













SQL Server使用索引實(shí)現(xiàn)數(shù)據(jù)訪問(wèn)優(yōu)化
一、簡(jiǎn)介
自從你和你的團(tuán)隊(duì)成功的開(kāi)發(fā)和部署了一個(gè)INTERNET網(wǎng)站,已經(jīng)過(guò)去數(shù)月了,這個(gè)網(wǎng)站在很短的時(shí)間內(nèi)吸引了數(shù)千用戶前來(lái)注冊(cè)和使用,因此你有了一個(gè)非常滿意的客戶。包括你和你的團(tuán)隊(duì)、管理層、客戶,每個(gè)人都非常高興。
生活并不總是一帆風(fēng)順的。當(dāng)站點(diǎn)的用戶開(kāi)始日均高速增長(zhǎng)的時(shí)候,問(wèn)題隨即出現(xiàn)了,客戶發(fā)來(lái)郵件開(kāi)始抱怨網(wǎng)站性能太慢,同時(shí)稱網(wǎng)站正在丟失客戶。
你開(kāi)始調(diào)查這個(gè)系統(tǒng),很快你發(fā)現(xiàn)當(dāng)系統(tǒng)訪問(wèn)或更新數(shù)據(jù)的時(shí)候,速度非常慢。打開(kāi)數(shù)據(jù)庫(kù)一看,數(shù)據(jù)庫(kù)的記錄增加的很快,有些表的記錄達(dá)到了成千上萬(wàn)行,測(cè)試團(tuán)隊(duì)在產(chǎn)品數(shù)據(jù)庫(kù)上做了一個(gè)測(cè)試,結(jié)果發(fā)現(xiàn)在測(cè)試服務(wù)器上僅2/3秒就能完成的一個(gè)處理過(guò)程,現(xiàn)在需要5分鐘。”
這個(gè)古老的故事發(fā)生在全球范圍內(nèi)的數(shù)以千計(jì)的系統(tǒng)身上。包括我在內(nèi),幾乎每個(gè)開(kāi)發(fā)人員在他或她的開(kāi)發(fā)過(guò)程中會(huì)碰到同樣的事情。我知道為什么這樣的情形會(huì)發(fā)生,同時(shí)我也知道如何去克服它。
二、閱讀范圍
請(qǐng)注意本一系列文章討論的主要的焦點(diǎn)是“事務(wù)性的SQLServer數(shù)據(jù)庫(kù)數(shù)據(jù)訪問(wèn)性能優(yōu)化”,但大部分優(yōu)化技術(shù)同樣適用于其他的數(shù)據(jù)庫(kù)。
我將要討論的優(yōu)化技術(shù)僅僅適用于軟件開(kāi)發(fā)人員。作為一個(gè)開(kāi)發(fā)者,你需要跟隨我關(guān)注的問(wèn)題,確認(rèn)你已經(jīng)作了所有能做的事情,去優(yōu)化你已經(jīng)寫(xiě)的或?qū)⒁獙?xiě)的數(shù)據(jù)訪問(wèn)代碼。數(shù)據(jù)庫(kù)管理人員(DBA)同樣在優(yōu)化和提高性能上扮演了很重要的角色,但是DBA領(lǐng)域的優(yōu)化將不屬于這篇文章討論的范圍。
三、開(kāi)始優(yōu)化一個(gè)數(shù)據(jù)庫(kù)
當(dāng)基于數(shù)據(jù)庫(kù)的應(yīng)用系統(tǒng)放慢的時(shí)候,99%的可能是系統(tǒng)的數(shù)據(jù)訪問(wèn)過(guò)程沒(méi)有優(yōu)化,或者沒(méi)有使用***的方式。所以你需要回顧和優(yōu)化你的數(shù)據(jù)訪問(wèn)/操作過(guò)程,提高系統(tǒng)的全局性能。接下來(lái)我們通過(guò)一步一步的方式開(kāi)始我們的優(yōu)化任務(wù)。
***步:在列上采用正確的索引
有些人可能爭(zhēng)論實(shí)施正確的索引是否是數(shù)據(jù)庫(kù)優(yōu)化過(guò)程的***步。但是我認(rèn)為在數(shù)據(jù)庫(kù)應(yīng)用正確的索引是***位的。原因有2點(diǎn):
