Hadoop集群系列5:Hadoop安裝配置
1、集群部署介紹
1.1 Hadoop簡(jiǎn)介
 Hadoop是Apache軟件基金會(huì)旗下的一個(gè)開(kāi)源分布式計(jì)算平臺(tái)。以Hadoop分布式文件系統(tǒng)(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的開(kāi)源實(shí)現(xiàn))為核心的Hadoop為用戶(hù)提供了系統(tǒng)底層細(xì)節(jié)透明的分布式基礎(chǔ)架構(gòu)。
Hadoop是Apache軟件基金會(huì)旗下的一個(gè)開(kāi)源分布式計(jì)算平臺(tái)。以Hadoop分布式文件系統(tǒng)(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的開(kāi)源實(shí)現(xiàn))為核心的Hadoop為用戶(hù)提供了系統(tǒng)底層細(xì)節(jié)透明的分布式基礎(chǔ)架構(gòu)。
對(duì)于Hadoop的集群來(lái)講,可以分成兩大類(lèi)角色:Master和Salve。一個(gè)HDFS集群是由一個(gè)NameNode和若干個(gè)DataNode組成的。其中NameNode作為主服務(wù)器,管理文件系統(tǒng)的命名空間和客戶(hù)端對(duì)文件系統(tǒng)的訪(fǎng)問(wèn)操作;集群中的DataNode管理存儲(chǔ)的數(shù)據(jù)。MapReduce框架是由一個(gè)單獨(dú)運(yùn)行在主節(jié)點(diǎn)上的JobTracker和運(yùn)行在每個(gè)集群從節(jié)點(diǎn)的TaskTracker共同組成的。主節(jié)點(diǎn)負(fù)責(zé)調(diào)度構(gòu)成一個(gè)作業(yè)的所有任務(wù),這些任務(wù)分布在不同的從節(jié)點(diǎn)上。主節(jié)點(diǎn)監(jiān)控它們的執(zhí)行情況,并且重新執(zhí)行之前的失敗任務(wù);從節(jié)點(diǎn)僅負(fù)責(zé)由主節(jié)點(diǎn)指派的任務(wù)。當(dāng)一個(gè)Job被提交時(shí),JobTracker接收到提交作業(yè)和配置信息之后,就會(huì)將配置信息等分發(fā)給從節(jié)點(diǎn),同時(shí)調(diào)度任務(wù)并監(jiān)控TaskTracker的執(zhí)行。
從上面的介紹可以看出,HDFS和MapReduce共同組成了Hadoop分布式系統(tǒng)體系結(jié)構(gòu)的核心。HDFS在集群上實(shí)現(xiàn)分布式文件系統(tǒng),MapReduce在集群上實(shí)現(xiàn)了分布式計(jì)算和任務(wù)處理。HDFS在MapReduce任務(wù)處理過(guò)程中提供了文件操作和存儲(chǔ)等支持,MapReduce在HDFS的基礎(chǔ)上實(shí)現(xiàn)了任務(wù)的分發(fā)、跟蹤、執(zhí)行等工作,并收集結(jié)果,二者相互作用,完成了Hadoop分布式集群的主要任務(wù)。
1.2 環(huán)境說(shuō)明
集群中包括4個(gè)節(jié)點(diǎn):1個(gè)Master,3個(gè)Salve,節(jié)點(diǎn)之間局域網(wǎng)連接,可以相互ping通,具體集群信息可以查看"Hadoop集群(第2期)"。節(jié)點(diǎn)IP地址分布如下:
|
機(jī)器名稱(chēng) |
IP地址 |
|
Master.Hadoop |
192.168.1.2 |
|
Salve1.Hadoop |
192.168.1.3 |
|
Salve2.Hadoop |
192.168.1.4 |
|
Salve3.Hadoop |
192.168.1.5 |
四個(gè)節(jié)點(diǎn)上均是CentOS6.0系統(tǒng),并且有一個(gè)相同的用戶(hù)hadoop。Master機(jī)器主要配置NameNode和JobTracker的角色,負(fù)責(zé)總管分布式數(shù)據(jù)和分解任務(wù)的執(zhí)行;3個(gè)Salve機(jī)器配置DataNode和TaskTracker的角色,負(fù)責(zé)分布式數(shù)據(jù)存儲(chǔ)以及任務(wù)的執(zhí)行。其實(shí)應(yīng)該還應(yīng)該有1個(gè)Master機(jī)器,用來(lái)作為備用,以防止Master服務(wù)器宕機(jī),還有一個(gè)備用馬上啟用。后續(xù)經(jīng)驗(yàn)積累一定階段后補(bǔ)上一臺(tái)備用Master機(jī)器。
1.3 網(wǎng)絡(luò)配置
Hadoop集群要按照1.2小節(jié)表格所示進(jìn)行配置,我們?cè)?quot;Hadoop集群(第1期)"的CentOS6.0安裝過(guò)程就按照提前規(guī)劃好的主機(jī)名進(jìn)行安裝和配置。如果實(shí)驗(yàn)室后來(lái)人在安裝系統(tǒng)時(shí),沒(méi)有配置好,不要緊,沒(méi)有必要重新安裝,在安裝完系統(tǒng)之后仍然可以根據(jù)后來(lái)的規(guī)劃對(duì)機(jī)器的主機(jī)名進(jìn)行修改。
下面的例子我們將以Master機(jī)器為例,即主機(jī)名為"Master.Hadoop",IP為"192.168.1.2"進(jìn)行一些主機(jī)名配置的相關(guān)操作。其他的Slave機(jī)器以此為依據(jù)進(jìn)行修改。
1)查看當(dāng)前機(jī)器名稱(chēng)
用下面命令進(jìn)行顯示機(jī)器名稱(chēng),如果跟規(guī)劃的不一致,要按照下面進(jìn)行修改。
hostname

上圖中,用"hostname"查"Master"機(jī)器的名字為"Master.Hadoop",與我們預(yù)先規(guī)劃的一致。
2)修改當(dāng)前機(jī)器名稱(chēng)
假定我們發(fā)現(xiàn)我們的機(jī)器的主機(jī)名不是我們想要的,通過(guò)對(duì)"/etc/sysconfig/network"文件修改其中"HOSTNAME"后面的值,改成我們規(guī)劃的名稱(chēng)。
這個(gè)"/etc/sysconfig/network"文件是定義hostname和是否利用網(wǎng)絡(luò)的不接觸網(wǎng)絡(luò)設(shè)備的對(duì)系統(tǒng)全體定義的文件。
設(shè)定形式:設(shè)定值=值
"/etc/sysconfig/network"的設(shè)定項(xiàng)目如下:
- NETWORKING 是否利用網(wǎng)絡(luò)
- GATEWAY 默認(rèn)網(wǎng)關(guān)
- IPGATEWAYDEV 默認(rèn)網(wǎng)關(guān)的接口名
- HOSTNAME 主機(jī)名
- DOMAIN 域名
用下面命令進(jìn)行修改當(dāng)前機(jī)器的主機(jī)名(備注:修改系統(tǒng)文件一般用root用戶(hù))
vim /etc/sysconfig/network

通過(guò)上面的命令我們從"/etc/sysconfig/network"中找到"HOSTNAME"進(jìn)行修改,查看內(nèi)容如下:

3)修改當(dāng)前機(jī)器IP
假定我們的機(jī)器連IP在當(dāng)時(shí)安裝機(jī)器時(shí)都沒(méi)有配置好,那此時(shí)我們需要對(duì)"ifcfg-eth0"文件進(jìn)行配置,該文件位于"/etc/sysconfig/network-scripts"文件夾下。
在這個(gè)目錄下面,存放的是網(wǎng)絡(luò)接口(網(wǎng)卡)的制御腳本文件(控制文件),ifcfg- eth0是默認(rèn)的第一個(gè)網(wǎng)絡(luò)接口,如果機(jī)器中有多個(gè)網(wǎng)絡(luò)接口,那么名字就將依此類(lèi)推ifcfg-eth1,ifcfg-eth2,ifcfg- eth3,……。
這里面的文件是相當(dāng)重要的,涉及到網(wǎng)絡(luò)能否正常工作。
設(shè)定形式:設(shè)定值=值
設(shè)定項(xiàng)目項(xiàng)目如下:
DEVICE 接口名(設(shè)備,網(wǎng)卡)
BOOTPROTO IP的配置方法(static:固定IP, dhcpHCP, none:手動(dòng))
HWADDR MAC地址
ONBOOT 系統(tǒng)啟動(dòng)的時(shí)候網(wǎng)絡(luò)接口是否有效(yes/no)
TYPE 網(wǎng)絡(luò)類(lèi)型(通常是Ethemet)
NETMASK 網(wǎng)絡(luò)掩碼
IPADDR IP地址
IPV6INIT IPV6是否有效(yes/no)
GATEWAY 默認(rèn)網(wǎng)關(guān)IP地址
查看"/etc/sysconfig/network-scripts/ifcfg-eth0"內(nèi)容,如果IP不復(fù)核,就行修改。
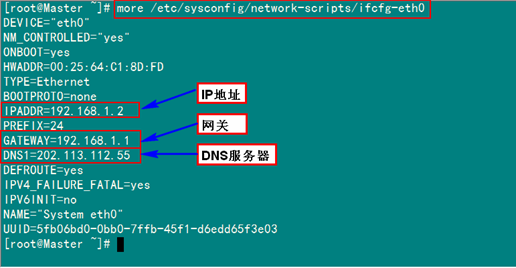
如果上圖中IP與規(guī)劃不相符,用下面命令進(jìn)行修改:
vim /etc/sysconfig/network-scripts/ifcgf-eth0
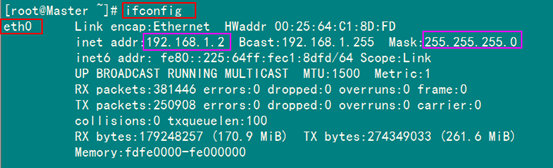
修改完之后可以用"ifconfig"進(jìn)行查看。
4)配置hosts文件(必須)
"/etc/hosts"這個(gè)文件是用來(lái)配置主機(jī)將用的DNS服務(wù)器信息,是記載LAN內(nèi)接續(xù)的各主機(jī)的對(duì)應(yīng)[HostName和IP]用的。當(dāng)用戶(hù)在進(jìn)行網(wǎng)絡(luò)連接時(shí),首先查找該文件,尋找對(duì)應(yīng)主機(jī)名(或域名)對(duì)應(yīng)的IP地址。
我們要測(cè)試兩臺(tái)機(jī)器之間知否連通,一般用"ping 機(jī)器的IP",如果想用"ping 機(jī)器的主機(jī)名"發(fā)現(xiàn)找不見(jiàn)該名稱(chēng)的機(jī)器,解決的辦法就是修改"/etc/hosts"這個(gè)文件,通過(guò)把LAN內(nèi)的各主機(jī)的IP地址和HostName的一一對(duì)應(yīng)寫(xiě)入這個(gè)文件的時(shí)候,就可以解決問(wèn)題。
例如:機(jī)器為"Master.Hadoop:192.168.1.2"對(duì)機(jī)器為"Salve1.Hadoop:192.168.1.3"用命令"ping"記性連接測(cè)試。測(cè)試結(jié)果如下:
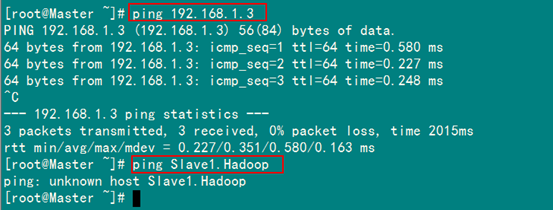
從上圖中的值,直接對(duì)IP地址進(jìn)行測(cè)試,能夠ping通,但是對(duì)主機(jī)名進(jìn)行測(cè)試,發(fā)現(xiàn)沒(méi)有ping通,提示"unknown host——未知主機(jī)",這時(shí)查看"Master.Hadoop"的"/etc/hosts"文件內(nèi)容。

