- val MEMORY_ONLY = new StorageLevel(false, true, true)
- val MEMORY_ONLY_2 = new StorageLevel(false, true, true, 2)
- val MEMORY_ONLY_SER = new StorageLevel(false, true, false)
- val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, 2)
- val MEMORY_AND_DISK = new StorageLevel(true, true, true)
- val MEMORY_AND_DISK_2 = new StorageLevel(true, true, true, 2)
- val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false)
- val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, 2)
◆ RDD定義了各種操作,不同類型的數(shù)據(jù)由不同的RDD類抽象表示,不同的操作也由RDD進(jìn)行抽實(shí)現(xiàn)。
RDD的生成
◆ RDD有兩種創(chuàng)建方式:
1、從Hadoop文件系統(tǒng)(或與Hadoop兼容的其它存儲(chǔ)系統(tǒng))輸入(例如HDFS)創(chuàng)建。
2、從父RDD轉(zhuǎn)換得到新RDD。
◆ 下面來(lái)看一從Hadoop文件系統(tǒng)生成RDD的方式,如:val file = spark.textFile("hdfs://..."),file變量就是RDD(實(shí)際是HadoopRDD實(shí)例),生成的它的核心代碼如下:
- // SparkContext根據(jù)文件/目錄及可選的分片數(shù)創(chuàng)建RDD, 這里我們可以看到Spark與Hadoop MapReduce很像
- // 需要InputFormat, Key、Value的類型,其實(shí)Spark使用的Hadoop的InputFormat, Writable類型。
- def textFile(path: String, minSplits: Int = defaultMinSplits): RDD[String] = {
- hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable],
- classOf[Text], minSplits) .map(pair => pair._2.toString) }
- // 根據(jù)Hadoop配置,及InputFormat等創(chuàng)建HadoopRDD
- new HadoopRDD(this, conf, inputFormatClass, keyClass, valueClass, minSplits)
◆ 對(duì)RDD進(jìn)行計(jì)算時(shí),RDD從HDFS讀取數(shù)據(jù)時(shí)與Hadoop MapReduce幾乎一樣的:
RDD的轉(zhuǎn)換與操作
◆ 對(duì)于RDD可以有兩種計(jì)算方式:轉(zhuǎn)換(返回值還是一個(gè)RDD)與操作(返回值不是一個(gè)RDD)。
◆ 轉(zhuǎn)換(Transformations) (如:map, filter, groupBy, join等),Transformations操作是Lazy的,也就是說(shuō)從一個(gè)RDD轉(zhuǎn)換生成另一個(gè)RDD的操作不是馬上執(zhí)行,Spark在遇到Transformations操作時(shí)只會(huì)記錄需要這樣的操作,并不會(huì)去執(zhí)行,需要等到有Actions操作的時(shí)候才會(huì)真正啟動(dòng)計(jì)算過(guò)程進(jìn)行計(jì)算。
◆ 操作(Actions) (如:count, collect, save等),Actions操作會(huì)返回結(jié)果或把RDD數(shù)據(jù)寫到存儲(chǔ)系統(tǒng)中。Actions是觸發(fā)Spark啟動(dòng)計(jì)算的動(dòng)因。
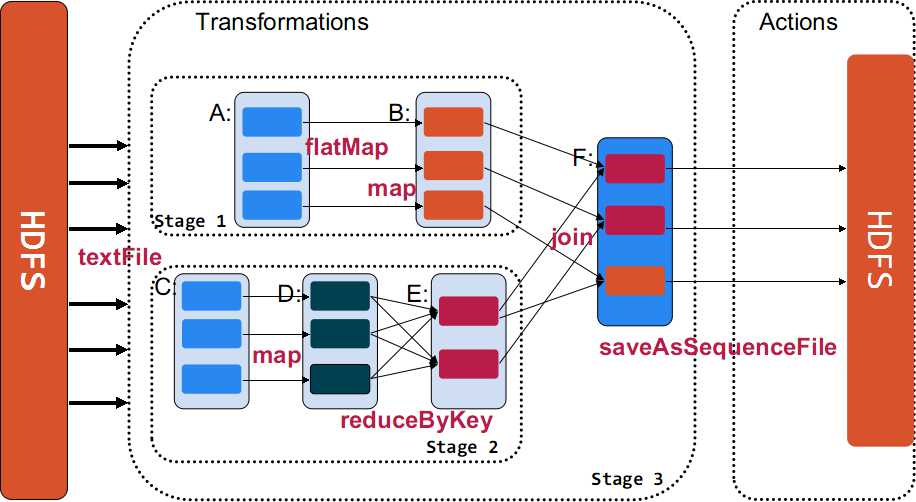
◆ 下面使用一個(gè)例子來(lái)示例說(shuō)明Transformations與Actions在Spark的使用。
- val sc = new SparkContext(master, "Example", System.getenv("SPARK_HOME"),
- Seq(System.getenv("SPARK_TEST_JAR")))
- val rdd_A = sc.textFile(hdfs://.....)