1.在一個(gè)產(chǎn)品系統(tǒng)里,它將使你在很快的時(shí)間內(nèi)提高盡可能大的性能。
2.創(chuàng)建數(shù)據(jù)庫(kù)索引不需要你做任何的系統(tǒng)修改,因此不需要任何重新編譯和部署
如果你發(fā)現(xiàn)有當(dāng)前的數(shù)據(jù)庫(kù)沒(méi)有很好的處理索引,你建了索引,結(jié)果就是性能的快速提升。然而,如果索引已經(jīng)處理了,我們進(jìn)入下面的步驟。
什么是索引
我相信你已經(jīng)明白了什么是索引,但是,我仍舊看到很多人對(duì)索引不太清楚。讓我們?cè)僖淮闻靼资裁词撬饕?qǐng)看下面的小故事。
很久以前,在一個(gè)古城市里有一個(gè)很大的圖書(shū)館,里面有數(shù)以千計(jì)的圖書(shū),圖書(shū)凌亂的存放在書(shū)架上。因此,一旦有讀者向圖書(shū)員索要一本圖書(shū),圖書(shū)員除了一本一本的檢查圖書(shū),看是否匹配讀者索要的圖書(shū),其它沒(méi)有更好的辦法。發(fā)現(xiàn)一本渴望的圖書(shū)往往需要花費(fèi)圖書(shū)員數(shù)個(gè)小時(shí)。同時(shí)讀者也不得不等很長(zhǎng)的時(shí)間。
[這看起來(lái)象一個(gè)沒(méi)有主鍵的表,當(dāng)在表里進(jìn)行搜索數(shù)據(jù)的時(shí)候,數(shù)據(jù)庫(kù)引擎需要遍歷全部的數(shù)據(jù)來(lái)查找相關(guān)的記錄,所以運(yùn)行起來(lái)非常慢。]
當(dāng)讀者和圖書(shū)每天都在大量增加的時(shí)候,圖書(shū)員的工作越來(lái)越繁重。有一天,有一個(gè)智者來(lái)到圖書(shū)館,看到圖書(shū)員的繁重的工作,建議他給每一本書(shū)編號(hào),同時(shí)按順序碼放在書(shū)架上。“我可以從中得得什么好處?”圖書(shū)員問(wèn),那個(gè)智者回答到:“如果有讀者通過(guò)給你一個(gè)書(shū)號(hào)來(lái)索要圖書(shū),你很快就能發(fā)現(xiàn)在哪個(gè)書(shū)架上存放了包含該書(shū)號(hào)的圖書(shū),然后在這個(gè)書(shū)架上,你同樣能很快的找到需要的圖書(shū)”
[給書(shū)編號(hào)就象在數(shù)據(jù)表里創(chuàng)建一個(gè)主鍵,當(dāng)你在一個(gè)表里創(chuàng)建了一個(gè)主健后,系統(tǒng)就創(chuàng)建了一個(gè)聚集索引樹(shù),所有的包含記錄的數(shù)據(jù)頁(yè)按照主鍵的值在文件系統(tǒng)中進(jìn)行排序.每一個(gè)數(shù)據(jù)頁(yè)內(nèi)部也同樣按照主鍵的值進(jìn)行排序.所以,當(dāng)你向數(shù)據(jù)庫(kù)請(qǐng)求任何一個(gè)數(shù)據(jù)行的時(shí)候,首先數(shù)據(jù)庫(kù)服務(wù)器使用聚焦索引找到合適的頁(yè)(象首先發(fā)現(xiàn)書(shū)架一樣),接著在頁(yè)里查找包含主鍵值的記錄(象在書(shū)架發(fā)現(xiàn)一本書(shū))]
“這正是我所需要的”,興奮的圖書(shū)員開(kāi)始給書(shū)編號(hào),接著把它們排列在不同的書(shū)架上,他花費(fèi)了一天的時(shí)間來(lái)排序.在那天快結(jié)束的時(shí)候,他做了測(cè)試,結(jié)果發(fā)現(xiàn)幾乎不用花費(fèi)時(shí)間就能找到一本書(shū).圖書(shū)員高興極了.