發(fā)現(xiàn)里面沒(méi)有"192.168.1.3 Slave1.Hadoop"內(nèi)容,故而本機(jī)器是無(wú)法對(duì)機(jī)器的主機(jī)名為"Slave1.Hadoop" 解析。
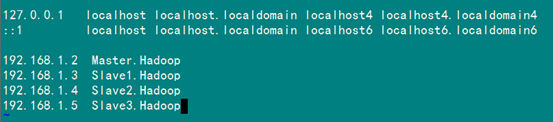
在進(jìn)行Hadoop集群配置中,需要在"/etc/hosts"文件中添加集群中所有機(jī)器的IP與主機(jī)名,這樣Master與所有的Slave機(jī)器之間不僅可以通過(guò)IP進(jìn)行通信,而且還可以通過(guò)主機(jī)名進(jìn)行通信。所以在所有的機(jī)器上的"/etc/hosts"文件末尾中都要添加如下內(nèi)容:
192.168.1.2 Master.Hadoop
192.168.1.3 Slave1.Hadoop
192.168.1.4 Slave2.Hadoop
192.168.1.5 Slave3.Hadoop
用以下命令進(jìn)行添加:
vim /etc/hosts

添加結(jié)果如下:
現(xiàn)在我們?cè)谶M(jìn)行對(duì)機(jī)器為"Slave1.Hadoop"的主機(jī)名進(jìn)行ping通測(cè)試,看是否能測(cè)試成功。
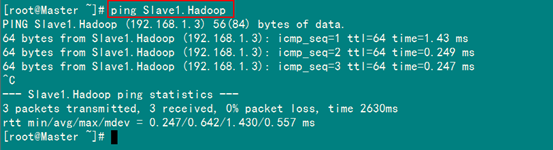
從上圖中我們已經(jīng)能用主機(jī)名進(jìn)行ping通了,說(shuō)明我們剛才添加的內(nèi)容,在局域網(wǎng)內(nèi)能進(jìn)行DNS解析了,那么現(xiàn)在剩下的事兒就是在其余的Slave機(jī)器上進(jìn)行相同的配置。然后進(jìn)行測(cè)試。(備注:當(dāng)設(shè)置SSH無(wú)密碼驗(yàn)證后,可以"scp"進(jìn)行復(fù)制,然后把原來(lái)的"hosts"文件執(zhí)行覆蓋即可。)
1.4 所需軟件
1)JDK軟件
下載地址:http://www.oracle.com/technetwork/java/javase/index.html
JDK版本:jdk-6u31-linux-i586.bin
2)Hadoop軟件
下載地址:http://hadoop.apache.org/common/releases.html
Hadoop版本:hadoop-1.0.0.tar.gz
1.5 VSFTP上傳
在"Hadoop集群(第3期)"講了VSFTP的安裝及配置,如果沒(méi)有安裝VSFTP可以按照該文檔進(jìn)行安裝。如果安裝好了,就可以通過(guò)FlashFXP.exe軟件把我們下載的JDK6.0和Hadoop1.0軟件上傳到"Master.Hadoop:192.168.1.2"服務(wù)器上。
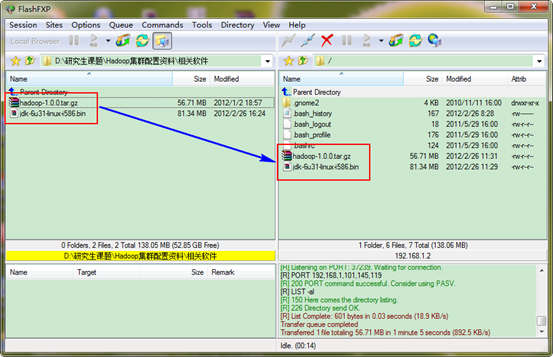
剛才我們用一般用戶(hù)(hadoop)通過(guò)FlashFXP軟件把所需的兩個(gè)軟件上傳了跟目下,我們通過(guò)命令查看下一下是否已經(jīng)上傳了。

從圖中,我們的所需軟件已經(jīng)準(zhǔn)備好了。
2、SSH無(wú)密碼驗(yàn)證配置
Hadoop運(yùn)行過(guò)程中需要管理遠(yuǎn)端Hadoop守護(hù)進(jìn)程,在Hadoop啟動(dòng)以后,NameNode是通過(guò)SSH(Secure Shell)來(lái)啟動(dòng)和停止各個(gè)DataNode上的各種守護(hù)進(jìn)程的。這就必須在節(jié)點(diǎn)之間執(zhí)行指令的時(shí)候是不需要輸入密碼的形式,故我們需要配置SSH運(yùn)用無(wú)密碼公鑰認(rèn)證的形式,這樣NameNode使用SSH無(wú)密碼登錄并啟動(dòng)DataName進(jìn)程,同樣原理,DataNode上也能使用SSH無(wú)密碼登錄到NameNode。
2.1 安裝和啟動(dòng)SSH協(xié)議
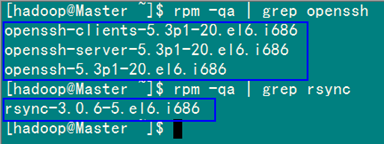
在"Hadoop集群(第1期)"安裝CentOS6.0時(shí),我們選擇了一些基本安裝包,所以我們需要兩個(gè)服務(wù):ssh和rsync已經(jīng)安裝了。可以通過(guò)下面命令查看結(jié)果顯示如下:
rpm –qa | grep openssh
rpm –qa | grep rsync
假設(shè)沒(méi)有安裝ssh和rsync,可以通過(guò)下面命令進(jìn)行安裝。
yum install ssh 安裝SSH協(xié)議
yum install rsync (rsync是一個(gè)遠(yuǎn)程數(shù)據(jù)同步工具,可通過(guò)LAN/WAN快速同步多臺(tái)主機(jī)間的文件)
service sshd restart 啟動(dòng)服務(wù)
確保所有的服務(wù)器都安裝,上面命令執(zhí)行完畢,各臺(tái)機(jī)器之間可以通過(guò)密碼驗(yàn)證相互登。
2.2 配置Master無(wú)密碼登錄所有Salve
1)SSH無(wú)密碼原理
Master(NameNode | JobTracker)作為客戶(hù)端,要實(shí)現(xiàn)無(wú)密碼公鑰認(rèn)證,連接到服務(wù)器Salve(DataNode | Tasktracker)上時(shí),需要在Master上生成一個(gè)密鑰對(duì),包括一個(gè)公鑰和一個(gè)私鑰,而后將公鑰復(fù)制到所有的Slave上。當(dāng)Master通過(guò)SSH連接Salve時(shí),Salve就會(huì)生成一個(gè)隨機(jī)數(shù)并用Master的公鑰對(duì)隨機(jī)數(shù)進(jìn)行加密,并發(fā)送給Master。Master收到加密數(shù)之后再用私鑰解密,并將解密數(shù)回傳給Slave,Slave確認(rèn)解密數(shù)無(wú)誤之后就允許Master進(jìn)行連接了。這就是一個(gè)公鑰認(rèn)證過(guò)程,其間不需要用戶(hù)手工輸入密碼。重要過(guò)程是將客戶(hù)端Master復(fù)制到Slave上。
2)Master機(jī)器上生成密碼對(duì)
在Master節(jié)點(diǎn)上執(zhí)行以下命令:
ssh-keygen –t rsa –P ''
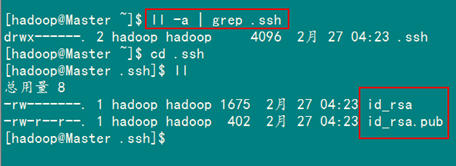
這條命是生成其無(wú)密碼密鑰對(duì),詢(xún)問(wèn)其保存路徑時(shí)直接回車(chē)采用默認(rèn)路徑。生成的密鑰對(duì):id_rsa和id_rsa.pub,默認(rèn)存儲(chǔ)在"/home/hadoop/.ssh"目錄下。
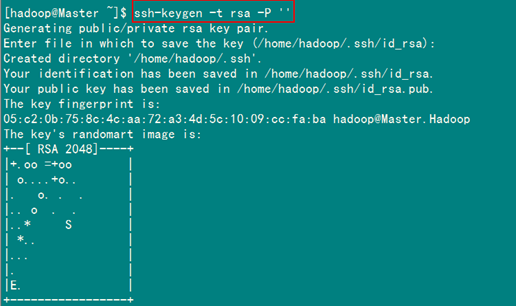
查看"/home/hadoop/"下是否有".ssh"文件夾,且".ssh"文件下是否有兩個(gè)剛生產(chǎn)的無(wú)密碼密鑰對(duì)。
接著在Master節(jié)點(diǎn)上做如下配置,把id_rsa.pub追加到授權(quán)的key里面去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