- val rdd_B = rdd_A.flatMap((line => line.split("\\s+"))).map(word => (word, 1))
- val rdd_C = sc.textFile(hdfs://.....)
- val rdd_D = rdd_C.map(line => (line.substring(10), 1))
- val rdd_E = rdd_D.reduceByKey((a, b) => a + b)
- val rdd_F = rdd_B.jion(rdd_E)
- rdd_F.saveAsSequenceFile(hdfs://....)
#p#
Lineage(血統(tǒng))
◆ 利用內(nèi)存加快數(shù)據(jù)加載,在眾多的其它的In-Memory類數(shù)據(jù)庫(kù)或Cache類系統(tǒng)中也有實(shí)現(xiàn),Spark的主要區(qū)別在于它處理分布式運(yùn)算環(huán)境下的數(shù)據(jù)容錯(cuò)性(節(jié)點(diǎn)實(shí)效/數(shù)據(jù)丟失)問(wèn)題時(shí)采用的方案。為了保證RDD中數(shù)據(jù)的魯棒性,RDD數(shù)據(jù)集通過(guò)所謂的血統(tǒng)關(guān)系(Lineage)記住了它是如何從其它RDD中演變過(guò)來(lái)的。相比其它系統(tǒng)的細(xì)顆粒度的內(nèi)存數(shù)據(jù)更新級(jí)別的備份或者LOG機(jī)制,RDD的Lineage記錄的是粗顆粒度的特定數(shù)據(jù)轉(zhuǎn)換(Transformation)操作(filter, map, join etc.)行為。當(dāng)這個(gè)RDD的部分分區(qū)數(shù)據(jù)丟失時(shí),它可以通過(guò)Lineage獲取足夠的信息來(lái)重新運(yùn)算和恢復(fù)丟失的數(shù)據(jù)分區(qū)。這種粗顆粒的數(shù)據(jù)模型,限制了Spark的運(yùn)用場(chǎng)合,但同時(shí)相比細(xì)顆粒度的數(shù)據(jù)模型,也帶來(lái)了性能的提升。
◆ RDD在Lineage依賴方面分為兩種Narrow Dependencies與Wide Dependencies用來(lái)解決數(shù)據(jù)容錯(cuò)的高效性。Narrow Dependencies是指父RDD的每一個(gè)分區(qū)最多被一個(gè)子RDD的分區(qū)所用,表現(xiàn)為一個(gè)父RDD的分區(qū)對(duì)應(yīng)于一個(gè)子RDD的分區(qū)或多個(gè)父RDD的分區(qū)對(duì)應(yīng)于一個(gè)子RDD的分區(qū),也就是說(shuō)一個(gè)父RDD的一個(gè)分區(qū)不可能對(duì)應(yīng)一個(gè)子RDD的多個(gè)分區(qū)。Wide Dependencies是指子RDD的分區(qū)依賴于父RDD的多個(gè)分區(qū)或所有分區(qū),也就是說(shuō)存在一個(gè)父RDD的一個(gè)分區(qū)對(duì)應(yīng)一個(gè)子RDD的多個(gè)分區(qū)。對(duì)與Wide Dependencies,這種計(jì)算的輸入和輸出在不同的節(jié)點(diǎn)上,lineage方法對(duì)與輸入節(jié)點(diǎn)完好,而輸出節(jié)點(diǎn)宕機(jī)時(shí),通過(guò)重新計(jì)算,這種情況下,這種方法容錯(cuò)是有效的,否則無(wú)效,因?yàn)闊o(wú)法重試,需要向上其祖先追溯看是否可以重試(這就是lineage,血統(tǒng)的意思),Narrow Dependencies對(duì)于數(shù)據(jù)的重算開(kāi)銷要遠(yuǎn)小于Wide Dependencies的數(shù)據(jù)重算開(kāi)銷。
容錯(cuò)