[這正是你創(chuàng)建了主鍵后所發(fā)生的事情.首先,創(chuàng)建了聚焦索引,接著數(shù)據(jù)頁(yè)在物理文件里按照主鍵的值被排序.有一點(diǎn)我想你應(yīng)該很容易理解,因?yàn)閿?shù)據(jù)僅僅只能使用一列的值作為憑證來(lái)排序,所以一個(gè)表只能創(chuàng)建一個(gè)聚焦索引.就象圖書(shū)只能使用一個(gè)標(biāo)準(zhǔn)即書(shū)號(hào)來(lái)排序一樣.]
等一等,問(wèn)題還沒(méi)有被完全解決,在接下來(lái)的時(shí)間里,有個(gè)讀者沒(méi)有圖書(shū)的編號(hào),只有圖書(shū)的名字,他想通過(guò)書(shū)名索要圖書(shū),如何辦呢?可憐的圖書(shū)員只能按照從1到N來(lái)查遍所有已經(jīng)編號(hào)的圖書(shū).如果圖書(shū)存放在67號(hào)書(shū)架上,他可能需要20分鐘,相比早間圖書(shū)沒(méi)有被排序的時(shí)候,他所花費(fèi)的2-3個(gè)小時(shí).這確實(shí)有一個(gè)進(jìn)步.但是和花費(fèi)30秒通過(guò)書(shū)號(hào)查找一本書(shū)比較起來(lái),,20分鐘仍舊是一個(gè)不短的時(shí)間.還有沒(méi)有更好的辦法呢?他問(wèn)那個(gè)智者。
[假設(shè)你有一個(gè)產(chǎn)品表,如果你只有一個(gè)ProductID主鍵而沒(méi)有其它的索引,上述的情況同樣會(huì)發(fā)生,所以,當(dāng)使用產(chǎn)品名字來(lái)搜索的時(shí)候,數(shù)據(jù)引擎只能遍歷文件里所有物理排序的數(shù)據(jù)頁(yè),沒(méi)有其它的辦法.]
那個(gè)智者告訴圖書(shū)員:因?yàn)槟阋呀?jīng)按照書(shū)號(hào)對(duì)圖書(shū)做了排序,你不能使用其它的憑證重新排序,所以,較好的方法是創(chuàng)建一個(gè)包含書(shū)名和與之對(duì)應(yīng)的編號(hào)的目錄或索引,在這個(gè)目錄上,按照?qǐng)D書(shū)的字母順序排序,并使用阿拉伯字母進(jìn)行分組,例如,當(dāng)有人想查找DatabaseManagementSystem這本書(shū)的時(shí)候,你使用下列的規(guī)則就能發(fā)現(xiàn)這本書(shū)
1.在書(shū)名目錄里跳到D章,找到包含你的書(shū)名的圖書(shū).
2.得到這本書(shū)的書(shū)號(hào),然后用書(shū)號(hào)去查找這本書(shū)
“你真是一個(gè)天才”,圖書(shū)員喊到,他立即花費(fèi)了一些時(shí)間創(chuàng)建了書(shū)名的目錄,通過(guò)一個(gè)快速的測(cè)試,他發(fā)現(xiàn)使用書(shū)名來(lái)查詢僅僅需要1分鐘,其中30秒查找書(shū)的編號(hào),30秒用編號(hào)來(lái)找書(shū).