在驗(yàn)證前,需要做兩件事兒。第一件事兒是修改文件"authorized_keys"權(quán)限(權(quán)限的設(shè)置非常重要,因?yàn)椴话踩脑O(shè)置安全設(shè)置,會(huì)讓你不能使用RSA功能),另一件事兒是用root用戶(hù)設(shè)置"/etc/ssh/sshd_config"的內(nèi)容。使其無(wú)密碼登錄有效。
1)修改文件"authorized_keys"
chmod 600 ~/.ssh/authorized_keys
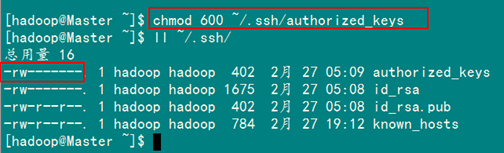
備注:如果不進(jìn)行設(shè)置,在驗(yàn)證時(shí),扔提示你輸入密碼,在這里花費(fèi)了將近半天時(shí)間來(lái)查找原因。在網(wǎng)上查到了幾篇不錯(cuò)的文章,把作為"Hadoop集群_第5期副刊_JDK和SSH無(wú)密碼配置"來(lái)幫助額外學(xué)習(xí)之用。
2)設(shè)置SSH配置
用root用戶(hù)登錄服務(wù)器修改SSH配置文件"/etc/ssh/sshd_config"的下列內(nèi)容。
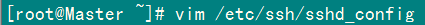
RSAAuthentication yes # 啟用 RSA 認(rèn)證
PubkeyAuthentication yes # 啟用公鑰私鑰配對(duì)認(rèn)證方式
AuthorizedKeysFile .ssh/authorized_keys # 公鑰文件路徑(和上面生成的文件同)
設(shè)置完之后記得重啟SSH服務(wù),才能使剛才設(shè)置有效。
service sshd restart
退出root登錄,使用hadoop普通用戶(hù)驗(yàn)證是否成功。
ssh localhost
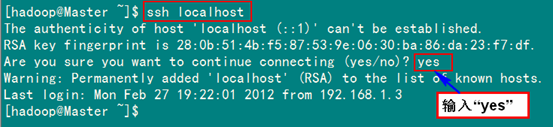
從上圖中得知無(wú)密碼登錄本級(jí)已經(jīng)設(shè)置完畢,接下來(lái)的事兒是把公鑰復(fù)制所有的Slave機(jī)器上。使用下面的命令格式進(jìn)行復(fù)制公鑰:
scp ~/.ssh/id_rsa.pub 遠(yuǎn)程用戶(hù)名@遠(yuǎn)程服務(wù)器IP:~/
例如:
scp ~/.ssh/id_rsa.pub hadoop@192.168.1.3:~/
上面的命令是復(fù)制文件"id_rsa.pub"到服務(wù)器IP為"192.168.1.3"的用戶(hù)為"hadoop"的"/home/hadoop/"下面。
下面就針對(duì)IP為"192.168.1.3"的Slave1.Hadoop的節(jié)點(diǎn)進(jìn)行配置。
1)把Master.Hadoop上的公鑰復(fù)制到Slave1.Hadoop上

從上圖中我們得知,已經(jīng)把文件"id_rsa.pub"傳過(guò)去了,因?yàn)椴](méi)有建立起無(wú)密碼連接,所以在連接時(shí),仍然要提示輸入輸入Slave1.Hadoop服務(wù)器用戶(hù)hadoop的密碼。為了確保確實(shí)已經(jīng)把文件傳過(guò)去了,用SecureCRT登錄Slave1.Hadoop:192.168.1.3服務(wù)器,查看"/home/hadoop/"下是否存在這個(gè)文件。

從上面得知我們已經(jīng)成功把公鑰復(fù)制過(guò)去了。
2)在"/home/hadoop/"下創(chuàng)建".ssh"文件夾
這一步并不是必須的,如果在Slave1.Hadoop的"/home/hadoop"已經(jīng)存在就不需要?jiǎng)?chuàng)建了,因?yàn)槲覀冎安](méi)有對(duì)Slave機(jī)器做過(guò)無(wú)密碼登錄配置,所以該文件是不存在的。用下面命令進(jìn)行創(chuàng)建。(備注:用hadoop登錄系統(tǒng),如果不涉及系統(tǒng)文件修改,一般情況下都是用我們之前建立的普通用戶(hù)hadoop進(jìn)行執(zhí)行命令。)
mkdir ~/.ssh
然后是修改文件夾".ssh"的用戶(hù)權(quán)限,把他的權(quán)限修改為"700",用下面命令執(zhí)行:
chmod 700 ~/.ssh
備注:如果不進(jìn)行,即使你按照前面的操作設(shè)置了"authorized_keys"權(quán)限,并配置了"/etc/ssh/sshd_config",還重啟了sshd服務(wù),在Master能用"ssh localhost"進(jìn)行無(wú)密碼登錄,但是對(duì)Slave1.Hadoop進(jìn)行登錄仍然需要輸入密碼,就是因?yàn)?quot;.ssh"文件夾的權(quán)限設(shè)置不對(duì)。這個(gè)文件夾".ssh"在配置SSH無(wú)密碼登錄時(shí)系統(tǒng)自動(dòng)生成時(shí),權(quán)限自動(dòng)為"700",如果是自己手動(dòng)創(chuàng)建,它的組權(quán)限和其他權(quán)限都有,這樣就會(huì)導(dǎo)致RSA無(wú)密碼遠(yuǎn)程登錄失敗。
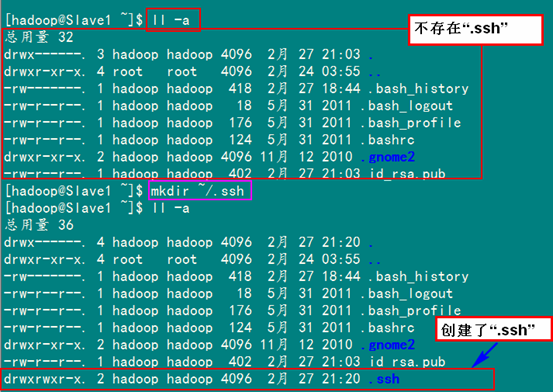

對(duì)比上面兩張圖,發(fā)現(xiàn)文件夾".ssh"權(quán)限已經(jīng)變了。
3)追加到授權(quán)文件"authorized_keys"
到目前為止Master.Hadoop的公鑰也有了,文件夾".ssh"也有了,且權(quán)限也修改了。這一步就是把Master.Hadoop的公鑰追加到Slave1.Hadoop的授權(quán)文件"authorized_keys"中去。使用下面命令進(jìn)行追加并修改"authorized_keys"文件權(quán)限:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys

4)用root用戶(hù)修改"/etc/ssh/sshd_config"
具體步驟參考前面Master.Hadoop的"設(shè)置SSH配置",具體分為兩步:第1是修改配置文件;第2是重啟SSH服務(wù)。
5)用Master.Hadoop使用SSH無(wú)密碼登錄Slave1.Hadoop
當(dāng)前面的步驟設(shè)置完畢,就可以使用下面命令格式進(jìn)行SSH無(wú)密碼登錄了。
ssh 遠(yuǎn)程服務(wù)器IP

從上圖我們主要3個(gè)地方,第1個(gè)就是SSH無(wú)密碼登錄命令,第2、3個(gè)就是登錄前后"@"后面的機(jī)器名變了,由"Master"變?yōu)榱?quot;Slave1",這就說(shuō)明我們已經(jīng)成功實(shí)現(xiàn)了SSH無(wú)密碼登錄了。
最后記得把"/home/hadoop/"目錄下的"id_rsa.pub"文件刪除掉。
rm –r ~/id_rsa.pub
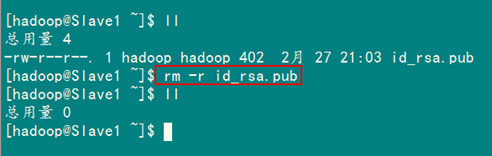
到此為止,我們經(jīng)過(guò)前5步已經(jīng)實(shí)現(xiàn)了從"Master.Hadoop"到"Slave1.Hadoop"SSH無(wú)密碼登錄,下面就是重復(fù)上面的步驟把剩余的兩臺(tái)(Slave2.Hadoop和Slave3.Hadoop)Slave服務(wù)器進(jìn)行配置。這樣,我們就完成了"配置Master無(wú)密碼登錄所有的Slave服務(wù)器"。
2.3 配置所有Slave無(wú)密碼登錄Master
和Master無(wú)密碼登錄所有Slave原理一樣,就是把Slave的公鑰追加到Master的".ssh"文件夾下的"authorized_keys"中,記得是追加(>>)。
為了說(shuō)明情況,我們現(xiàn)在就以"Slave1.Hadoop"無(wú)密碼登錄"Master.Hadoop"為例,進(jìn)行一遍操作,也算是鞏固一下前面所學(xué)知識(shí),剩余的"Slave2.Hadoop"和"Slave3.Hadoop"就按照這個(gè)示例進(jìn)行就可以了。
首先創(chuàng)建"Slave1.Hadoop"自己的公鑰和私鑰,并把自己的公鑰追加到"authorized_keys"文件中。用到的命令如下:
ssh-keygen –t rsa –P ''
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
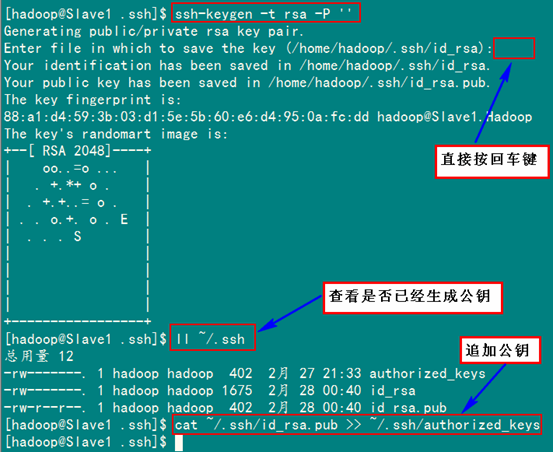
接著是用命令"scp"復(fù)制"Slave1.Hadoop"的公鑰"id_rsa.pub"到"Master.Hadoop"的"/home/hadoop/"目錄下,并追加到"Master.Hadoop"的"authorized_keys"中。
1)在"Slave1.Hadoop"服務(wù)器的操作
用到的命令如下:
scp ~/.ssh/id_rsa.pub hadoop@192.168.1.2:~/