◆ 在RDD計(jì)算,通過(guò)checkpint進(jìn)行容錯(cuò),做checkpoint有兩種方式,一個(gè)是checkpoint data,一個(gè)是logging the updates。用戶可以控制采用哪種方式來(lái)實(shí)現(xiàn)容錯(cuò),默認(rèn)是logging the updates方式,通過(guò)記錄跟蹤所有生成RDD的轉(zhuǎn)換(transformations)也就是記錄每個(gè)RDD的lineage(血統(tǒng))來(lái)重新計(jì)算生成丟失的分區(qū)數(shù)據(jù)。
資源管理與作業(yè)調(diào)度
◆ Spark對(duì)于資源管理與作業(yè)調(diào)度可以使用Standalone(獨(dú)立模式),Apache Mesos及Hadoop YARN來(lái)實(shí)現(xiàn)。 Spark on Yarn在Spark0.6時(shí)引用,但真正可用是在現(xiàn)在的branch-0.8版本。Spark on Yarn遵循YARN的官方規(guī)范實(shí)現(xiàn),得益于Spark天生支持多種Scheduler和Executor的良好設(shè)計(jì),對(duì)YARN的支持也就非常容易,Spark on Yarn的大致框架圖。
◆ 讓Spark運(yùn)行于YARN上與Hadoop共用集群資源可以提高資源利用率。
編程接口
◆ Spark通過(guò)與編程語(yǔ)言集成的方式暴露RDD的操作,類似于DryadLINQ和FlumeJava,每個(gè)數(shù)據(jù)集都表示為RDD對(duì)象,對(duì)數(shù)據(jù)集的操作就表示成對(duì)RDD對(duì)象的操作。Spark主要的編程語(yǔ)言是Scala,選擇Scala是因?yàn)樗暮?jiǎn)潔性(Scala可以很方便在交互式下使用)和性能(JVM上的靜態(tài)強(qiáng)類型語(yǔ)言)。
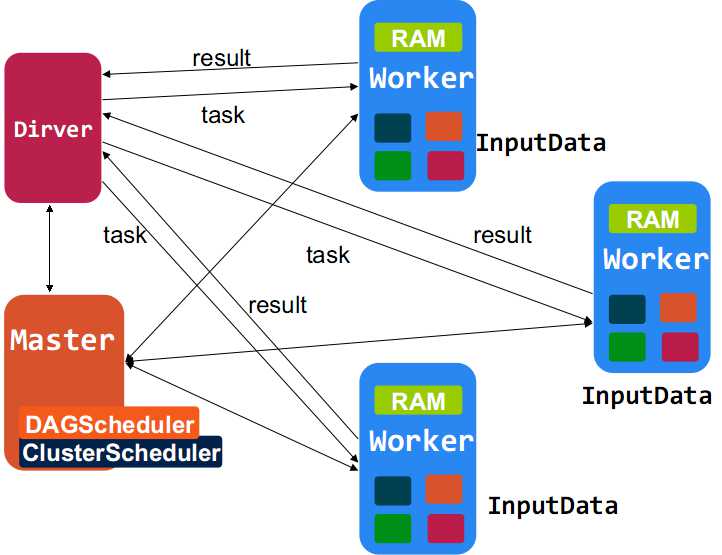
◆ Spark和Hadoop MapReduce類似,由Master(類似于MapReduce的Jobtracker)和Workers(Spark的Slave工作節(jié)點(diǎn))組成。用戶編寫的Spark程序被稱為Driver程序,Dirver程序會(huì)連接master并定義了對(duì)各RDD的轉(zhuǎn)換與操作,而對(duì)RDD的轉(zhuǎn)換與操作通過(guò)Scala閉包(字面量函數(shù))來(lái)表示,Scala使用Java對(duì)象來(lái)表示閉包且都是可序列化的,以此把對(duì)RDD的閉包操作發(fā)送到各Workers節(jié)點(diǎn)。 Workers存儲(chǔ)著數(shù)據(jù)分塊和享有集群內(nèi)存,是運(yùn)行在工作節(jié)點(diǎn)上的守護(hù)進(jìn)程,當(dāng)它收到對(duì)RDD的操作時(shí),根據(jù)數(shù)據(jù)分片信息進(jìn)行本地化數(shù)據(jù)操作,生成新的數(shù)據(jù)分片、返回結(jié)果或把RDD寫入存儲(chǔ)系統(tǒng)。
Scala
◆ Spark使用Scala開(kāi)發(fā),默認(rèn)使用Scala作為編程語(yǔ)言。編寫Spark程序比編寫Hadoop MapReduce程序要簡(jiǎn)單的多,SparK提供了Spark-Shell,可以在Spark-Shell測(cè)試程序。寫SparK程序的一般步驟就是創(chuàng)建或使用(SparkContext)實(shí)例,使用SparkContext創(chuàng)建RDD,然后就是對(duì)RDD進(jìn)行操作。如:
- val sc = new SparkContext(master, appName, [sparkHome], [jars])
- val textFile = sc.textFile("hdfs://.....")
- textFile.map(....).filter(.....).....
Java
◆ Spark支持Java編程,但對(duì)于使用Java就沒(méi)有了Spark-Shell這樣方便的工具,其它與Scala編程是一樣的,因?yàn)槎际荍VM上的語(yǔ)言,Scala與Java可以互操作,Java編程接口其實(shí)就是對(duì)Scala的封裝。如:
- JavaSparkContext sc = new JavaSparkContext(...);
- JavaRDD lines = ctx.textFile("hdfs://...");
- JavaRDD words = lines.flatMap(
- new FlatMapFunction<String, String>() {
- public Iterable call(String s) {
- return Arrays.asList(s.split(" "));
- }
- }
- );
Python
◆ 現(xiàn)在Spark也提供了Python編程接口,Spark使用py4j來(lái)實(shí)現(xiàn)python與java的互操作,從而實(shí)現(xiàn)使用python編寫Spark程序。Spark也同樣提供了pyspark,一個(gè)Spark的python shell,可以以交互式的方式使用Python編寫Spark程序。 如:
- from pyspark import SparkContext
- sc = SparkContext("local", "Job Name", pyFiles=['MyFile.py', 'lib.zip', 'app.egg'])
- words = sc.textFile("/usr/share/dict/words")
- words.filter(lambda w: w.startswith("spar")).take(5)
#p#
使用示例
Standalone模式
◆ 為方便Spark的推廣使用,Spark提供了Standalone模式,Spark一開(kāi)始就設(shè)計(jì)運(yùn)行于Apache Mesos資源管理框架上,這是非常好的設(shè)計(jì),但是卻帶了部署測(cè)試的復(fù)雜性。為了讓Spark能更方便的部署和嘗試,Spark因此提供了Standalone運(yùn)行模式,它由一個(gè)Spark Master和多個(gè)Spark worker組成,與Hadoop MapReduce1很相似,就連集群?jiǎn)?dòng)方式都幾乎是一樣。
◆ 以Standalone模式運(yùn)行Spark集群
- 下載Scala2.9.3,并配置SCALA_HOME
- 下載Spark代碼(可以使用源碼編譯也可以下載編譯好的版本)這里下載 編譯好的版本(
http://spark-project.org/download/spark-0.7.3-prebuilt-cdh4.tgz) - 解壓spark-0.7.3-prebuilt-cdh4.tgz安裝包
- 修改配置(conf/*) slaves: 配置工作節(jié)點(diǎn)的主機(jī)名 spark-env.sh:配置環(huán)境變量。
- SCALA_HOME=/home/spark/scala-2.9.3
- JAVA_HOME=/home/spark/jdk1.6.0_45
- SPARK_MASTER_IP=spark1
- SPARK_MASTER_PORT=30111
- SPARK_MASTER_WEBUI_PORT=30118
- SPARK_WORKER_CORES=2 SPARK_WORKER_MEMORY=4g
- SPARK_WORKER_PORT=30333
- SPARK_WORKER_WEBUI_PORT=30119
- SPARK_WORKER_INSTANCES=1
◆ 把Hadoop配置copy到conf目錄下
◆ 在master主機(jī)上對(duì)其它機(jī)器做ssh無(wú)密碼登錄
◆ 把配置好的Spark程序使用scp copy到其它機(jī)器
◆ 在master啟動(dòng)集群
- $SPARK_HOME/start-all.sh
yarn模式
◆ Spark-shell現(xiàn)在還不支持Yarn模式,使用Yarn模式運(yùn)行,需要把Spark程序全部打包成一個(gè)jar包提交到Y(jié)arn上運(yùn)行。目錄只有branch-0.8版本才真正支持Yarn。
◆ 以Yarn模式運(yùn)行Spark
下載Spark代碼.