圖書(shū)員想到,讀者還可能使用其它的憑證來(lái)查找圖書(shū),例如作者的名字,所以他為作者創(chuàng)建了同樣的目錄.在創(chuàng)建了這些目錄后,圖書(shū)員可以使用這些憑證在1分鐘內(nèi)找到圖書(shū).圖書(shū)員的繁重的工作終于結(jié)束了,許多讀者也因?yàn)楹芸斓牟檎业綀D書(shū)而聚集在圖書(shū)館,圖書(shū)館變的非常熱鬧起來(lái).
圖書(shū)員隨后開(kāi)始過(guò)著他的快樂(lè)的生活,故事結(jié)束了.
到這里,現(xiàn)在我確信你已經(jīng)明白了什么是索引,為什么它們?nèi)绱酥匾约八鼈兊膬?nèi)部工作原理,,例如,我們有一個(gè)已創(chuàng)建聚焦索引的產(chǎn)品表Products,因?yàn)楫?dāng)創(chuàng)建了主鍵的時(shí)候,隨即就創(chuàng)建了聚焦索引。我門(mén)應(yīng)當(dāng)在Productname列創(chuàng)建一個(gè)非聚焦索引,一旦我們這樣作了,數(shù)據(jù)庫(kù)引擎就為非聚焦索引創(chuàng)建一個(gè)索引樹(shù),象故事里的書(shū)名目錄,按照產(chǎn)品的名字在索引頁(yè)里排序。每個(gè)索引頁(yè)包含一定范圍的產(chǎn)品名字和與之對(duì)應(yīng)的ProductID,所以當(dāng)使用產(chǎn)品名字作為憑證搜索的時(shí)候,數(shù)據(jù)庫(kù)引擎首先查詢產(chǎn)品名字的非聚焦索引樹(shù)來(lái)發(fā)現(xiàn)這本書(shū)的主鍵productID,一旦發(fā)現(xiàn),數(shù)據(jù)庫(kù)引擎就使用主鍵ProductID來(lái)搜索聚焦索引樹(shù),從而并得到正確的結(jié)果。
索引樹(shù)的工作原理如下圖:
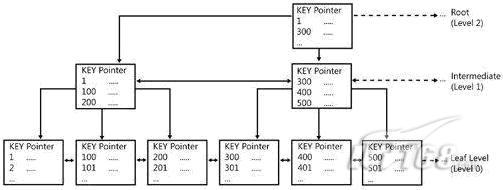
上圖被稱做為B+樹(shù),中間的節(jié)點(diǎn)包含一定數(shù)量的值,指示數(shù)據(jù)庫(kù)引擎當(dāng)從跟節(jié)點(diǎn)搜索一個(gè)索引值的時(shí)候如何遍歷.如果這是一個(gè)聚焦索引樹(shù),頁(yè)節(jié)點(diǎn)是物理數(shù)據(jù)頁(yè).如果是非聚焦索引樹(shù),頁(yè)節(jié)點(diǎn)包含包含索引值和與之對(duì)應(yīng)的聚焦索引值.
通常,在索引樹(shù)里發(fā)現(xiàn)需要的值并且轉(zhuǎn)到目標(biāo)數(shù)據(jù)記錄,對(duì)于數(shù)據(jù)庫(kù)引擎來(lái)說(shuō)花費(fèi)的時(shí)間是很短的,所以,在數(shù)據(jù)庫(kù)應(yīng)用索引極大的提高了數(shù)據(jù)的檢索操作.