2)在"Master.Hadoop"服務(wù)器的操作
用到的命令如下:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys

然后刪除掉剛才復(fù)制過(guò)來(lái)的"id_rsa.pub"文件。

最后是測(cè)試從"Slave1.Hadoop"到"Master.Hadoop"無(wú)密碼登錄。

從上面結(jié)果中可以看到已經(jīng)成功實(shí)現(xiàn)了,再試下從"Master.Hadoop"到"Slave1.Hadoop"無(wú)密碼登錄。

至此"Master.Hadoop"與"Slave1.Hadoop"之間可以互相無(wú)密碼登錄了,剩下的就是按照上面的步驟把剩余的"Slave2.Hadoop"和"Slave3.Hadoop"與"Master.Hadoop"之間建立起無(wú)密碼登錄。這樣,Master能無(wú)密碼驗(yàn)證登錄每個(gè)Slave,每個(gè)Slave也能無(wú)密碼驗(yàn)證登錄到Master。
3、Java環(huán)境安裝
所有的機(jī)器上都要安裝JDK,現(xiàn)在就先在Master服務(wù)器安裝,然后其他服務(wù)器按照步驟重復(fù)進(jìn)行即可。安裝JDK以及配置環(huán)境變量,需要以"root"的身份進(jìn)行。
3.1 安裝JDK
首先用root身份登錄"Master.Hadoop"后在"/usr"下創(chuàng)建"java"文件夾,再把用FTP上傳到"/home/hadoop/"下的"jdk-6u31-linux-i586.bin"復(fù)制到"/usr/java"文件夾中。
mkdir /usr/java
cp /home/hadoop/ jdk-6u31-linux-i586.bin /usr/java
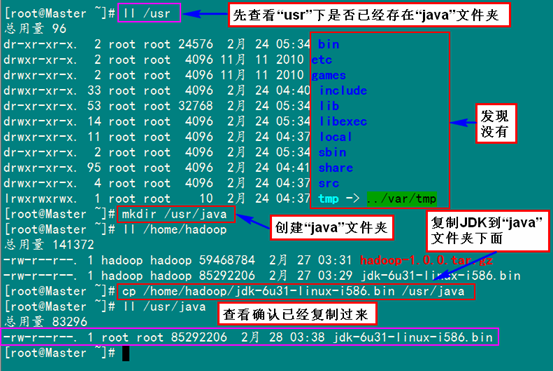
接著進(jìn)入"/usr/java"目錄下通過(guò)下面命令使其JDK獲得可執(zhí)行權(quán)限,并安裝JDK。
chmod +x jdk-6u31-linux-i586.bin
./jdk-6u31-linux-i586.bin

按照上面幾步進(jìn)行操作,最后點(diǎn)擊"Enter"鍵開(kāi)始安裝,安裝完會(huì)提示你按"Enter"鍵退出,然后查看"/usr/java"下面會(huì)發(fā)現(xiàn)多了一個(gè)名為"jdk1.6.0_31"文件夾,說(shuō)明我們的JDK安裝結(jié)束,刪除"jdk-6u31-linux-i586.bin"文件,進(jìn)入下一個(gè)"配置環(huán)境變量"環(huán)節(jié)。
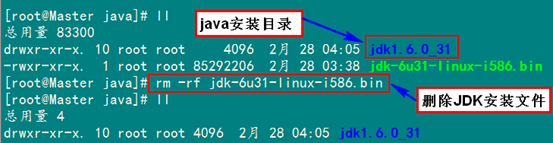
3.2 配置環(huán)境變量
編輯"/etc/profile"文件,在后面添加Java的"JAVA_HOME"、"CLASSPATH"以及"PATH"內(nèi)容。
1)編輯"/etc/profile"文件
vim /etc/profile

2)添加Java環(huán)境變量
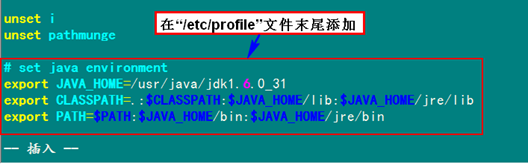
在"/etc/profile"文件的尾部添加以下內(nèi)容:
- # set java environment
- export JAVA_HOME=/usr/java/jdk1.6.0_31/
- export JRE_HOME=/usr/java/jdk1.6.0_31/jre
- export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
- export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
或者
- # set java environment
- export JAVA_HOME=/usr/java/jdk1.6.0_31
- export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
- export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
以上兩種意思一樣,那么我們就選擇第2種來(lái)進(jìn)行設(shè)置。
3)使配置生效
保存并退出,執(zhí)行下面命令使其配置立即生效。
source /etc/profile

3.3 驗(yàn)證安裝成功
配置完畢并生效后,用下面命令判斷是否成功。
java -version
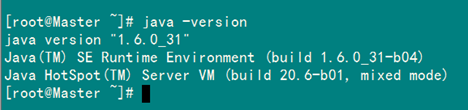
從上圖中得知,我們以確定JDK已經(jīng)安裝成功。
3.4 安裝剩余機(jī)器
這時(shí)用普通用戶(hù)hadoop通過(guò)下面命令格式把"Master.Hadoop"文件夾"/home/hadoop/"的JDK復(fù)制到其他Slave的"/home/hadoop/"下面,剩下的事兒就是在其余的Slave服務(wù)器上按照上圖的步驟安裝JDK。
scp /home/hadoop/jdk-6u31-linux-i586.bin 遠(yuǎn)程用戶(hù)名@遠(yuǎn)程服務(wù)器IP:~/
或者
scp ~/jdk-6u31-linux-i586.bin 遠(yuǎn)程用戶(hù)名@遠(yuǎn)程服務(wù)器IP:~/
備注:"~"代表當(dāng)前用戶(hù)的主目錄,當(dāng)前用戶(hù)為hadoop,所以"~"代表"/home/hadoop"。
例如:把JDK從"Master.Hadoop"復(fù)制到"Slave1.Hadoop"的命令如下。
scp ~/jdk-6u31-linux-i586 hadoop@192.168.1.3:~/

然后查看"Slave1.Hadoop"的"/home/hadoop"查看是否已經(jīng)復(fù)制成功了。

從上圖中得知,我們已經(jīng)成功復(fù)制了,現(xiàn)在我們就用最高權(quán)限用戶(hù)root進(jìn)行安裝了。其他的與這個(gè)一樣。
#p#
4、Hadoop集群安裝
所有的機(jī)器上都要安裝hadoop,現(xiàn)在就先在Master服務(wù)器安裝,然后其他服務(wù)器按照步驟重復(fù)進(jìn)行即可。安裝和配置hadoop需要以"root"的身份進(jìn)行。
4.1 安裝hadoop
首先用root用戶(hù)登錄"Master.Hadoop"機(jī)器,查看我們之前用FTP上傳至"/home/Hadoop"上傳的"hadoop-1.0.0.tar.gz"。
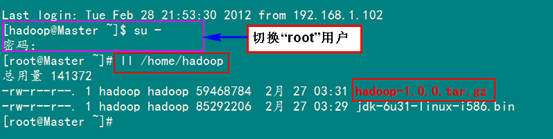
接著把"hadoop-1.0.0.tar.gz"復(fù)制到"/usr"目錄下面。
cp /home/hadoop/hadoop-1.0.0.tar.gz /usr
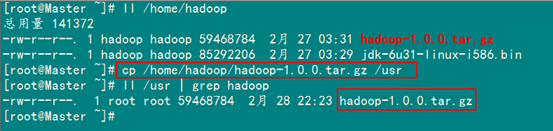
下一步進(jìn)入"/usr"目錄下,用下面命令把"hadoop-1.0.0.tar.gz"進(jìn)行解壓,并將其命名為"hadoop",把該文件夾的讀權(quán)限分配給普通用戶(hù)hadoop,然后刪除"hadoop-1.0.0.tar.gz"安裝包。
cd /usr #進(jìn)入"/usr"目錄
tar –zxvf hadoop-1.0.0.tar.gz #解壓"hadoop-1.0.0.tar.gz"安裝包
mv hadoop-1.0.0 hadoop #將"hadoop-1.0.0"文件夾重命名"hadoop"
chown –R hadoop:hadoop hadoop #將文件夾"hadoop"讀權(quán)限分配給hadoop用戶(hù)
rm –rf hadoop-1.0.0.tar.gz #刪除"hadoop-1.0.0.tar.gz"安裝包
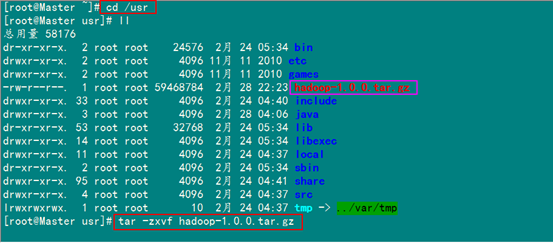
解壓后,并重命名。
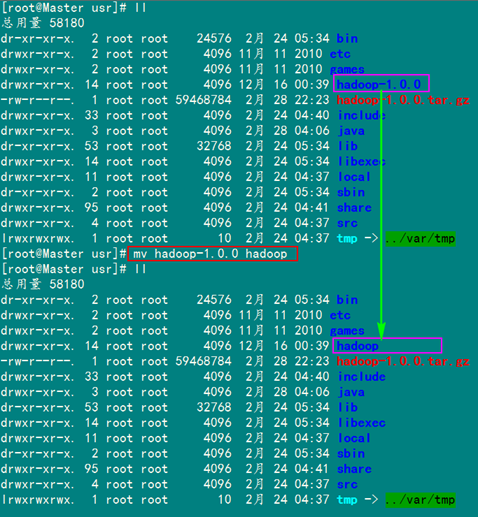
把"/usr/hadoop"讀權(quán)限分配給hadoop用戶(hù)(非常重要)