- git clone git://github.com/mesos/spark
◆ 切換到branch-0.8
- cd spark
- git checkout -b yarn --track origin/yarn
◆ 使用sbt編譯Spark并
- $SPARK_HOME/sbt/sbt
- > package
- > assembly
◆ 把Hadoop yarn配置copy到conf目錄下
◆ 運(yùn)行測(cè)試
- SPARK_JAR=./core/target/scala-2.9.3/spark-core-assembly-0.8.0-SNAPSHOT.jar \
- ./run spark.deploy.yarn.Client --jar examples/target/scala-2.9.3/ \
- --class spark.examples.SparkPi --args yarn-standalone
使用Spark-shell
◆ Spark-shell使用很簡(jiǎn)單,當(dāng)Spark以Standalon模式運(yùn)行后,使用$SPARK_HOME/spark-shell進(jìn)入shell即可,在Spark-shell中SparkContext已經(jīng)創(chuàng)建好了,實(shí)例名為sc可以直接使用,還有一個(gè)需要注意的是,在Standalone模式下,Spark默認(rèn)使用的調(diào)度器的FIFO調(diào)度器而不是公平調(diào)度,而Spark-shell作為一個(gè)Spark程序一直運(yùn)行在Spark上,其它的Spark程序就只能排隊(duì)等待,也就是說(shuō)同一時(shí)間只能有一個(gè)Spark-shell在運(yùn)行。
◆ 在Spark-shell上寫程序非常簡(jiǎn)單,就像在Scala Shell上寫程序一樣。
- scala> val textFile = sc.textFile("hdfs://hadoop1:2323/user/data")
- textFile: spark.RDD[String] = spark.MappedRDD@2ee9b6e3
- scala> textFile.count() // Number of items in this RDD
- res0: Long = 21374
- scala> textFile.first() // First item in this RDD
- res1: String = # Spark
編寫Driver程序
◆ 在Spark中Spark程序稱為Driver程序,編寫Driver程序很簡(jiǎn)單幾乎與在Spark-shell上寫程序是一樣的,不同的地方就是SparkContext需要自己創(chuàng)建。如WorkCount程序如下:
- import spark.SparkContext
- import SparkContext._
- object WordCount {
- def main(args: Array[String]) {
- if (args.length ==0 ){
- println("usage is org.test.WordCount ")
- }
- println("the args: ")
- args.foreach(println)
- val hdfsPath = "hdfs://hadoop1:8020"
- // create the SparkContext, args(0)由yarn傳入appMaster地址
- val sc = new SparkContext(args(0), "WrodCount",
- System.getenv("SPARK_HOME"), Seq(System.getenv("SPARK_TEST_JAR")))
- val textFile = sc.textFile(hdfsPath + args(1))
- val result = textFile.flatMap(line => line.split("\\s+"))
- .map(word => (word, 1)).reduceByKey(_ + _)
- result.saveAsTextFile(hdfsPath + args(2))
- }
- }