請(qǐng)跟隨下列的步驟確保正確的索引包含在你的數(shù)據(jù)庫(kù)里。
確保數(shù)據(jù)庫(kù)的每個(gè)表有一個(gè)主健
這么做會(huì)確保每個(gè)表有一個(gè)聚焦索引,通過(guò)主健的值,表的數(shù)據(jù)頁(yè)通按物理順序排列在磁盤(pán)上。所以,任何使用主健的數(shù)據(jù)檢索操作,任何在主健字段的排序操作都能非常迅速的檢索數(shù)據(jù)。
在這些列上創(chuàng)建非聚焦索引
經(jīng)常被作為搜索憑證的列
用來(lái)聯(lián)合其它表的列
用來(lái)作為外健的列
用來(lái)排序的列
高選擇性列
Xml類(lèi)型
下面是一個(gè)創(chuàng)建索引的命令的例子
CREATEINDEX |
你也可以使用SQL Server控制臺(tái)在需要的列上創(chuàng)建索引
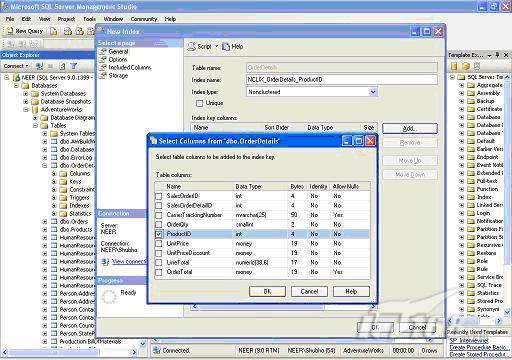
第二步:創(chuàng)建正確的復(fù)合索引
現(xiàn)在,你是否已經(jīng)在數(shù)據(jù)庫(kù)創(chuàng)建了所有的適合的索引?假設(shè),在一個(gè)Sales表(SelesID,SalesDate,SalesPersonID,ProductID,Qty),你已經(jīng)在外鍵(ProductID)創(chuàng)建了索引,如果ProductID是一個(gè)高選擇性列,任何在where語(yǔ)句里使用索引列(ProductID)的檢索數(shù)據(jù)的SELECT查詢都會(huì)運(yùn)行的非常快嗎?
對(duì),相對(duì)沒(méi)有在外鍵創(chuàng)建索引的情況(這需要全部數(shù)據(jù)頁(yè)的遍歷)來(lái)說(shuō),這是非常快的,但是,還有進(jìn)一步提升的空間.
讓我們假設(shè):Sales表包含10,000行數(shù)據(jù),下面的SQL語(yǔ)句選擇400行。
SELECTSalesDate,SalesPersonIDFROMSalesWHEREProductID=112 |
首先讓我們弄明白在數(shù)據(jù)庫(kù)引擎怎么執(zhí)行SQL語(yǔ)句的:
1.Sales表有在ProductID列一個(gè)非聚焦索引,所以,首先查詢非聚焦索引樹(shù),發(fā)現(xiàn)包含ProductID=112的入口。
2.包含ProductID=112入口的索引頁(yè)同樣同樣也包含了聚焦索引的值(所有的主健的值,即SalesID)
3.對(duì)于每一個(gè)主健(共400個(gè)),數(shù)據(jù)庫(kù)引擎進(jìn)入聚焦索引樹(shù)來(lái)發(fā)現(xiàn)正確的行的位置
4.對(duì)于每一個(gè)主健,一旦發(fā)現(xiàn)正確的行的位置,數(shù)據(jù)庫(kù)引擎會(huì)從匹配的行得到SalesDate和SalesPersonID的列的值。
請(qǐng)注意,在上述的步驟中,對(duì)于每一個(gè)ProductID=112的主鍵入口(共400個(gè)),數(shù)據(jù)庫(kù)引擎必須搜索聚焦索引樹(shù)400次,來(lái)檢索附加的列(SalesDate,SalesPersonID)。
讓我們猜想一下,如果非聚焦索引不但包含了聚焦索引的值(主健),同時(shí)還包含查詢里標(biāo)注的其他的2個(gè)列(SalesDate,SalesPersonID)的值,數(shù)據(jù)庫(kù)引擎就不用執(zhí)行上述的第3步和第4步,只須進(jìn)入ProductID的列的非聚焦索引樹(shù),從索引頁(yè)上讀取3個(gè)列的值,這樣運(yùn)行的速度不是更快嗎?