刪除"hadoop-1.0.0.tar.gz"安裝包

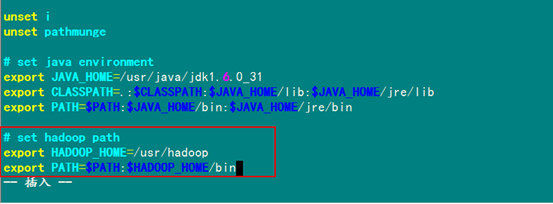
最后在"/usr/hadoop"下面創(chuàng)建tmp文件夾,把Hadoop的安裝路徑添加到"/etc/profile"中,修改"/etc/profile"文件(配置java環(huán)境變量的文件),將以下語(yǔ)句添加到末尾,并使其有效:
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH :$HADOOP_HOME/bin
1)在"/usr/hadoop"創(chuàng)建"tmp"文件夾
mkdir /usr/hadoop/tmp

2)配置"/etc/profile"
vim /etc/profile

配置后的文件如下:
3)重啟"/etc/profile"
source /etc/profile

4.2 配置hadoop
1)配置hadoop-env.sh
該"hadoop-env.sh"文件位于"/usr/hadoop/conf"目錄下。

在文件的末尾添加下面內(nèi)容。
# set java environment
export JAVA_HOME=/usr/java/jdk1.6.0_31

Hadoop配置文件在conf目錄下,之前的版本的配置文件主要是Hadoop-default.xml和Hadoop-site.xml。由于Hadoop發(fā)展迅速,代碼量急劇增加,代碼開(kāi)發(fā)分為了core,hdfs和map/reduce三部分,配置文件也被分成了三個(gè)core-site.xml、hdfs-site.xml、mapred-site.xml。core-site.xml和hdfs-site.xml是站在HDFS角度上配置文件;core-site.xml和mapred-site.xml是站在MapReduce角度上配置文件。
2)配置core-site.xml文件
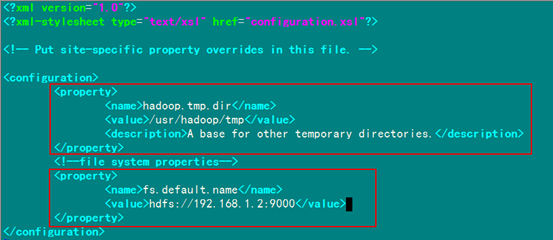
修改Hadoop核心配置文件core-site.xml,這里配置的是HDFS的地址和端口號(hào)。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
(備注:請(qǐng)先在 /usr/hadoop 目錄下建立 tmp 文件夾)
- <description>A base for other temporary directories.</description>
- </property>
- <!-- file system properties -->
- <property>
- <name>fs.default.name</name>
- <value>hdfs://192.168.1.2:9000</value>
- </property>
- </configuration>
備注:如沒(méi)有配置hadoop.tmp.dir參數(shù),此時(shí)系統(tǒng)默認(rèn)的臨時(shí)目錄為:/tmp/hadoo-hadoop。而這個(gè)目錄在每次重啟后都會(huì)被干掉,必須重新執(zhí)行format才行,否則會(huì)出錯(cuò)。
用下面命令進(jìn)行編輯:

編輯結(jié)果顯示如下:
3)配置hdfs-site.xml文件
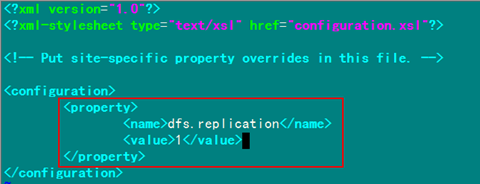
修改Hadoop中HDFS的配置,配置的備份方式默認(rèn)為3。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
(備注:replication 是數(shù)據(jù)副本數(shù)量,默認(rèn)為3,salve少于3臺(tái)就會(huì)報(bào)錯(cuò))
</property>
<configuration>
用下面命令進(jìn)行編輯:

編輯結(jié)果顯示如下:
4)配置mapred-site.xml文件
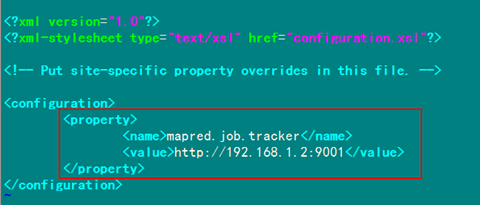
修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口。
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>http://192.168.1.2:9001</value>
- </property>
- </configuration>
用下面命令進(jìn)行編輯:

編輯結(jié)果顯示如下:
5)配置masters文件
有兩種方案:
(1)第一種
修改localhost為Master.Hadoop
(2)第二種
去掉"localhost",加入Master機(jī)器的IP:192.168.1.2
為保險(xiǎn)起見(jiàn),啟用第二種,因?yàn)槿f(wàn)一忘記配置"/etc/hosts"局域網(wǎng)的DNS失效,這樣就會(huì)出現(xiàn)意想不到的錯(cuò)誤,但是一旦IP配對(duì),網(wǎng)絡(luò)暢通,就能通過(guò)IP找到相應(yīng)主機(jī)。
用下面命令進(jìn)行修改:

編輯結(jié)果顯示如下:

6)配置slaves文件(Master主機(jī)特有)
有兩種方案:
(1)第一種
去掉"localhost",每行只添加一個(gè)主機(jī)名,把剩余的Slave主機(jī)名都填上。
例如:添加形式如下
Slave1.Hadoop
Slave2.Hadoop
Slave3.Hadoop
(2)第二種
去掉"localhost",加入集群中所有Slave機(jī)器的IP,也是每行一個(gè)。
例如:添加形式如下
192.168.1.3
192.168.1.4
192.168.1.5
原因和添加"masters"文件一樣,選擇第二種方式。
用下面命令進(jìn)行修改:

編輯結(jié)果如下:

現(xiàn)在在Master機(jī)器上的Hadoop配置就結(jié)束了,剩下的就是配置Slave機(jī)器上的Hadoop。
一種方式是按照上面的步驟,把Hadoop的安裝包在用普通用戶(hù)hadoop通過(guò)"scp"復(fù)制到其他機(jī)器的"/home/hadoop"目錄下,然后根據(jù)實(shí)際情況進(jìn)行安裝配置,除了第6步,那是Master特有的。用下面命令格式進(jìn)行。(備注:此時(shí)切換到普通用戶(hù)hadoop)
scp ~/hadoop-1.0.0.tar.gz hadoop@服務(wù)器IP:~/
例如:從"Master.Hadoop"到"Slave1.Hadoop"復(fù)制Hadoop的安裝包。
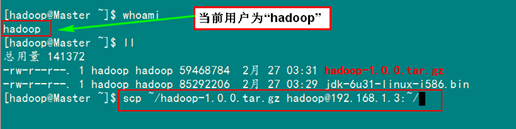
另一種方式是將 Master上配置好的hadoop所在文件夾"/usr/hadoop"復(fù)制到所有的Slave的"/usr"目錄下(實(shí)際上Slave機(jī)器上的slavers文件是不必要的, 復(fù)制了也沒(méi)問(wèn)題)。用下面命令格式進(jìn)行。(備注:此時(shí)用戶(hù)可以為hadoop也可以為root)
scp -r /usr/hadoop root@服務(wù)器IP:/usr/
例如:從"Master.Hadoop"到"Slave1.Hadoop"復(fù)制配置Hadoop的文件。
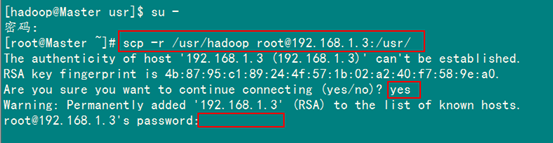
上圖中以root用戶(hù)進(jìn)行復(fù)制,當(dāng)然不管是用戶(hù)root還是hadoop,雖然Master機(jī)器上的"/usr/hadoop"文件夾用戶(hù)hadoop有權(quán)限,但是Slave1上的hadoop用戶(hù)卻沒(méi)有"/usr"權(quán)限,所以沒(méi)有創(chuàng)建文件夾的權(quán)限。所以無(wú)論是哪個(gè)用戶(hù)進(jìn)行拷貝,右面都是"root@機(jī)器IP"格式。因?yàn)槲覀冎皇墙⑵鹆薶adoop用戶(hù)的SSH無(wú)密碼連接,所以用root進(jìn)行"scp"時(shí),扔提示讓你輸入"Slave1.Hadoop"服務(wù)器用戶(hù)root的密碼。
查看"Slave1.Hadoop"服務(wù)器的"/usr"目錄下是否已經(jīng)存在"hadoop"文件夾,確認(rèn)已經(jīng)復(fù)制成功。查看結(jié)果如下:
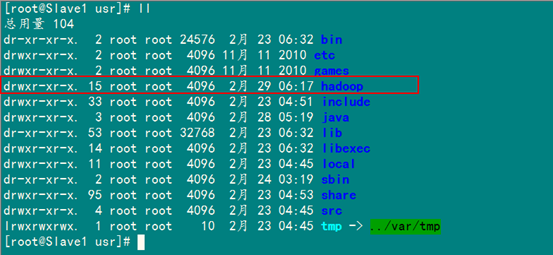
從上圖中知道,hadoop文件夾確實(shí)已經(jīng)復(fù)制了,但是我們發(fā)現(xiàn)hadoop權(quán)限是root,所以我們現(xiàn)在要給"Slave1.Hadoop"服務(wù)器上的用戶(hù)hadoop添加對(duì)"/usr/hadoop"讀權(quán)限。
以root用戶(hù)登錄"Slave1.Hadoop",執(zhí)行下面命令。
chown -R hadoop:hadoop(用戶(hù)名:用戶(hù)組) hadoop(文件夾)
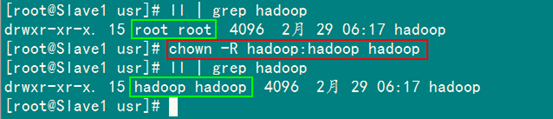
接著在"Slave1 .Hadoop"上修改"/etc/profile"文件(配置 java 環(huán)境變量的文件),將以下語(yǔ)句添加到末尾,并使其有效(source /etc/profile):
# set hadoop environment
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH :$HADOOP_HOME/bin
如果不知道怎么設(shè)置,可以查看前面"Master.Hadoop"機(jī)器的"/etc/profile"文件的配置,到此為此在一臺(tái)Slave機(jī)器上的Hadoop配置就結(jié)束了。剩下的事兒就是照葫蘆畫(huà)瓢把剩余的幾臺(tái)Slave機(jī)器按照《從"Master.Hadoop"到"Slave1.Hadoop"復(fù)制Hadoop的安裝包。》這個(gè)例子進(jìn)行部署Hadoop。
4.3 啟動(dòng)及驗(yàn)證
1)格式化HDFS文件系統(tǒng)
在"Master.Hadoop"上使用普通用戶(hù)hadoop進(jìn)行操作。(備注:只需一次,下次啟動(dòng)不再需要格式化,只需 start-all.sh)
hadoop namenode -format
某些書(shū)上和網(wǎng)上的某些資料中用下面命令執(zhí)行。