幸運(yùn)的是,有一種辦法來(lái)實(shí)施這種特點(diǎn),這就是復(fù)合索引。你可以在表的列上創(chuàng)建復(fù)合索引,標(biāo)明哪些列是和聚焦索引一起的應(yīng)該附加存儲(chǔ)的列。下面是一個(gè)在表Sales表的列ProductID創(chuàng)建復(fù)合索引的例子。
CREATEINDEXNCLIX_Sales_ProductID--Indexname |
請(qǐng)注意,創(chuàng)建復(fù)合索引應(yīng)當(dāng)包含少數(shù)幾個(gè)列,并且這些列經(jīng)常在select查詢里使用。在復(fù)合索引里包含太多的列不僅不會(huì)給你帶來(lái)太多好處。而且由于使用相當(dāng)多的內(nèi)存來(lái)存儲(chǔ)復(fù)合索引的列的值,其后果是內(nèi)存溢出和性能降低。
當(dāng)創(chuàng)建復(fù)合索引的時(shí)候,盡量使用DatabaseTuningAdvisor(數(shù)據(jù)庫(kù)優(yōu)化顧問(wèn))的幫助。
我們知道,一旦一個(gè)SQL開(kāi)始運(yùn)行,SQLSERVER引擎優(yōu)化器基于以下幾點(diǎn)動(dòng)態(tài)的產(chǎn)生不同的檢索計(jì)劃。
數(shù)據(jù)量
統(tǒng)計(jì)
索引變化
TSQL的參數(shù)值
服務(wù)器的負(fù)載
這意味著:對(duì)于一個(gè)特殊的SQL語(yǔ)句,在產(chǎn)品服務(wù)器上的執(zhí)行計(jì)劃可能和在測(cè)試服務(wù)器上的執(zhí)行計(jì)劃不近相同,甚至表和索引結(jié)構(gòu)一樣。這同樣也表明,一個(gè)在測(cè)試服務(wù)器上創(chuàng)建的索引可能會(huì)加速測(cè)試服務(wù)器上的性能,但是在產(chǎn)品服務(wù)器上的同樣的索引可能不會(huì)帶給你任何益處。為什么?因?yàn)樵跍y(cè)試環(huán)境下的SQLSEVVER執(zhí)行計(jì)劃可能使用創(chuàng)建的索引,因此給你很好的性能,但是,在產(chǎn)品服務(wù)器上的執(zhí)行計(jì)劃可能出于下列的原因而根本不使用新創(chuàng)建的索引。例如:一個(gè)非聚焦索引列在產(chǎn)品服務(wù)器上不是高選擇性列,而在測(cè)試服務(wù)器上是高選擇性列.
所以,當(dāng)創(chuàng)建索引的時(shí)候,我們需要弄明白這一點(diǎn):索引是執(zhí)行引擎用來(lái)提高速度的。但是我們?cè)撊绾稳プ瞿?