我們?cè)诳春枚辔臋n包括有些書(shū)上,按照他們的hadoop環(huán)境變量進(jìn)行配置后,并立即使其生效,但是執(zhí)行發(fā)現(xiàn)沒(méi)有找見(jiàn)"bin/hadoop"這個(gè)命令。

其實(shí)我們會(huì)發(fā)現(xiàn)我們的環(huán)境變量配置的是"$HADOOP_HOME/bin",我們已經(jīng)把bin包含進(jìn)入了,所以執(zhí)行時(shí),加上"bin"反而找不到該命令,除非我們的hadoop壞境變量如下設(shè)置。
# set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH : $HADOOP_HOME :$HADOOP_HOME/bin
這樣就能直接使用"bin/hadoop"也可以直接使用"hadoop",現(xiàn)在不管哪種情況,hadoop命令都能找見(jiàn)了。我們也沒(méi)有必要重新在設(shè)置hadoop環(huán)境變量了,只需要記住執(zhí)行Hadoop命令時(shí)不需要在前面加"bin"就可以了。

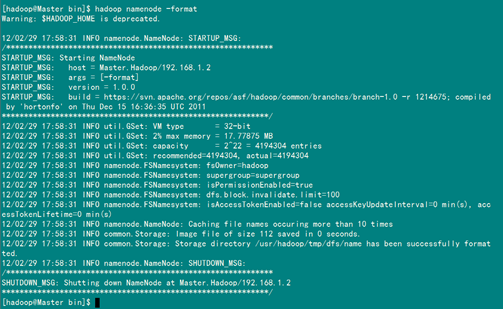
從上圖中知道我們已經(jīng)成功格式話(huà)了,但是美中不足就是出現(xiàn)了一個(gè)警告,從網(wǎng)上的得知這個(gè)警告并不影響hadoop執(zhí)行,但是也有辦法解決,詳情看后面的"常見(jiàn)問(wèn)題FAQ"。
2)啟動(dòng)hadoop
在啟動(dòng)前關(guān)閉集群中所有機(jī)器的防火墻,不然會(huì)出現(xiàn)datanode開(kāi)后又自動(dòng)關(guān)閉。
service iptables stop
使用下面命令啟動(dòng)。
start-all.sh

執(zhí)行結(jié)果如下:

可以通過(guò)以下啟動(dòng)日志看出,首先啟動(dòng)namenode 接著啟動(dòng)datanode1,datanode2,…,然后啟動(dòng)secondarynamenode。再啟動(dòng)jobtracker,然后啟動(dòng)tasktracker1,tasktracker2,…。
啟動(dòng) hadoop成功后,在 Master 中的 tmp 文件夾中生成了 dfs 文件夾,在Slave 中的 tmp 文件夾中均生成了 dfs 文件夾和 mapred 文件夾。
查看Master中"/usr/hadoop/tmp"文件夾內(nèi)容

查看Slave1中"/usr/hadoop/tmp"文件夾內(nèi)容。

3)驗(yàn)證hadoop
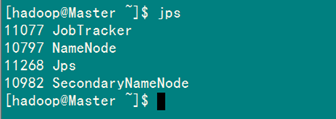
(1)驗(yàn)證方法一:用"jps"命令
在Master上用 java自帶的小工具jps查看進(jìn)程。
在Slave1上用jps查看進(jìn)程。
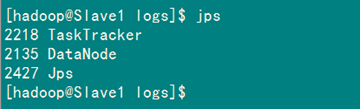
如果在查看Slave機(jī)器中發(fā)現(xiàn)"DataNode"和"TaskTracker"沒(méi)有起來(lái)時(shí),先查看一下日志的,如果是"namespaceID"不一致問(wèn)題,采用"常見(jiàn)問(wèn)題FAQ6.2"進(jìn)行解決,如果是"No route to host"問(wèn)題,采用"常見(jiàn)問(wèn)題FAQ6.3"進(jìn)行解決。
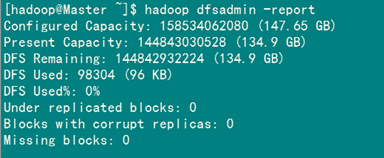
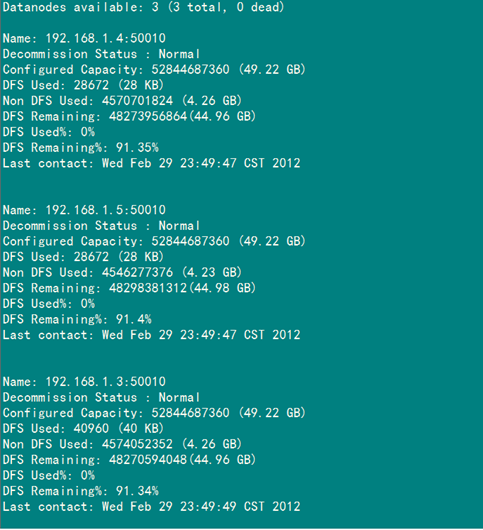
(2)驗(yàn)證方式二:用"hadoop dfsadmin -report"
用這個(gè)命令可以查看Hadoop集群的狀態(tài)。
Master服務(wù)器的狀態(tài):
Slave服務(wù)器的狀態(tài)
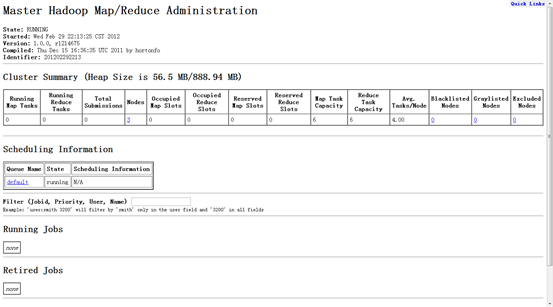
4.4 網(wǎng)頁(yè)查看集群
1)訪(fǎng)問(wèn)"http:192.168.1.2:50030"
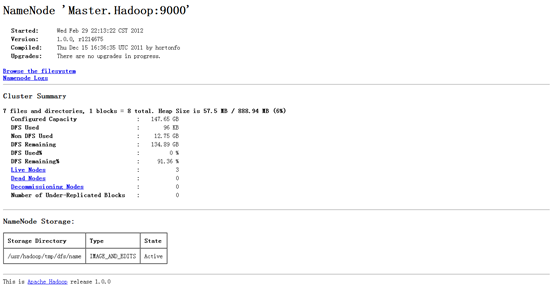
2)訪(fǎng)問(wèn)"http:192.168.1.2:50070"
5、常見(jiàn)問(wèn)題FAQ
5.1 關(guān)于 Warning: $HADOOP_HOME is deprecated.
hadoop 1.0.0版本,安裝完之后敲入hadoop命令時(shí),老是提示這個(gè)警告:
Warning: $HADOOP_HOME is deprecated.
經(jīng)查hadoop-1.0.0/bin/hadoop腳本和"hadoop-config.sh"腳本,發(fā)現(xiàn)腳本中對(duì)HADOOP_HOME的環(huán)境變量設(shè)置做了判斷,筆者的環(huán)境根本不需要設(shè)置HADOOP_HOME環(huán)境變量。
解決方案一:編輯"/etc/profile"文件,去掉HADOOP_HOME的變量設(shè)定,重新輸入hadoop fs命令,警告消失。
解決方案二:編輯"/etc/profile"文件,添加一個(gè)環(huán)境變量,之后警告消失:
export HADOOP_HOME_WARN_SUPPRESS=1
解決方案三:編輯"hadoop-config.sh"文件,把下面的"if - fi"功能注釋掉。

我們這里本著不動(dòng)Hadoop原配置文件的前提下,采用"方案二",在"/etc/profile"文件添加上面內(nèi)容,并用命令"source /etc/profile"使之有效。
1)切換至root用戶(hù)

2)添加內(nèi)容
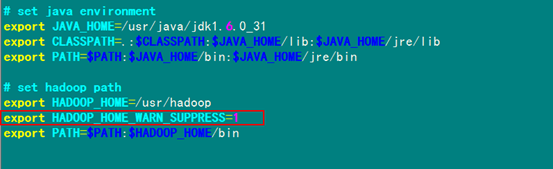
3)重新生效

5.2 解決"no datanode to stop"問(wèn)題
當(dāng)我停止Hadoop時(shí)發(fā)現(xiàn)如下信息:
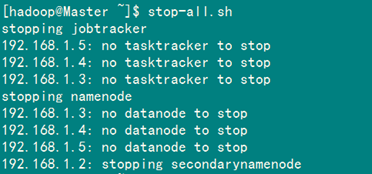
原因:每次namenode format會(huì)重新創(chuàng)建一個(gè)namenodeId,而tmp/dfs/data下包含了上次format下的id,namenode format清空了namenode下的數(shù)據(jù),但是沒(méi)有清空datanode下的數(shù)據(jù),導(dǎo)致啟動(dòng)時(shí)失敗,所要做的就是每次fotmat前,清空tmp一下的所有目錄。
第一種解決方案如下:
1)先刪除"/usr/hadoop/tmp"
rm -rf /usr/hadoop/tmp
2)創(chuàng)建"/usr/hadoop/tmp"文件夾
mkdir /usr/hadoop/tmp
3)刪除"/tmp"下以"hadoop"開(kāi)頭文件
rm -rf /tmp/hadoop*
4)重新格式化hadoop
hadoop namenode -format
5)啟動(dòng)hadoop
start-all.sh
使用第一種方案,有種不好處就是原來(lái)集群上的重要數(shù)據(jù)全沒(méi)有了。假如說(shuō)Hadoop集群已經(jīng)運(yùn)行了一段時(shí)間。建議采用第二種。
第二種方案如下:
1)修改每個(gè)Slave的namespaceID使其與Master的namespaceID一致。
或者
2)修改Master的namespaceID使其與Slave的namespaceID一致。
該"namespaceID"位于"/usr/hadoop/tmp/dfs/data/current/VERSION"文件中,前面藍(lán)色的可能根據(jù)實(shí)際情況變化,但后面紅色是不變的。
例如:查看"Master"下的"VERSION"文件
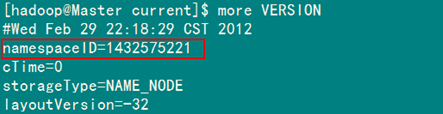
本人建議采用第二種,這樣方便快捷,而且還能防止誤刪。
5.3 Slave服務(wù)器中datanode啟動(dòng)后又自動(dòng)關(guān)閉
查看日志發(fā)下如下錯(cuò)誤。
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Call to ... failed on local exception: java.net.NoRouteToHostException: No route to host
解決方案是:關(guān)閉防火墻
service iptables stop
5.4 從本地往hdfs文件系統(tǒng)上傳文件
出現(xiàn)如下錯(cuò)誤:
INFO hdfs.DFSClient: Exception in createBlockOutputStream java.io.IOException: Bad connect ack with firstBadLink
INFO hdfs.DFSClient: Abandoning block blk_-1300529705803292651_37023
WARN hdfs.DFSClient: DataStreamer Exception: java.io.IOException: Unable to create new block.
解決方案是:
1)關(guān)閉防火墻
service iptables stop
2)禁用selinux
編輯 "/etc/selinux/config"文件,設(shè)置"SELINUX=disabled"
5.5 安全模式導(dǎo)致的錯(cuò)誤
出現(xiàn)如下錯(cuò)誤:
org.apache.hadoop.dfs.SafeModeException: Cannot delete ..., Name node is in safe mode
在分布式文件系統(tǒng)啟動(dòng)的時(shí)候,開(kāi)始的時(shí)候會(huì)有安全模式,當(dāng)分布式文件系統(tǒng)處于安全模式的情況下,文件系統(tǒng)中的內(nèi)容不允許修改也不允許刪除,直到安全模式結(jié)束。安全模式主要是為了系統(tǒng)啟動(dòng)的時(shí)候檢查各個(gè)DataNode上數(shù)據(jù)塊的有效性,同時(shí)根據(jù)策略必要的復(fù)制或者刪除部分?jǐn)?shù)據(jù)塊。運(yùn)行期通過(guò)命令也可以進(jìn)入安全模式。在實(shí)踐過(guò)程中,系統(tǒng)啟動(dòng)的時(shí)候去修改和刪除文件也會(huì)有安全模式不允許修改的出錯(cuò)提示,只需要等待一會(huì)兒即可。
解決方案是:關(guān)閉安全模式
hadoop dfsadmin -safemode leave
5.6 解決Exceeded MAX_FAILED_UNIQUE_FETCHES
出現(xiàn)錯(cuò)誤如下:
Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out
程序里面需要打開(kāi)多個(gè)文件,進(jìn)行分析,系統(tǒng)一般默認(rèn)數(shù)量是1024,(用ulimit -a可以看到)對(duì)于正常使用是夠了,但是對(duì)于程序來(lái)講,就太少了。
解決方案是:修改2個(gè)文件。
1)"/etc/security/limits.conf"
vim /etc/security/limits.conf
加上:
soft nofile 102400
hard nofile 409600
2)"/etc/pam.d/login"
vim /etc/pam.d/login
添加:
session required /lib/security/pam_limits.so
針對(duì)第一個(gè)問(wèn)題我糾正下答案:
這是reduce預(yù)處理階段shuffle時(shí)獲取已完成的map的輸出失敗次數(shù)超過(guò)上限造成的,上限默認(rèn)為5。引起此問(wèn)題的方式可能會(huì)有很多種,比如網(wǎng)絡(luò)連接不正常,連接超時(shí),帶寬較差以及端口阻塞等。通常框架內(nèi)網(wǎng)絡(luò)情況較好是不會(huì)出現(xiàn)此錯(cuò)誤的。
5.7 解決"Too many fetch-failures"
出現(xiàn)這個(gè)問(wèn)題主要是結(jié)點(diǎn)間的連通不夠全面。
解決方案是:
1)檢查"/etc/hosts"
要求本機(jī)ip 對(duì)應(yīng) 服務(wù)器名
要求要包含所有的服務(wù)器ip +服務(wù)器名
2)檢查".ssh/authorized_keys"
要求包含所有服務(wù)器(包括其自身)的public key
5.8 處理速度特別的慢
出現(xiàn)map很快,但是reduce很慢,而且反復(fù)出現(xiàn)"reduce=0%"。
解決方案如下:
結(jié)合解決方案5.7,然后修改"conf/hadoop-env.sh"中的"export HADOOP_HEAPSIZE=4000"
5.9解決hadoop OutOfMemoryError問(wèn)題
出現(xiàn)這種異常,明顯是jvm內(nèi)存不夠得原因。
解決方案如下:要修改所有的datanode的jvm內(nèi)存大小。
Java –Xms 1024m -Xmx 4096m
一般jvm的最大內(nèi)存使用應(yīng)該為總內(nèi)存大小的一半,我們使用的8G內(nèi)存,所以設(shè)置為4096m,這一值可能依舊不是最優(yōu)的值。
5.10 Namenode in safe mode
解決方案如下:
bin/hadoop dfsadmin -safemode leave
5.11 IO寫(xiě)操作出現(xiàn)問(wèn)題
0-1246359584298, infoPort=50075, ipcPort=50020):Got exception while serving blk_-5911099437886836280_1292 to /172.16.100.165:
java.net.SocketTimeoutException: 480000 millis timeout while waiting for channel to be ready for write. ch : java.nio.channels.SocketChannel[connected local=/
172.16.100.165:50010 remote=/172.16.100.165:50930]
at org.apache.hadoop.net.SocketIOWithTimeout.waitForIO(SocketIOWithTimeout.java:185)
at org.apache.hadoop.net.SocketOutputStream.waitForWritable(SocketOutputStream.java:159)
……
It seems there are many reasons that it can timeout, the example given in HADOOP-3831 is a slow reading client.
解決方案如下:
在hadoop-site.xml中設(shè)置dfs.datanode.socket.write.timeout=0
5.12 status of 255 error
錯(cuò)誤類(lèi)型:
java.io.IOException: Task process exit with nonzero status of 255.
at org.apache.hadoop.mapred.TaskRunner.run(TaskRunner.java:424)
錯(cuò)誤原因:
Set mapred.jobtracker.retirejob.interval and mapred.userlog.retain.hours to higher value. By default, their values are 24 hours. These might be the reason for failure, though I'm not sure restart.
解決方案如下:?jiǎn)蝹€(gè)datanode
如果一個(gè)datanode 出現(xiàn)問(wèn)題,解決之后需要重新加入cluster而不重啟cluster,方法如下:
bin/hadoop-daemon.sh start datanode
bin/hadoop-daemon.sh start jobtracker
6、用到的Linux命令
6.1 chmod命令詳解
使用權(quán)限:所有使用者
使用方式:chmod [-cfvR] [--help] [--version] mode file...
說(shuō)明:
Linux/Unix 的檔案存取權(quán)限分為三級(jí) : 檔案擁有者、群組、其他。利用 chmod 可以藉以控制檔案如何被他人所存取。
mode :權(quán)限設(shè)定字串,格式如下 :[ugoa...][[+-=][rwxX]...][,...],其中u 表示該檔案的擁有者,g 表示與該檔案的擁有者屬于同一個(gè)群體(group)者,o 表示其他以外的人,a 表示這三者皆是。
+ 表示增加權(quán)限、- 表示取消權(quán)限、= 表示唯一設(shè)定權(quán)限。