答案是我們必須在測(cè)試服務(wù)器上模擬產(chǎn)品服務(wù)器的負(fù)載,接著創(chuàng)建索引,以及測(cè)試他們。只有這樣,在測(cè)試服務(wù)器上能提高性能的索引,才能更有可能在產(chǎn)品服務(wù)器上提高性能。
這么做應(yīng)該很困難,但幸運(yùn)的是,我們有一些好用的工具去實(shí)現(xiàn)它,請(qǐng)跟隨下面的指導(dǎo):
1:使用SQLprofiler捕獲產(chǎn)品服務(wù)器上的痕跡。使用Tuningtemplate(我知道,有人建議不要在產(chǎn)品服務(wù)器上使用SQLprofiler,但有些時(shí)候,你不得不在產(chǎn)品服務(wù)器上診斷性能問(wèn)題的時(shí)候使用它),如果你不熟悉這個(gè)工具,或者你想了解更多的關(guān)于SQLprofiler的知識(shí),請(qǐng)閱讀http://msdn.microsoft.com/en-us/library/ms181091.aspx
2.利用上一步產(chǎn)生的跟蹤文件,用數(shù)據(jù)庫(kù)優(yōu)化顧問(wèn)在測(cè)試數(shù)據(jù)庫(kù)創(chuàng)建相似的負(fù)載,從優(yōu)化顧問(wèn)得到一些建議,特別是創(chuàng)建索引的建議,你很可能從優(yōu)化顧問(wèn)那里獲得比較實(shí)際的建議。因?yàn)閮?yōu)化顧問(wèn)使用產(chǎn)品服務(wù)器產(chǎn)生的跟蹤文件來(lái)裝載測(cè)試服務(wù)器,所以能產(chǎn)生最可能好的索引建議。如果你不熟悉優(yōu)化顧問(wèn)工具,或者你想了解更多的關(guān)于使用優(yōu)化顧問(wèn)的的資料,請(qǐng)閱讀:http://msdn.microsoft.com/en-us/library/ms166575.aspx.
第三步:如果有碎片發(fā)生,重新整理它
到了這里,如果你已經(jīng)在表里創(chuàng)建了所有正確的索引,但是,你可能還沒(méi)有獲得所希望的良好的性能。什么原因呢?有一種可能是出現(xiàn)了索引碎片。
1、什么是索引碎片
索引碎片是這樣一種情形:由于在表里大量的插入、修改、刪除操作而使索引頁(yè)分裂。如果索引有了高的碎片,有兩種情況,一種情況是掃描索引需要花費(fèi)很多的時(shí)間,另一種情況是在查詢的時(shí)候索引根本不使用索引,都會(huì)導(dǎo)致性能降低。
有2種類(lèi)型的碎片:
內(nèi)部破碎:由于索引頁(yè)里的數(shù)據(jù)插入或修改操作而發(fā)生,以數(shù)據(jù)作為稀疏矩陣的形式的分布而結(jié)束,這將導(dǎo)致數(shù)據(jù)頁(yè)的增加,從而增加查詢時(shí)間。
外部破碎:由于索引/數(shù)據(jù)頁(yè)的數(shù)據(jù)插入或修改而發(fā)生,以頁(yè)碼分離和在文件系統(tǒng)里不連貫的新的索引頁(yè)的分配而結(jié)束,數(shù)據(jù)庫(kù)服務(wù)器不能利用預(yù)讀操作的優(yōu)點(diǎn),因?yàn)椋合乱粋€(gè)相關(guān)聯(lián)的數(shù)據(jù)頁(yè)不臨近,而且這些相關(guān)連的下面的頁(yè)碼可能在數(shù)據(jù)文件的任何地方。
2、如何知道索引破碎是否已經(jīng)發(fā)生?