r 表示可讀取,w 表示可寫(xiě)入,x 表示可執(zhí)行,X 表示只有當(dāng)該檔案是個(gè)子目錄或者該檔案已經(jīng)被設(shè)定過(guò)為可執(zhí)行。
-c : 若該檔案權(quán)限確實(shí)已經(jīng)更改,才顯示其更改動(dòng)作
-f : 若該檔案權(quán)限無(wú)法被更改也不要顯示錯(cuò)誤訊息
-v : 顯示權(quán)限變更的詳細(xì)資料
-R : 對(duì)目前目錄下的所有檔案與子目錄進(jìn)行相同的權(quán)限變更(即以遞回的方式逐個(gè)變更)
--help : 顯示輔助說(shuō)明
--version : 顯示版本
范例:
將檔案 file1.txt 設(shè)為所有人皆可讀取
chmod ugo+r file1.txt
將檔案 file1.txt 設(shè)為所有人皆可讀取
chmod a+r file1.txt
將檔案 file1.txt 與 file2.txt 設(shè)為該檔案擁有者,與其所屬同一個(gè)群體者可寫(xiě)入,但其他以外的人則不可寫(xiě)入
chmod ug+w,o-w file1.txt file2.txt
將 ex1.py 設(shè)定為只有該檔案擁有者可以執(zhí)行
chmod u+x ex1.py
將目前目錄下的所有檔案與子目錄皆設(shè)為任何人可讀取
chmod -R a+r *
此外chmod也可以用數(shù)字來(lái)表示權(quán)限如 chmod 777 file
語(yǔ)法為:chmod abc file
其中a,b,c各為一個(gè)數(shù)字,分別表示User、Group、及Other的權(quán)限。
r=4,w=2,x=1
若要rwx屬性則4+2+1=7;
若要rw-屬性則4+2=6;
若要r-x屬性則4+1=7。
范例:
chmod a=rwx file 和 chmod 777 file 效果相同
chmod ug=rwx,o=x file 和 chmod 771 file 效果相同
若用chmod 4755 filename可使此程式具有root的權(quán)限
6.2 chown命令詳解
使用權(quán)限:root
使用方式:chown [-cfhvR] [--help] [--version] user[:group] file...
說(shuō)明:
Linux/Unix 是多人多工作業(yè)系統(tǒng),所有的檔案皆有擁有者。利用 chown 可以將檔案的擁有者加以改變。一般來(lái)說(shuō),這個(gè)指令只有是由系統(tǒng)管理者(root)所使用,一般使用者沒(méi)有權(quán)限可以改變別人的檔案擁有者,也沒(méi)有權(quán)限可以自己的檔案擁有者改設(shè)為別人。只有系統(tǒng)管理者(root)才有這樣的權(quán)限。
user : 新的檔案擁有者的使用者
IDgroup : 新的檔案擁有者的使用者群體(group)
-c : 若該檔案擁有者確實(shí)已經(jīng)更改,才顯示其更改動(dòng)作
-f : 若該檔案擁有者無(wú)法被更改也不要顯示錯(cuò)誤訊息
-h : 只對(duì)于連結(jié)(link)進(jìn)行變更,而非該 link 真正指向的檔案
-v : 顯示擁有者變更的詳細(xì)資料
-R : 對(duì)目前目錄下的所有檔案與子目錄進(jìn)行相同的擁有者變更(即以遞回的方式逐個(gè)變更)
--help : 顯示輔助說(shuō)明
--version : 顯示版本
范例:
將檔案 file1.txt 的擁有者設(shè)為 users 群體的使用者 jessie
chown jessie:users file1.txt
將目前目錄下的所有檔案與子目錄的擁有者皆設(shè)為 users 群體的使用者 lamport
chown -R lamport:users *
-rw------- (600) -- 只有屬主有讀寫(xiě)權(quán)限。
-rw-r--r-- (644) -- 只有屬主有讀寫(xiě)權(quán)限;而屬組用戶(hù)和其他用戶(hù)只有讀權(quán)限。
-rwx------ (700) -- 只有屬主有讀、寫(xiě)、執(zhí)行權(quán)限。
-rwxr-xr-x (755) -- 屬主有讀、寫(xiě)、執(zhí)行權(quán)限;而屬組用戶(hù)和其他用戶(hù)只有讀、執(zhí)行權(quán)限。
-rwx--x--x (711) -- 屬主有讀、寫(xiě)、執(zhí)行權(quán)限;而屬組用戶(hù)和其他用戶(hù)只有執(zhí)行權(quán)限。
-rw-rw-rw- (666) -- 所有用戶(hù)都有文件讀、寫(xiě)權(quán)限。這種做法不可取。
-rwxrwxrwx (777) -- 所有用戶(hù)都有讀、寫(xiě)、執(zhí)行權(quán)限。更不可取的做法。
以下是對(duì)目錄的兩個(gè)普通設(shè)定:
drwx------ (700) - 只有屬主可在目錄中讀、寫(xiě)。
drwxr-xr-x (755) - 所有用戶(hù)可讀該目錄,但只有屬主才能改變目錄中的內(nèi)容
suid的代表數(shù)字是4,比如4755的結(jié)果是-rwsr-xr-x
sgid的代表數(shù)字是2,比如6755的結(jié)果是-rwsr-sr-x
sticky位代表數(shù)字是1,比如7755的結(jié)果是-rwsr-sr-t
6.3 scp命令詳解
scp是 secure copy的縮寫(xiě),scp是linux系統(tǒng)下基于ssh登陸進(jìn)行安全的遠(yuǎn)程文件拷貝命令。linux的scp命令可以在linux服務(wù)器之間復(fù)制文件和目錄。
scp命令的用處:
scp在網(wǎng)絡(luò)上不同的主機(jī)之間復(fù)制文件,它使用ssh安全協(xié)議傳輸數(shù)據(jù),具有和ssh一樣的驗(yàn)證機(jī)制,從而安全的遠(yuǎn)程拷貝文件。
scp命令基本格式:
scp [-1246BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file]
[-l limit] [-o ssh_option] [-P port] [-S program]
[[user@]host1:]file1 [...] [[user@]host2:]file2
scp命令的參數(shù)說(shuō)明:
-1 強(qiáng)制scp命令使用協(xié)議ssh1
-2 強(qiáng)制scp命令使用協(xié)議ssh2
-4 強(qiáng)制scp命令只使用IPv4尋址
-6 強(qiáng)制scp命令只使用IPv6尋址
-B 使用批處理模式(傳輸過(guò)程中不詢(xún)問(wèn)傳輸口令或短語(yǔ))
-C 允許壓縮。(將-C標(biāo)志傳遞給ssh,從而打開(kāi)壓縮功能)
-p 保留原文件的修改時(shí)間,訪(fǎng)問(wèn)時(shí)間和訪(fǎng)問(wèn)權(quán)限。
-q 不顯示傳輸進(jìn)度條。
-r 遞歸復(fù)制整個(gè)目錄。
-v 詳細(xì)方式顯示輸出。scp和ssh(1)會(huì)顯示出整個(gè)過(guò)程的調(diào)試信息。這些信息用于調(diào)試連接,驗(yàn)證和配置問(wèn)題。
-c cipher 以cipher將數(shù)據(jù)傳輸進(jìn)行加密,這個(gè)選項(xiàng)將直接傳遞給ssh。
-F ssh_config 指定一個(gè)替代的ssh配置文件,此參數(shù)直接傳遞給ssh。
-i identity_file 從指定文件中讀取傳輸時(shí)使用的密鑰文件,此參數(shù)直接傳遞給ssh。
-l limit 限定用戶(hù)所能使用的帶寬,以Kbit/s為單位。
-o ssh_option 如果習(xí)慣于使用ssh_config(5)中的參數(shù)傳遞方式,
-P port 注意是大寫(xiě)的P, port是指定數(shù)據(jù)傳輸用到的端口號(hào)
-S program 指定加密傳輸時(shí)所使用的程序。此程序必須能夠理解ssh(1)的選項(xiàng)。
scp命令的實(shí)際應(yīng)用
1)從本地服務(wù)器復(fù)制到遠(yuǎn)程服務(wù)器
(1) 復(fù)制文件:
命令格式:
scp local_file remote_username@remote_ip:remote_folder
或者
scp local_file remote_username@remote_ip:remote_file
或者
scp local_file remote_ip:remote_folder
或者
scp local_file remote_ip:remote_file
第1,2個(gè)指定了用戶(hù)名,命令執(zhí)行后需要輸入用戶(hù)密碼,第1個(gè)僅指定了遠(yuǎn)程的目錄,文件名字不變,第2個(gè)指定了文件名
第3,4個(gè)沒(méi)有指定用戶(hù)名,命令執(zhí)行后需要輸入用戶(hù)名和密碼,第3個(gè)僅指定了遠(yuǎn)程的目錄,文件名字不變,第4個(gè)指定了文件名
實(shí)例:
scp /home/linux/soft/scp.zip root@www.mydomain.com:/home/linux/others/soft
scp /home/linux/soft/scp.zip root@www.mydomain.com:/home/linux/others/soft/scp2.zip
scp /home/linux/soft/scp.zip www.mydomain.com:/home/linux/others/soft
scp /home/linux/soft/scp.zip www.mydomain.com:/home/linux/others/soft/scp2.zip
(2) 復(fù)制目錄:
命令格式:
scp -r local_folder remote_username@remote_ip:remote_folder
或者
scp -r local_folder remote_ip:remote_folder
第1個(gè)指定了用戶(hù)名,命令執(zhí)行后需要輸入用戶(hù)密碼;
第2個(gè)沒(méi)有指定用戶(hù)名,命令執(zhí)行后需要輸入用戶(hù)名和密碼;
例子:
scp -r /home/linux/soft/ root@www.mydomain.com:/home/linux/others/
scp -r /home/linux/soft/ www.mydomain.com:/home/linux/others/
上面 命令 將 本地 soft 目錄 復(fù)制 到 遠(yuǎn)程 others 目錄下,即復(fù)制后遠(yuǎn)程服務(wù)器上會(huì)有/home/linux/others/soft/ 目錄。
2)從遠(yuǎn)程服務(wù)器復(fù)制到本地服務(wù)器
從遠(yuǎn)程復(fù)制到本地的scp命令與上面的命令雷同,只要將從本地復(fù)制到遠(yuǎn)程的命令后面2個(gè)參數(shù)互換順序就行了。
例如:
scp root@www.mydomain.com:/home/linux/soft/scp.zip /home/linux/others/scp.zip
scp www.mydomain.com:/home/linux/soft/ -r /home/linux/others/
linux系統(tǒng)下scp命令中很多參數(shù)都和ssh1有關(guān),還需要看到更原汁原味的參數(shù)信息,可以運(yùn)行man scp 看到更細(xì)致的英文說(shuō)明。
【編輯推薦】