在數(shù)據(jù)庫(kù)執(zhí)行下面的SQL語(yǔ)句(下面的語(yǔ)句在SQLserver2005及以后的版本運(yùn)行正常,以你的目標(biāo)數(shù)據(jù)庫(kù)的名字取代AdventureWorks’)
SELECTobject_name(dt.object_id)Tablename,si.name |
上面的查詢顯示的AdventureWorks’數(shù)據(jù)庫(kù)的索引碎片信息如下:
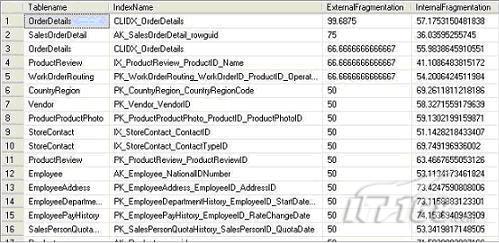
分析上面的結(jié)果,你就能發(fā)現(xiàn)在哪里出現(xiàn)了索引碎片,應(yīng)用下面的規(guī)則:
ExternalFragmentation的值>10,預(yù)示對(duì)應(yīng)的索引出現(xiàn)外部碎片。InternalFragmentation的值<75,預(yù)示對(duì)應(yīng)的索引出現(xiàn)內(nèi)部碎片
3、怎樣重新整理索引碎片
有2種方式:
索引重組:執(zhí)行下面的命令:
ALTERINDEXALLONTableNameRECOGNIZE |
索引重建:
ALTERINDEXALLONTableNameREBUILDWITH(FILLFACTOR=90,ONLINE=ON) |
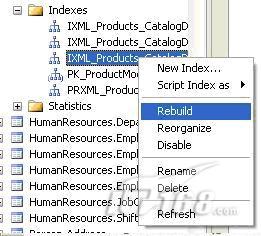
通過(guò)使用具體索引的名字代替ALL,你能重組或重建單個(gè)的索引。你也可以使用數(shù)據(jù)庫(kù)控制臺(tái)來(lái)重建/重組索引
4、什么時(shí)候重組和重建索引?
當(dāng)外部碎片的值在10-15,內(nèi)部碎片的值在60-75,對(duì)于這樣的索引,你應(yīng)該重組索引。否則,你應(yīng)該重建索引。
關(guān)于索引重建的一個(gè)重要的事情是:一旦在一個(gè)特定的表上重建索引,表就會(huì)被鎖定(重組的時(shí)候不會(huì)發(fā)生)。所以,對(duì)于一個(gè)產(chǎn)品數(shù)據(jù)庫(kù)的一個(gè)大的表,因?yàn)樵谝粋€(gè)大表上的索引重建往往需要花費(fèi)數(shù)個(gè)小時(shí),我們不希望這種鎖定。幸運(yùn)的是,在SQL2005有一個(gè)解決方法,你可以在重建一個(gè)表的索引的時(shí)候,把ONLINE選項(xiàng)的值設(shè)為ON,這樣會(huì)使重建索引和表上的數(shù)據(jù)事務(wù)同樣進(jìn)行。
四、實(shí)現(xiàn)數(shù)據(jù)訪問(wèn)結(jié)束語(yǔ)
在數(shù)據(jù)表里的所有適合創(chuàng)建索引的字段上創(chuàng)建索引,這是非常誘惑人的。但是如果你正在從事一個(gè)事務(wù)數(shù)據(jù)庫(kù)工作,在每個(gè)字段上創(chuàng)建索引并不是每次都是需要的。事實(shí)上,在一個(gè)OLTP系統(tǒng)上創(chuàng)建大量的索引可能會(huì)降低數(shù)據(jù)庫(kù)的性能。(因?yàn)楫?dāng)很多操作是更新操作的時(shí)候,更新數(shù)據(jù)意味著更新索引)
一個(gè)首要的規(guī)則建議如下:
如果你在從事一個(gè)事務(wù)性數(shù)據(jù)庫(kù),平均不要在一個(gè)表上創(chuàng)建超過(guò)5個(gè)索引,另外,如果你在從事數(shù)據(jù)倉(cāng)庫(kù),平均最高可在一個(gè)表上創(chuàng)建10個(gè)索引。
【編輯推薦】
- 淺談如何在SQL Server中生成腳本
- SQL Server 2000中的數(shù)據(jù)同步問(wèn)題
- SQL Server 05數(shù)據(jù)庫(kù)被置為“可疑”的解決方法
- 詳解SQL Server的版本區(qū)別及選擇
- SQL Server即將提升實(shí)時(shí)數(shù)據(jù)功能
【責(zé)任編輯:彭凡 Tel:(010)68576606-8058










